







如何管理kafka消费偏移量:
一、 kafka消息的位置至关重要,维护其消息偏移量对于避免消息的重复消费与遗漏消费,确保消息的Exactly-once。
kafka的消息所在的位置Topic、Partitions、Offsets三个因素决定。
Kafka消费者消费的消息位置还与consumer的group.id有关。
二、consumerOffsets与earlieastLeaderOffsets的关系
earlieastLeaderOffsets :存储在broker上的leader节点的最早的消息偏移量
consumerOffsets :消费者消费的消息偏移量位置
为了表述方便,我们记earlieastLeaderOffsets为A,记consumerOffsets为B 。
情况一:正常情况下,消费的消息偏移量应该大于broker上存储的最早的消息偏移量,即 A < B:
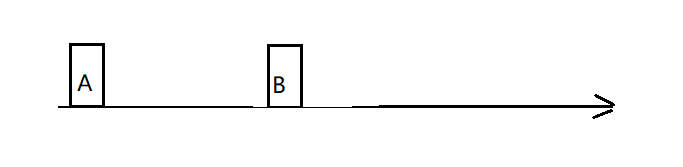
我们知道,存储在broker上的kafka的消息常设置消息过期配置,当到达过期时间时过期的消息将会被清除。
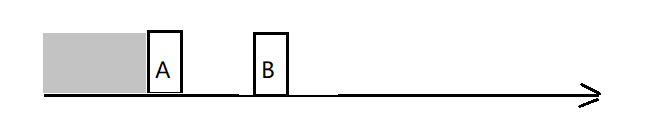
情况二:如果A 依然小于 B,则仍可以正常消费:
情况三:然而,当 A > B 时,则说明还没有被消费的消息已经被清除:
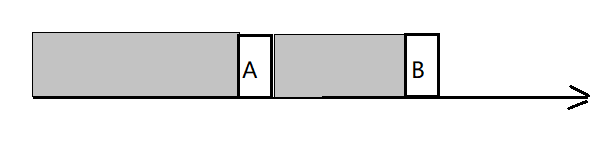
此种情况会抛出 kafka.common.OffsetOutOfRangeException 异常。
consumerOffsets 小于 earlieastLeaderOffsets的影响与解决办法
当情况三发生时,在(B,A)区间内的消息还没有被消费就已经被清除了,将导致两个后果。
- 消息丢失。
- 抛出 kafka.common.OffsetOutOfRangeException 异常。
在对消息完整性有严格要求的系统中,消息的丢失造成的影响会比较严重,所以在这种情况下,要保证消息不会遭到丢失。
避免消息丢失包含两个方面:
1、还没有被消费过的消息不会被清除。
在没有外部系统清除kafka消息的情况下,协调设置broker的最大保留大小 log.retention.bytes 和 最大保留时间log.retention.hours 等,来配合消费者端的读取消息。可以通过读取和监控消费者消费的offsets,来保证消息不会被意外清除。
2、 消费者端消费消息没有遗漏。
当消费者意外中断时,重新启动消费时能够从上一次中断的消息偏移量开始消费。
三、如何维护
在从kafka接受流式数据的时候,spark提供了两种方式,Dstream和DirectStream,在spark2.2中已经不在提供第一种方式,具体区别这儿就不再描述了,第二种方式spark是用的kafka低阶api,每个RDD对应一个topic的分区,这种情况,需要借助于外部存储来管理offset,或者简单点,自己手动利用kafka来管理offset,否则在程序重启时找不到offset从最新的开始消费,会有丢失数据的情况。一般步骤如下:
(1)在 Direct DStream初始化的时候,需要指定一个包含每个topic的每个分区的offset用于让Direct DStream从指定位置读取数据。
(2)读取并处理消息
(3)处理完之后存储结果数据
(4)最后,将offsets保存在外部持久化数据库如 HBase, Kafka, HDFS, and ZooKeeper中
四、具体实现
- 方法一:kafka管理offset
Apache Spark 2.1.x以及spark-streaming-kafka-0-10使用新的的消费者API即异步提交API。你可以在你确保你处理后的数据已经妥善保存之后使用commitAsync API(异步提交 API)来向Kafka提交offsets。新的消费者API会以消费者组id作为唯一标识来提交offsets,将offsets提交到Kafka中。目前这还是实验性特性。
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
- 方法二:zookeeper管理offset
在初始化 kafka stream 的时候,查看 zookeeper 中是否保存有 offset,有就从该 offset 进行读取,没有就从最新/旧进行读取。在消费 kafka 数据的同时,将每个 partition 的 offset 保存到 zookeeper 中进行备份
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark-streaming")
val ssc = new StreamingContext(sparkConf, Seconds(10))
val topic: String = "test"
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "master:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark-streaming-group01",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
var kafkaStream: InputDStream[ConsumerRecord[String, String]] = null
val zkClient = new ZkClient("master")
var fromOffsets: Map[TopicPartition, Long] = Map()
val children = zkClient.countChildren("offsetDir")
if (children > 0) {
for (i <- 0 until children) {
val partitionOffset = zkClient.readData[String]("offsetDir" + "/" + i)
val tp = new TopicPartition(topic, i)
fromOffsets += (tp -> partitionOffset.toLong)
kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc, PreferConsistent, Subscribe[String, String](Set(topic), kafkaParams, fromOffsets)
)
}
} else {
kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc, PreferConsistent, Subscribe[String, String](Set(topic), kafkaParams)
)
}
上述方法二在streaming程序停止太长时间重启,kafka消息过期(设置),会造成消息丢失,部分消息没消费就被清除了,避免这种情况,所以每次重启后要拿kafka最小的offset和zookeeper里的offset比较一下。
import kafka.api.{OffsetRequest, PartitionOffsetRequestInfo, TopicMetadataRequest}
import kafka.common.TopicAndPartition
import kafka.consumer.SimpleConsumer
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.I0Itec.zkclient.exception.ZkMarshallingError
import org.I0Itec.zkclient.serialize.ZkSerializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by grant on 2018/8/6.
* * 并行度:
* 1、linesDStram里面封装到的是RDD, RDD里面有partition与读取topic的parititon数是一致的。
* 2、从kafka中读来的数据封装一个DStream里面,可以对这个DStream重分区 reaprtitions(numpartition
*/
object WithOffset2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StreamingDemoWithOffset2").setMaster("local[2]")
//val DIR = "E:\\BigData\\IDEA_pro\\Learn\\resource\\"
/**
* 可以不设置checkpoint,因为内存中也有一份偏移量offset
* 设置后如果停止程序,可以从checkpoint中读出来
*/
val ssc = new StreamingContext(conf,batchDuration = Seconds(5))
/**
* topic and brokers
*/
val topic = "user_events"
val topics = Set(topic)//创建 stream 时使用的 topic 名字集合
val brokers = "master:9092,worker1:9092,worker2:9092"
/**
* kafka查询参数
*/
var kafkaParams = Map[String,String]()
/**
* Map默认是immutable包下的 定义时定义成var 使用+= ->添加元素
*/
kafkaParams +=("auto.offset.reset" -> "smallest")
kafkaParams +=("metadata.broker.list" -> brokers)
kafkaParams +=("serializer.class" -> "kafka.serializer.StringEncoder")
/**
* 创建direct stream
* String,String,StringDecoder,StringDecoder
* key和value的编码格式和解码格式
*/
val stream = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
/**
* kafkaStream这个tuple的第二部分为接受kafka topic里的文本流
*/
//创建一个 ZKGroupTopicDirs 对象,对保存
val topicDirs = new ZKGroupTopicDirs("test_spark_streaming_group", topic)
//获取 zookeeper 中的路径,这里会变成 /consumers/test_spark_streaming_group/offsets/topic_name
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//zookeeper 的host 和 ip,创建一个 client
//创建ZKClient,API有好几个,最后用带序列化参数的,不然保存offset的时候容易出现乱码。
val zkClient = new ZkClient("master:2181",60000,60000,new ZkSerializer {
override def serialize(data: Object): Array[Byte] = {
try {
return data.toString.getBytes("UTF-8")
}catch {
case e: ZkMarshallingError => return null
}
}
override def deserialize(bytes: Array[Byte]): AnyRef = {
try {
return new String(bytes,"UTF-8")
}catch {
case e: ZkMarshallingError => return null
}
}
})
/**
* 保存偏移量至zookeeper
* @param zkTopicPath
* @param rdd
*/
def saveOffset(zkTopicPath: String, rdd: RDD[(String, String)]) = {
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for(o <- offsetRanges){
ZkUtils.updatePersistentPath(zkClient,s"${zkTopicPath}/${o.partition}",String.valueOf(o.untilOffset))
}
}
//查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的)
//查看该groupId在该topic下是否有消费记录,如果有,肯定在对应目录下会有分区数,children大于0则有记录。
val children = zkClient.countChildren(s"${topicDirs.consumerOffsetDir}")
var kafkaStream : InputDStream[(String, String)] = null
var fromOffsets: Map[TopicAndPartition, Long] = Map() //如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置
//在有记录的情况下,去拿具体的offset
if(children > 0) {
var fromOffsets: Map[TopicAndPartition, Long] = Map()
//---get partition leader begin---
val topicList = List(topic)
val req = new TopicMetadataRequest(topicList, 0)
//得到topic的一些信息,比如broker,partition分布情况
val getLeaderConsumer = new SimpleConsumer("master", 9092, 10000, 10000, "OffsetLookup")
//brokerList的host、brokerList的port、过期时间、过期时间
val res = getLeaderConsumer.send(req)
//TopicMetadataRequest topic broker partition 的一些信息
val topicMetaOption = res.topicsMetadata.headOption
val partitions = topicMetaOption match {
case Some(tm) => {
tm.partitionsMetadata.map(pm => (pm.partitionId, pm.leader.get.host)).toMap[Int, String]
}
case None => Map[Int, String]()
}
for (i <- 0 until children) {
val partitionOffset = zkClient.readData[String](s"${topicDirs.consumerOffsetDir}/${i}")
val tp = TopicAndPartition(topic, i)
//---additional begin---
val requestMin = OffsetRequest(Map(tp -> PartitionOffsetRequestInfo(OffsetRequest.EarliestTime, 1)))
// -2,1
val consumerMin = new SimpleConsumer(partitions(i), 9092, 10000, 10000, "getMinOffset")
val curOffsets = consumerMin.getOffsetsBefore(requestMin).partitionErrorAndOffsets(tp).offsets
var nextOffset = partitionOffset.toLong
//在zookeeper里存储的offset有可能在kafka里过期了,所以要拿kafka最小的offset和zookeeper里的offset比较一下。
if (curOffsets.length > 0 && nextOffset < curOffsets.head) {
//如果下一个offset小于当前的offset,就把当前kafka里的偏移量更新至zookeeper
nextOffset = curOffsets.head
}
//---additional end
//将不同partition对应的offset增加到fromOffset中
fromOffsets += (tp -> nextOffset)
//当前topic的若干分区的偏移量
println("------ topic[" + topic + "] partition[" + i + "] offset[" + partitionOffset + "] ------")
}
//这个会将 kafka 的消息进行 transform,最终 kafka 的数据都会变成 (topic_name, message) 这样的 tuple
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.topic, mmd.message())
//接下来就可以创建Kafka Direct DStream了,前者是从zookeeper拿的offset,后者是直接从最新的开始(第一次消费)。
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
}else{
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc,kafkaParams,topics)
}
kafkaStream.foreachRDD{rdd =>
if(!rdd.isEmpty()){
//doSomething
rdd.foreachPartition(message =>{
while (message.hasNext){
println(s"@^_^@ [" + message.next() + "] @^_^@")
}
})
saveOffset(zkTopicPath,rdd)
}
}
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
上述方法三即可应对消息过期等问题。














 2033
2033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









