






为什么使用MyBatis
在Java程序中去连接数据库,最原始的办法是使用JDBC的API。我们先来回顾一下使用JDBC的方式,我们是如何操作数据库的。
Connection conn = null;
Statement stmt = null;
Blog blog = new Blog();
try {
// 注册 JDBC 驱动
Class.forName("com.mysql.jdbc.Driver");
// 打开连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis", "root", "123456");
// 执行查询
stmt = conn.createStatement();
String sql = "SELECT bid, name, author_id FROM blog";
ResultSet rs = stmt.executeQuery(sql);
// 获取结果集
while (rs.next()) {
Integer bid = rs.getInt("bid");
String name = rs.getString("name");
Integer authorId = rs.getInt("author_id");
blog.setAuthorId(authorId);
blog.setBid(bid);
blog.setName(name);
}
System.out.println(blog);
rs.close();
stmt.close();
conn.close();
} catch (SQLException se) {
se.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (stmt != null) stmt.close();
} catch (SQLException se2) {
}
try {
if (conn != null) conn.close();
} catch (SQLException se) {
se.printStackTrace();
}
}
}
首先,我们在pom.xml中添加MySQL驱动的依赖。
第一步,注册驱动
第二步,通过DriverManager获取一个connection,参数中是数据库连接地址,用户名和密码
第三步,通过connection创建一个Statement对象
第四步,通过statement的execute方法执行SQL,返回结果集。当然Statement中提供了很多的方法。
第五步,通过ResultSet获取数据,转换成一个POJO对象
最后,我们要关闭数据库的相关资源,包括ResultSet、Statement、Connection,他们的关闭顺序和打开的顺序正好相反
上面就是我们用过JDBC的API去操作数据库的方法,但是这仅仅是一个非常简单的查询的方法。如果我们的项目中的业务比较复杂,表也比较多,各种对数据库的增删改查的方法也比较多的话,这样的代码会重复很多次,维护起来也非常的痛苦。主要体现在下面几点:
- 在每一段这样的代码里面,我们都要自己去管理数据库的连接资源,如果忘记close,就可能造成数据库服务连接耗尽。
- 处理业务逻辑和处理数据的代码耦合在一起。如果业务流程复杂,和数据库交互次数较多,耦合在代码中的SQL就会非常多。如果要修改业务逻辑,或者修改数据库环境(因为不同数据库的语法可能不同),这个会非常麻烦,工作量也很难去估计。
- 处理结果集的时候,我们要把ResultSet转化成POJO对象,必须根据字段属性的类型一个一个的去处理,写这样的代码非常的枯燥。
正因为上述几点原因,我们在实际工作中是很少直接使用JDBC的,那在Java程序中有哪些更加简单的操作数据库的方式呢?
1、 Apache DBUtils: 官网.
DBUtils解决的最核心的问题就是结果集的映射,可以把ResultSet封装成JavaBean,它是怎么实现的那?
首先,DBUtils提供了一个QueryRunner类,它对数据库的增删改查的方法进行了封装,那么我们操作的数据库就可以直接使用它提供的方法。
在QueryRunner的构造方法中,我们又可以传入一个数据源,这样我们就不需要再去写各种创建和释放连接的代码了。
queryRunner = new QueryRunner(dataSource);
那么怎么把结果集转换成对象呢?比如实体类Bean或者List或者Map? 在DBUtils里面提供了一系列的支持泛型的ResultSetHandler。
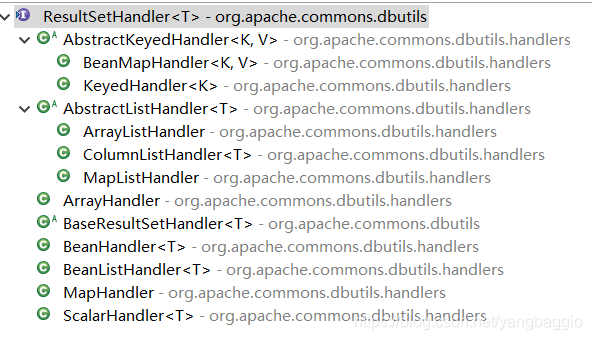
我们只需要在DAO层调用QueryRunner的查询方法,传入这个handler,它就可以自动把结果集转换成实体Bean
String sql = "select * from blog where bid = ? ";
Object[] params = new Object[]{bid};
BlogDto blogDto = queryRunner.query(sql, new BeanHandler<>(BlogDto.class), params);
没用过DBUtils的同学可以思考一下,通过结果集到实体类的映射是怎么实现的?
也就是说,我只传了一个实体类的类型,它怎么知道这个类型有哪些属性,每个属性是什么类型?然后创建这个对象并给这些字段赋值的?答案是通过反射实现。
需要注意的是,DBUtils中要求数据库字段和对象的属性名完全一致,才可以实现自动转化。
2、 Spring JDBC
除了DBUtils之外,Spring也对原生的JDBC做了封装,并且提供了一个模板方法JdbcTemplate,来简化我们对数据库的操作。
首先,我们不需要关心资源管理的问题。其次,对于结果集的处理,Spring JDBC提供了一个RowMapper接口,可以把结果集转换成Java对象。
看下面代码: 比如我们要把结果集转换成Employee对象,就可以针对Employee创建一个RowMapper对象,实现RowMapper接口,并且重写mapRow方法。我们在mapRow中完成对结果集到Java对象的转换。
public class EmployeeRowMapper implements RowMapper {
@Override
public Object mapRow(ResultSet resultSet, int i) throws SQLException {
Employee employee = new Employee();
employee.setEmpId(resultSet.getInt("emp_id"));
employee.setEmpName(resultSet.getString("emp_name"));
employee.setGender(resultSet.getString("gender"));
employee.setEmail(resultSet.getString("email"));
return employee;
}
}
在DAO层调用的时候就可以传入自定义的RowMapper类,最终返回我们所需要的类型,结果集和实体类型的映射也是自动完成的。
public List<Employee> query(String sql) {
new JdbcTemplate( new DruidDataSource());
return jdbcTemplate.query(sql,new EmployeeRowMapper());
}
通过这种方式,我们对结果集的处理只需要写一次代码,然后在每个需要映射的地方传入这个RowMapper就可以了,可以减少很多重复的代码。
但是这种方式还是有个问题:每一个实体类都要有对应的RowMapper,然后要对每一个RowMapper编写getInt、getString这样的代码,还增加了类的数量。
那有没有办法实现结果集和实体类的字段自动映射呢?这样,我们要解决两个问题,一个是名称的对应问题,另外一个是字段类型对应的的问题。
我们可以创建一个BaseRowMapper类,通过反射的方式自动获取所有属性,把表字段全部复制到属性。
public class BaseRowMapper<T> implements RowMapper<T> {
private Class<?> targetClazz;
private HashMap<String, Field> fieldMap;
public BaseRowMapper(Class<?> targetClazz) {
this.targetClazz = targetClazz;
fieldMap = new HashMap<>();
Field[] fields = targetClazz.getDeclaredFields();
for (Field field : fields) {
fieldMap.put(field.getName(), field);
}
}
@Override
public T mapRow(ResultSet rs, int arg1) throws SQLException {
T obj = null;
try {
obj = (T) targetClazz.newInstance();
final ResultSetMetaData metaData = rs.getMetaData();
int columnLength = metaData.getColumnCount();
String columnName = null;
for (int i = 1; i <= columnLength; i++) {
columnName = metaData.getColumnName(i);
Class fieldClazz = fieldMap.get(camel(columnName)).getType();
Field field = fieldMap.get(camel(columnName));
field.setAccessible(true);
// fieldClazz == Character.class || fieldClazz == char.class
if (fieldClazz == int.class || fieldClazz == Integer.class) { // int
field.set(obj, rs.getInt(columnName));
} else if (fieldClazz == boolean.class || fieldClazz == Boolean.class) { // boolean
field.set(obj, rs.getBoolean(columnName));
} else if (fieldClazz == String.class) { // string
field.set(obj, rs.getString(columnName));
} else if (fieldClazz == float.class) { // float
field.set(obj, rs.getFloat(columnName));
} else if (fieldClazz == double.class || fieldClazz == Double.class) { // double
field.set(obj, rs.getDouble(columnName));
} else if (fieldClazz == BigDecimal.class) { // bigdecimal
field.set(obj, rs.getBigDecimal(columnName));
} else if (fieldClazz == short.class || fieldClazz == Short.class) { // short
field.set(obj, rs.getShort(columnName));
} else if (fieldClazz == Date.class) { // date
field.set(obj, rs.getDate(columnName));
} else if (fieldClazz == Timestamp.class) { // timestamp
field.set(obj, rs.getTimestamp(columnName));
} else if (fieldClazz == Long.class || fieldClazz == long.class) { // long
field.set(obj, rs.getLong(columnName));
}
field.setAccessible(false);
}
} catch (Exception e) {
e.printStackTrace();
}
return obj;
}
/**
* 下划线转驼峰
* @param str
* @return
*/
public static String camel(String str) {
Pattern pattern = Pattern.compile("_(\\w)");
Matcher matcher = pattern.matcher(str);
StringBuffer sb = new StringBuffer(str);
if(matcher.find()) {
sb = new StringBuffer();
matcher.appendReplacement(sb, matcher.group(1).toUpperCase());
matcher.appendTail(sb);
}else {
return sb.toString();
}
return camel(sb.toString());
}
}
这样的话,调用的地方就可以改成下面这样:
return jdbcTemplate.query(sql,new BaseRowMapper(Employee.class));
这样 ,我们在使用的时候只要传入需转换类型就可以了不再 单独 创建 一个 RowMapperRowMapperRowMapperRowMapper RowMapper 。
总结起来,DBUtils和Spring JDBC这两个对JDBC做了轻量封装的框架,可以帮助我们解决下面这些问题:
- 无论是QueryRunner还是JdbcTemplate,都可以传入一个datasource进行初始化,也就是资源管理这部分可以交给专门的数据源组件去管理,不用我们手动的去创建和关闭。
- 对数据库的增删改查都做了封装
- 可以帮助我们映射结果集,无论是映射成List、Map还是实体类
但是这两个框架还是有一些不足:
- SQL语句都是写在代码中的,硬编码问题没有解决
- 参数只能按照固定位置的顺序传入,通过占位符去替换,不能自动映射
- 在方法里面,可以把结果集映射成实体类,但是没有办法把实体类映射成数据库可执行的SQL
- 查询没有缓存功能
3、 Hibernate
要解决上面的问题,使用这些工具类是不够的,我们要使用ORM框架来帮我们解决程序对象和关系型数据库的相互映射的问题。
Hibernate是一个很流行的ORM框架,在使用Hibernate的时候,我们需要为实体类创建一些hbm的xml映射文件,或者是用类似于@Table这样的注解。例如:
<hibernate-mapping>
<class name="com.yrk.User" table="User">
<id name="id">
<generator class="native"/>
</id>
<property name="password"/>
<property name="userName"/>
</class>
</hibernate-mapping>
然后通过Hibernate提供的Session的增删改查方法来操作对象
User user = new User();
user.setPassword("123456");
user.setUserName("test");
//获取加载配置管理类
Configuration configuration = new Configuration();
configuration.configure();
//创建Session工厂
SessionFactory sessionFactory = configuration.buildSessionFactory();
//得到Session
Session session = sessionFactory.openSession();
//开启事务,得到事务对象
Transaction transaction = session.getTransaction();
//开启事务
transaction.begin();
session.save(user);
//提交事务
transaction.commit();
//关闭session
session.close();
我们操作对象就和操作数据库数据一样,Hibernate会自动帮我们生成SQL语句(可以屏蔽不同数据库的差异),自动进行映射。这样我们的代码变得简洁了,可读性也提高了。
但是Hibernate在业务复杂的项目中也存在一些问题:
- 比如使用get()、save()、update()这些方法操作对象的时候,实际操作的是所有字段,没有办法指定部分字段,不够灵活。
- 这种自动生成SQL的方式,如果我们想要对SQL做一些优化,是非常困难的,也就是说可能会出现性能比较差的SQL。
- 不支持动态SQL,比如分表中的表名的变化等。
4、 MyBatis
半自动化的MyBatis可以解决上面Hibernate中存在的几个问题,所谓的"半自动化"是相对于Hibernate这种全自动化的框架来说的,也就是MyBatis的封装性没有Hibernate那么高,不会自动生成全部的SQL语句,主要解决的是SQL和对象的映射问题。
在MyBatis中, SQL和代码是分离的,所以可以说只要会写SQL,就可以用MyBatis,学习成本比较低。
那么MyBatis可以解决那些问题呢?
- 可以使用连接池对连接进行管理
- SQL和代码分离,可以对SQL集中管理,便于维护
- 可以处理结果集和实体类的映射
- 可以解决参数映射和动态SQL
- SQL的重复使用
- 缓存机制
- 插件机制
当然,MyBatis和DBUtils、Spring JDBC以及Hibernate一样,都是对JDBC进行了封装。如果我们去看源码,一定可以找到对Statement以及ResultSet这些对象。那么这么多种工具和框架,我们在项目中要如何选择呢?
- 在一些业务逻辑比较简单,表数量比较少,关系比较简单的项目,可以选择使用Hibernate或者JPA
- 如何需要更加灵活的SQL,可以使用MyBatis
- 对于底层的编码,或者性能要求非常高的场景,可以直接使用JDBC
彩蛋
点击下方链接,可以免费获取大量电子书资源
免费领取
















 1399
1399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











