







1、storm事务性topology的提出
对于容错机制,Storm通过一个系统级别的组件acker,结合xor校验机制判断一个msg是否发送成功,进而spout可以重发该msg,保证一个msg在出错的情况下至少被重发一次。但是在一些事务性要求比较高的场景中,需要保障一次只有一次的语义,比如需要精确统计tuple的数量等等。Storm 0.7.0引入了Transactional Topology, 它可以保证每个tuple”被且仅被处理一次”, 这样你就可以实现一种非常准确,非常可扩展,并且高度容错方式来实现计数类应用。
2、API介绍
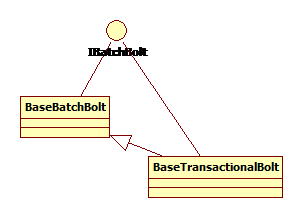
IBatchBolt有三个方法
execute(Tuple tuple)
finishBatch()
prepare (java.util.Map conf, TopologyContext context, BatchOutputCollector collector,T id)
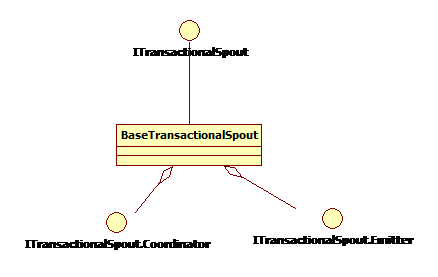
ITransactionalSpout有以下几个主要方法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









