








常用sql
SELECT
LIC_VERSION "许可证版本号",
SERIES_NO "序列号",
CASE WHEN "SERVER_SERIES"='P' THEN '个人版' WHEN "SERVER_SERIES"='S' THEN '标准版' WHEN "SERVER_SERIES"='E' THEN '企业版' WHEN "SERVER_SERIES"='A' THEN '安全版' WHEN "SERVER_SERIES"='C' THEN '云版本' WHEN "SERVER_SERIES"='D' THEN '开发版' END "服务器颁布类型",
CASE WHEN "SERVER_TYPE" ='1' THEN '正式版' WHEN "SERVER_TYPE"='2' THEN '测试版' WHEN "SERVER_TYPE"='3' THEN '试用版' END "服务器发布类型",
SERVER_VER "服务器版本号",
EXPIRED_DATE "有效日期",
AUTHORIZED_CUSTOMER "用户名称",
AUTHORIZED_USER_NUMBER "授权用户数",
CONCURRENCY_USER_NUMBER "并发连接数",
MAX_CPU_NUM "最大CPU数目",
NOACTIVE_DEADLINE "未激活状态截止日期",
PRODUCT_TYPE "产品类型",
PROJECT_NAME "项目名称",
CPU_TYPE "授权运行的 CPU类型",
OS_TYPE "授权运行的操作系统",
MAX_CORE_NUM "授权最大CPU核个数",
CASE WHEN "CLUSTER_TYPE"='1' THEN '主备' WHEN "CLUSTER_TYPE"='2' THEN 'MPP' WHEN "CLUSTER_TYPE"='NULL' THEN '无集群' END "授权使用的集群类型",
DATE_GEN "KEY的生成日期"
FROM
V$LICENSE;
#库基本信息:
SELECT
"NAME" "数据库名称" ,
"CREATE_TIME" "数据库创建时间" ,
case when "ARCH_MODE"='Y' then '归档' else '不归档' end "归档模式" ,
"LAST_CKPT_TIME" "最后一次检查点时间" ,
case when "STATUS$" ='1' then '启动' when "STATUS$"='2' then '启动,redo 完成' when "STATUS$"='3' then 'MOUNT' when "STATUS$"='4' then '打开'when "STATUS$"='5' then '挂起' end "库状态" ,
case when "ROLE$" ='0' then '普通库' when "ROLE$"='1' then '主库' when "ROLE$"='2' then '备库' end "角色" ,
"TOTAL_SIZE"*page/1024/1024||'M' "总大小" ,
--"RAC_NODES" "DSC集群系统中的实例总数" ,
"OPEN_COUNT" "数据库open次数" ,
"STARTUP_COUNT" "数据库启动次数" ,
"LAST_STARTUP_TIME" "数据库最近一次启动时间" ,
page/1024
||'K' "页大小" ,
SF_GET_EXTENT_SIZE() "簇大小" ,
case when SF_GET_CASE_SENSITIVE_FLAG()='1' then '敏感' when SF_GET_CASE_SENSITIVE_FLAG()='0' then '不敏感' end "标识符大小写敏感",
case when SF_GET_UNICODE_FLAG() ='0' then 'GB18030' when SF_GET_UNICODE_FLAG() ='1' then 'UTF-8' when SF_GET_UNICODE_FLAG() ='2' then 'EUC-KR' end "数据库字符集"
FROM
V$DATABASE;
#实例信息
SELECT
"NAME" "实例名称" ,
"INSTANCE_NUMBER" "实例ID",
"HOST_NAME" "主机名称" ,
"SVR_VERSION" "服务器版本" ,
"DB_VERSION" "数据库版本" ,
"START_TIME" "服务器启动时间" ,
"STATUS$" "系统状态" ,
"MODE$" "数据库模式" ,
"OGUID" "控制文件的 OGUID",
--"RAC_SEQNO" "DSC 序号"
--"RAC_ROLE" "DSC系统角色"
SF_GET_PARA_VALUE(2,'PORT_NUM') "端口号"
FROM
V$INSTANCE;
#表空间信息:
select
C."ID" "表空间 ID",
C."NAME" "表空间名称",
--C."CACHE" "CACHE名" ,
CASE WHEN C."TYPE$"='1' THEN 'DB 类型' WHEN C."TYPE$"='2' THEN '临时表空间' END "表空间类型",
CASE WHEN C."STATUS$"='0' THEN 'ONLINE' WHEN C."STATUS$"='1' THEN 'OFFLINE' WHEN C."STATUS$"='2' THEN 'RES_OFFLINE' WHEN C."STATUS$"='3' THEN 'CORRUPT' END "状态",
C."TOTAL_SIZE"*page/1024/1024||'M' "总大小",
C."FILE_NUM" "包含的文件数",
C."ENCRYPT_NAME" "加密算法名",
C."ENCRYPTED_KEY" "加密密钥",
D.used_per
||'%' "表空间使用率"
from
V$TABLESPACE c
join
(
SELECT
a.id,
100-(sum(b.free_size)*100/sum(b.total_size)) used_per
FROM
V$TABLESPACE a,
V$DATAFILE b
where
a.id=b.GROUP_ID
group by
a.id
)
d
on
c.id=d.id
order by
c.id;
#数据文件使用情况:
select
"GROUP_ID" "所属的表空间ID" ,
--"ID" "数据库文件 ID" ,
"PATH" "数据库文件路径" ,
"CREATE_TIME" "创建时间" ,
--"STATUS$" "状态" ,
CASE WHEN "RW_STATUS"='1' THEN '读' WHEN "RW_STATUS"='2' THEN '写' end "读写状态",
"LAST_CKPT_TIME" "最后一次检查点时间" ,
"MODIFY_TIME" "文件修改时间" ,
"MODIFY_TRX" "修改事务" ,
"TOTAL_SIZE"*page/1024/1024
||'M' "总大小",
"FREE_SIZE"*page/1024/1024
||'M' "空闲大小",
"PAGE_SIZE"/1024
||'k' "页大小" ,
CASE WHEN "AUTO_EXTEND"='1' THEN '支持' WHEN "AUTO_EXTEND"='0' THEN '不支持' end "是否支持自动扩展",
"MAX_SIZE"
||'M' "文件最大大小"
--"NEXT_SIZE"
--||'M' "文件每次扩展大小"
--"MIRROR_PATH" "镜像文件路径"
from
V$DATAFILE;
#在线重做日志:
SELECT
A.FILE_ID "文件ID",
A.PATH "文件路径" ,
A.RLOG_SIZE/1024/1024
||'M' "文件大小",
/* B.FREE_SPACE/1024/1024
||'M' "目前可用的日志空间", */
/* B.TOTAL_SPACE/1024/1024
||'M' "日志总空间", */
B.CUR_FILE "记录刷文件前当前文件的ID"
from
(
select * from V$RLOGFILE where true
)
A,
(
select * from V$RLOG where true
)
B;
#部分参数配置信息
SELECT
"PARA_NAME" "参数名称" ,
"PARA_VALUE" "系统参数值" ,
"MIN_VALUE" "最小值" ,
"MAX_VALUE" "最大值" ,
"MPP_CHK" "是否检查 MPP 节点间参数一致性",
"SESS_VALUE" "会话参数值" ,
"FILE_VALUE" "INI 文件中参数值" ,
"DESCRIPTION" "参数描述" ,
"PARA_TYPE" "参数级别"
FROM
V$DM_INI
WHERE
PARA_NAME IN ( 'MAX_OS_MEMORY','MEMORY_POOL', 'MEMORY_TARGET', 'BUFFER', 'BUFFER_POOLS', 'RECYCLE', 'RECYCLE_POOLS', 'DICT_BUF_SIZE', 'WORKER_THREADS', 'TASK_THREADS', 'MAX_SESSIONS', 'TEMP_SPACE_LIMIT', 'ENABLE_MONITOR', 'FAST_COMMIT', 'SVR_LOG', 'HA_INST_CHECK_IP', 'HA_INST_CHECK_PORT', 'RLOG_BUF_SIZE', 'RLOG_POOL_SIZE', 'BUFFER_POOLS', 'FAST_POOL_PAGES', 'FAST_ROLL_PAGES', 'CKPT_RLOG_SIZE', 'CKPT_INTERVAL', 'CKPT_FLUSH_RATE', 'CKPT_FLUSH_PAGES', 'BDTA_SIZE', 'OLAP_FLAG', 'UNDO_RETENTION');
#归档信息
SELECT
"ARCH_NAME" "归档名称",
"ARCH_TYPE" "归档类型",
"ARCH_DEST" "归档目标",
"ARCH_FILE_SIZE" "单个归档文件大小",
"ARCH_SPACE_LIMIT" "归档大小上限",
"ARCH_TIMER_NAME" "定时器名称",
"ARCH_IS_VALID" "归档状态",
"ARCH_WAIT_APPLY" "性能模式",
"ARCH_INCOMING_PATH" "远程归档保存在本地的目录",
case arch_space_limit when 0 then '无限制归档上限,归档总大小为'||(SELECT SUM(LEN)/(1024*1024) FROM V$ARCH_FILE)||'M'
else (
SELECT SUM(LEN)/(1024*1024)*100 FROM V$ARCH_FILE
)/arch_space_limit||'%'
END
"已使用归档空间百分比"
FROM
V$DM_ARCH_INI;
#SVR_LOG
SELECT
"PARA_NAME" "参数名称" ,
CASE WHEN "PARA_VALUE"='1' THEN 'SQLLOG已开启' ELSE THEN 'SQLLOG未开启'END "系统参数值"
-- "MIN_VALUE" "最小值" ,
-- "MAX_VALUE" "最大值" ,
-- "MPP_CHK" "是否检查 MPP 节点间参数一致性",
-- "SESS_VALUE" "会话参数值" ,
-- "FILE_VALUE" "INI 文件中参数值" ,
-- "DESCRIPTION" "参数描述" ,
-- "PARA_TYPE" "参数级别"
FROM
V$DM_INI
WHERE
PARA_NAME = 'SVR_LOG';
#用户信息
select
"USERNAME" "用户名",
"ACCOUNT_STATUS" "账号状态",
"LOCK_DATE" "锁定开始的时间",
"EXPIRY_DATE" "密码过期时间",
"DEFAULT_TABLESPACE" "默认表空间",
--"TEMPORARY_TABLESPACE" "默认临时表空间",
"CREATED" "创建时间",
"PROFILE" "表空间所在路径",
--"EDITIONS_ENABLED" "是否可读" ,
--"AUTHENTICATION_TYPE" "用户登陆验证类型" ,
"NOWDATE" "当前日期时刻"
from
DBA_USERS;
#用户授权信息
SELECT
"GRANTEE" "被授权用户名" ,
"PRIVILEGE" "权限名称" ,
--"PRIVILEGE_TYPE" "权限类型",
"ADMIN_OPTION" "是否可转授"
FROM
(
SELECT
GRANTEE ,
GRANTED_ROLE PRIVILEGE ,
'ROLE_PRIVS' PRIVILEGE_TYPE,
CASE ADMIN_OPTION WHEN 'Y' THEN 'YES' ELSE 'NO' END ADMIN_OPTION
FROM
DBA_ROLE_PRIVS
UNION
SELECT
GRANTEE ,
PRIVILEGE ,
'SYS_PRIVS' PRIVILEGE_TYPE,
ADMIN_OPTION
FROM
DBA_SYS_PRIVS
UNION
SELECT
GRANTEE,
PRIVILEGE
||' ON '
||OWNER
||'.'
||TABLE_NAME PRIVILEGE ,
'TABLE_PRIVS' PRIVILEGE_TYPE,
GRANTABLE
FROM
DBA_TAB_PRIVS
)
WHERE
GRANTEE IN
(
SELECT
USERNAME
FROM
ALL_USERS
WHERE
USERNAME NOT IN ('SYS', 'SYSDBA', 'SYSSSO', 'SYSAUDITOR')
)
ORDER BY
GRANTEE ,
PRIVILEGE_TYPE,
PRIVILEGE;
#用户会话信息
select
b.name "用户名" ,
a.SESS_PER_USER "最大会话数" ,
a.CONN_IDLE_TIME "最大空闲时间(分钟)",
a.FAILED_NUM "登录失败次数" ,
a.LIFE_TIME "口令有效期(天)" ,
a.REUSE_TIME "口令等待期(天)" ,
a.REUSE_MAX "口令变更次数" ,
a.LOCK_TIME "口令锁定期(分钟)" ,
a.GRACE_TIME "口令宽限期(天)" ,
CASE WHEN a.LOCKED_STATUS='1' THEN 'LOCKED' ELSE THEN 'OPEN' END "用户状态",
a.LASTEST_LOCKED "最后一次的锁定时间" ,
a.PWD_POLICY "口令策略" ,
--a.RN_FLAG "是否只读" ,
a.ALLOW_ADDR "允许的 IP 地址" ,
a.NOT_ALLOW_ADDR "不允许的 IP 地址",
a.ALLOW_DT "允许登录的时间段" ,
a.NOT_ALLOW_DT "不允许登录的时间段" ,
a.LAST_LOGIN_DTID "上次登录时间" ,
a.LAST_LOGIN_IP "上次登录 IP 地址" ,
a.FAILED_ATTEMPS "即将被锁定的连续登录失败的次数"
from
SYSUSERS a,
SYS.SYSOBJECTS b
where
a.id=b.id;
#会话信息
SELECT
STATE "会话状态" ,
CLNT_IP "客户端IP",
CLNT_TYPE "连接类型",
CURR_SCH "当前模式",
USER_NAME "当前用户",
COUNT(*) "会话数"
FROM
V$SESSIONS
GROUP BY
STATE ,
CLNT_IP ,
CLNT_TYPE,
CURR_SCH ,
USER_NAME
ORDER BY
STATE;
#死锁
select
"SEQNO" "编号" ,
"TRX_ID" "事务ID" ,
"SESS_ID" "会话ID" ,
"SESS_SEQ" "会话序列号" ,
"SQL_TEXT" "产生死锁的SQL语句",
"HAPPEN_TIME" "死锁发生的时间"
from
V$DEADLOCK_HISTORY;
#事务阻塞信息
WITH
TRX_TAB AS
(
SELECT
O1.NAME,
L1.TRX_ID
FROM
V$LOCK L1,
SYSOBJECTS O1
WHERE
L1.TABLE_ID=O1.ID
AND O1.ID <>0
)
,
TRX_SESS AS
(
SELECT
L.TRX_ID WT_TRXID ,
L.ROW_IDX BLK_TRXID,
L.BLOCKED ,
(
SELECT NAME TABLE_NAME FROM TRX_TAB A WHERE A.TRX_ID=L.TRX_ID
)
WT_TABLE ,
S1.SESS_ID WT_SESS ,
S2.SESS_ID BLK_SESS ,
S1.USER_NAME WT_USER_NAME ,
S2.USER_NAME BLK_USER_NAME,
S1.SQL_TEXT ,
S1.CLNT_IP ,
DATEDIFF(S, S1.LAST_SEND_TIME, SYSDATE) SS
FROM
V$LOCK L ,
V$SESSIONS S1,
V$SESSIONS S2
WHERE
L.TRX_ID =S1.TRX_ID
AND L.ROW_IDX=S2.TRX_ID
)
SELECT
SYSDATE "当前时间" ,
WT_TRXID "所属事务ID" ,
BLK_TRXID "TID锁对象事务ID",
CASE WHEN BLOCKED='1' THEN '是' ELSE THEN '否' END "是否阻塞" ,
WT_TABLE "被阻塞表" ,
WT_SESS "被阻塞的会话ID" ,
BLK_SESS "阻塞的会话ID",
WT_USER_NAME "被阻塞用户" ,
BLK_USER_NAME "阻塞用户" ,
SF_GET_SESSION_SQL(WT_SESS) "被阻塞的SQL" ,
CLNT_IP "客户端IP" ,
SS||'秒' "阻塞时间"
FROM
TRX_SESS
WHERE
BLOCKED=1;
#备份集信息,会校验每个备份集,占用IO,慎用
SELECT
"DEVICE_TYPE" "存储介质类型" ,
"BACKUP_ID" "备份ID" ,
"BACKUP_NAME" "备份名" ,
"BACKUP_PATH" "备份路径" ,
CASE WHEN "TYPE" ='0' THEN '基备份' WHEN "TYPE"='1' THEN '增量备份' WHEN "TYPE"='2' THEN '表备份' WHEN "TYPE"='3' THEN '归档备份' END "备份类型" ,
CASE WHEN "LEVEL" ='0' THEN '联机备份' WHEN "LEVEL"='1' THEN '脱机备份' END "是否脱机备份",
CASE WHEN "RANGE#"='1' THEN '库备份' WHEN "RANGE#"='2' THEN '表空间备份' WHEN "RANGE#"='3' THEN '表级备份' WHEN "RANGE#"='4' THEN '归档备份' END "备份类型" ,
"BASE_NAME" "基备份名" ,
"BACKUP_TIME" "备份时间" ,
"BEGIN_LSN" "备份的起始 LSN值" ,
"END_LSN" "结束备份的 LSN值" ,
"BKP_NUM" "备份片个数" ,
CASE WHEN (
SELECT SF_BAKSET_CHECK(DEVICE_TYPE, BACKUP_PATH)
)
='1' THEN '有效' WHEN (
SELECT SF_BAKSET_CHECK(DEVICE_TYPE, BACKUP_PATH)
)
=0 THEN '无效' END "备份校验",
'SELECT SF_BAKSET_CHECK('
||DEVICE_TYPE
||','
||BACKUP_PATH
||');' "校验命令"
FROM
V$BACKUPSET
WHERE
BACKUP_TIME>(SYSDATE-7);
#作业信息
SELECT
A.ID "作业ID号" ,
A.NAME "作业名称" ,
CASE WHEN A."ENABLE"='1' THEN '启用' WHEN A."ENABLE"='0' THEN '不启用' END "是否被启用",
A.USERNAME "创建者名称" ,
A.CREATETIME "创建时间" ,
A.MODIFYTIME "最后一次被修改的时间" ,
A.DESCRIBE "作业描述" ,
B.LAST_DATE
||' '
||B.LAST_SEC "最后一次运行时间",
B.NEXT_DATE
||' '
||B.NEXT_SEC "下一次运行时间",
B.WHAT "执行任务的PL/SQL块"
FROM
SYSJOB.SYSJOBS A,
SYSJOB.USER_JOBS B
WHERE
A.ID=B.JOB;
#作业调度信息
SELECT
"ID" "调度ID号" ,
"NAME" "调度的名称" ,
"JOBID" "作业ID号" ,
CASE WHEN "ENABLE"='1' THEN '启用' WHEN "ENABLE"='0' THEN '不启用' END "是否启用",
CASE WHEN "TYPE" ='0' THEN '只执行一次' WHEN "TYPE"='1' THEN '按天执行' WHEN "TYPE"='2' THEN '按周执行' WHEN "TYPE"='3' THEN '某个月某一天执行' WHEN "TYPE"='4' THEN '一个月的第一周第几天执行' WHEN "TYPE"='5' THEN '一个月的第二周的第几天执行' WHEN "TYPE"='6' THEN '一个月的第三周的第几天执行' WHEN "TYPE"='7' THEN '一个月的第四周的第几天执行' WHEN "TYPE"='8' THEN '一个月的最后一周的第几天执行' END "调度类型",
CASE WHEN "TYPE" ='0' THEN '只执行一次' WHEN "TYPE"='1' THEN '每隔'
||FREQ_INTERVAL
||'天执行' WHEN "TYPE"='2' THEN '每'
||FREQ_INTERVAL
||'周执行' WHEN "TYPE"='3' THEN '每隔'
||FREQ_INTERVAL
||'个月执行' ELSE THEN '每隔'
||FREQ_INTERVAL
||'个月执行' END "执行的频率",
CASE WHEN "TYPE" ='0' THEN '只执行一次' WHEN "TYPE"='1' THEN '每天执行' WHEN "TYPE"='2' THEN "FREQ_SUB_INTERVAL"
||'(10进制)' else THEN '第'
||"FREQ_SUB_INTERVAL"
||'天执行' END "具体执行的频率" ,
"FREQ_MINUTE_INTERVAL" "一天内每隔多少分钟执行一次",
"STARTTIME" "调度的起始时间" ,
"ENDTIME" "调度结束时间" ,
--"SCHNAME" "驱动触发器所属的数据库模式名" ,
--"TRIGNAME" "触发器名" ,
"VALID" "是否合法"
--"DESCRIBE" "注释信息"
FROM
SYSJOB.SYSJOBSCHEDULES;
#作业步骤
SELECT
"EXEC_ID" "作业执行的ID号" ,
"NAME" "作业名" ,
"STEPNAME" "步骤名" ,
"START_TIME" "步骤开始的时间",
"END_TIME" "步骤结束的时间" ,
--"ERRTYPE" ,
"ERRCODE" "错误码" ,
"ERRINFO" "错误描述信息",
"RETRY_ATTEMPTS" "当前重试次数"
FROM
SYSJOB.SYSSTEPHISTORIES2 A
WHERE
(
SELECT
COUNT(*)
FROM
SYSJOB.SYSSTEPHISTORIES2 B
WHERE
B.NAME = A.NAME
AND B.EXEC_ID >= A.EXEC_ID
)
<= 10
ORDER BY
A.START_TIME DESC,
A.NAME;
#作业错误信息
SELECT
EXEC_ID "作业ID" ,
NAME "作业名" ,
STEPNAME "步骤名" ,
START_TIME "步骤开始的时间",
END_TIME "步骤结束的时间" ,
ERRCODE "错误码" ,
ERRINFO "错误描述信息"
FROM
(
SELECT
EXEC_ID ,
NAME ,
STEPNAME ,
START_TIME,
END_TIME ,
ERRTYPE ,
ERRCODE ,
ERRINFO ,
ROW_NUMBER() OVER (PARTITION BY NAME ORDER BY EXEC_ID DESC) RN
FROM
SYSJOB.SYSSTEPHISTORIES2
)
WHERE
ERRCODE <>0
and RN <=10;
#共享池相关
select
"ADDR" "内存结构地址" ,
"NAME" "内存池名称" ,
"IS_SHARED" "是否共享" ,
"CHK_MAGIC" "是否打开内存校验" ,
"CHK_LEAK" "是否打开泄漏检查" ,
"IS_OVERFLOW" "是否已经触发BAK_POOL的分配",
--"IS_DSA_ITEM" ,
"ORG_SIZE"/1024/1024
||'M' "初始大小",
"TOTAL_SIZE"/1024/1024
||'M' "当前总大小",
"RESERVED_SIZE"/1024/1024
||'M' "已经分配大小",
"DATA_SIZE"/1024/1024
||'M' "分配的数据占用大小",
"EXTEND_SIZE"/1024/1024
||'M' "每次扩展的块大小",
"TARGET_SIZE"/1024/1024
||'M' "扩展的目标大小" ,
"EXTEND_LEN" "扩展链长度" ,
"N_ALLOC" "累计分配次数" ,
"N_EXTEND_NORMAL" "TARGET范围内累计扩展次数" ,
"N_EXTEND_EXCLUSIVE" "超出TARGET累计扩展次数",
"N_FREE" "累计释放次数" ,
"MAX_EXTEND_SIZE"/1024/1024
||'M' "最大的扩展块",
"MIN_EXTEND_SIZE"/1024/1024
||'M' "最小的扩展块" ,
"FILE_NAME" "源文件名" ,
"FILE_LINE" "所在的代码行",
"CREATOR" "创建者线程号"
from
V$MEM_POOL;
#实例启动以来的长sql
SELECT
top 20 "SQL_TEXT" "SQL文本",
"EXEC_TIME"/1000
||'秒' "执行时间" ,
"FINISH_TIME" "执行结束时间",
"N_RUNS" "执行次数"
FROM
V$SYSTEM_LONG_EXEC_SQLS
ORDER BY
EXEC_TIME DESC;
#使用内存较多的sql
select
top 20 "SESS_ID" "SESSION的ID",
--"SQL_ID" "语句的SQLID" ,
"SQL_TEXT" "SQL文本" ,
"MEM_USED_BY_K"/1024||'M' "使用的内存",
"FINISH_TIME" "执行结束时间" ,
"N_RUNS" "执行次数"
--"SEQNO" "编号" ,
--"TRX_ID" "事务号" ,
--"SESS_SEQ" "会话序列号"
from
V$SYSTEM_LARGE_MEM_SQLS
order by
mem_used_by_k desc;
查看进程cpu高原因
perf top
系统时间
SELECT SYSDATE();
杀掉七天之前会话
select 'sp_close_session('||sess_id||');' from v$sessions where create_time < sysdate -7;
查看ddl
CALL SP_TABLEDEF(‘PRODUCTION’, ‘PRODUCT’);
–统计页大小
select page;
–通过编码字符集格式
select unicode;
–统计大小写敏感参数
select case_sensitive;
–查询活动会话数
select count(*) from v$sessions where state='ACTIVE';
–查询已执行超过2秒的活动SQL
select * from (
SELECT sess_id,sql_text,datediff(ss,last_send_time,sysdate) Y_EXETIME,
SF_GET_SESSION_SQL(SESS_ID) fullsql,clnt_ip
FROM V$SESSIONS WHERE STATE='ACTIVE')
where Y_EXETIME>=2;
锁查询
select o.name,l.* from v$lock l,sysobjects o where l.table_id=o.id and blocked=1
拼接sql
select 'insert into "CY234"."TABLE_1" ("COLUMN_1","COLUMN_2") values ('||COLUMN_1||','||COLUMN_2||');' FROM CY234.TABLE_1
阻塞查询
with locks as(
select o.name,l.*,s.sess_id,s.sql_text,s.clnt_ip,s.last_send_time from v$lock l,sysobjects o,v$sessions s
where l.table_id=o.id and l.trx_id=s.trx_id ),
lock_tr as ( select trx_id wt_trxid,row_idx blk_trxid from locks where blocked=1),
res as( select sysdate stattime,t1.name,t1.sess_id wt_sessid,s.wt_trxid,
t2.sess_id blk_sessid,s.blk_trxid,t2.clnt_ip,SF_GET_SESSION_SQL(t1.sess_id) fulsql,
datediff(ss,t1.last_send_time,sysdate) ss,t1.sql_text wt_sql from lock_tr s,locks t1,locks t2
where t1.ltype='OBJECT' and t1.table_id<>0 and t2.ltype='OBJECT' and t2.table_id<>0
and s.wt_trxid=t1.trx_id and s.blk_trxid=t2.trx_id)
select distinct wt_sql,clnt_ip,ss,wt_trxid,blk_trxid from res;
表空间使用率
SELECT
a.tablespace_name “表空间名称” ,
total / (1024 * 1024) “表空间大小(M)” ,
free / (1024 * 1024) “表空间剩余大小(M)” ,
(total - free) / (1024 * 1024 ) “表空间使用大小(M)” ,
total / (1024 * 1024 * 1024) “表空间大小(G)” ,
free / (1024 * 1024 * 1024) “表空间剩余大小(G)” ,
(total - free) / (1024 * 1024 * 1024) “表空间使用大小(G)”,
round((total - free) / total, 4) * 100 “使用率 %”
FROM
(
SELECT
tablespace_name,
SUM(bytes) free
FROM
dba_free_space
GROUP BY
tablespace_name
)
a,
(
SELECT
tablespace_name,
SUM(bytes) total
FROM
dba_data_files
GROUP BY
tablespace_name
)
b
WHERE
a.tablespace_name = b.tablespace_name;
临时表空间
Temp 表空间可自动扩充,为了不影响磁盘空间的使用,通常会通过 ini 参数 TEMP_SIZE 配置大小,TEMP_SPACE_LIMIT 设置上限,通过存储过程 SP_TRUNC_TS_FILE 来收缩 Temp 表空间文件过大可能说明内存过小或者存在大量排序或者中间结果集存放,需要视情况开展优化工作。
检查 Temp 表空间的大小,SQL 语句如下所示:
SELECT
a.tablespace_name “表空间名称” ,
total / (1024 * 1024) “表空间大小(M)” ,
free / (1024 * 1024) “表空间剩余大小(M)” ,
(total - free) / (1024 * 1024 ) “表空间使用大小(M)” ,
total / (1024 * 1024 * 1024) “表空间大小(G)” ,
free / (1024 * 1024 * 1024) “表空间剩余大小(G)” ,
(total - free) / (1024 * 1024 * 1024) “表空间使用大小(G)”,
round((total - free) / total, 4) * 100 “使用率 %”
FROM
(
SELECT
tablespace_name,
SUM(bytes) free
FROM
dba_free_space
GROUP BY
tablespace_name
)
a,
(
SELECT
tablespace_name,
SUM(bytes) total
FROM
dba_data_files
GROUP BY
tablespace_name
)
b
WHERE
a.tablespace_name = b.tablespace_name and a.tablespace_name=‘TEMP’;
回收 Temp 表空间,SQL 语句如下所示:
CALL SP_TRUNC_TS_FILE (ts_id ,file_id, to_size);
其中 ts_id,file_id 可以通过 v$datafile 查询,to_szieb 表示指定将文件截断至多大,以 MB 为单位;to_size 大小换算成页数后,值必须在 4096 到 2 GB 之间。
Ts_id 对应 GROUP_ID。
File_id 对应 ID。
CALL SP_TRUNC_TS_FILE (3 ,0, 32) 表示将临时表空间文件号为 0 的文件截断缩小到 32 MB 大小。
Undo 回滚段
Undo 回滚段也被称为 undo 表空间,是由 DM 数据库自动维护管理。记录的是数据变动过程中的各个版本,在数据库数据发生频繁变动时,会生成大量的回滚段记录,由参数 UNDO_RETENTION 来控制回滚页保持时间,默认为 90s,一般保持默认即可,设置太小,可能会影响数据大批量查询,设置太大会在数据库启动时做过多的回滚操作。
查看用户占用的空间,返回值为占用的页的数
SELECT USER_USED_SPACE(‘USER’);
看表占用的空间
函数参数为模式名和表名 页的数目。
SELECT TABLE_USED_SPACE(‘SYSDBA’, ‘TEST’);
查看索引占用的空间,函数参数为索引 ID 页的数目。
SELECT INDEX_USED_SPACE(33555463);
实例中查询活动会话
SELECT count(*) FROM v
s
e
s
s
i
o
n
s
W
H
E
R
E
s
t
a
t
e
=
′
A
C
T
I
V
E
′
;
−
−
获
取
完
整
s
q
l
S
E
L
E
C
T
S
Y
S
D
A
T
E
,
S
F
G
E
T
S
E
S
S
I
O
N
S
Q
L
(
S
E
S
S
I
D
)
,
s
e
s
s
i
d
,
s
e
s
s
s
e
q
,
s
q
l
t
e
x
t
,
s
t
a
t
e
,
s
e
q
n
o
,
u
s
e
r
n
a
m
e
,
t
r
x
i
d
,
c
r
e
a
t
e
t
i
m
e
,
c
l
n
t
i
p
F
R
O
M
v
sessions WHERE state='ACTIVE'; --获取完整sql SELECT SYSDATE, SF_GET_SESSION_SQL (SESS_ID), sess_id, sess_seq, sql_text, state, seq_no, user_name, trx_id, create_time, clnt_ip FROM v
sessionsWHEREstate=′ACTIVE′;−−获取完整sqlSELECTSYSDATE,SFGETSESSIONSQL(SESSID),sessid,sessseq,sqltext,state,seqno,username,trxid,createtime,clntipFROMvsessions
WHERE state = ‘ACTIVE’;
实例中锁查询
锁查询语句:
SELECT o.name, l.*
FROM v$lock l, sysobjects o
WHERE l.table_id = o.id AND blocked = 1;
WITH locks
AS (SELECT o.name,
l.*,
s.sess_id,
s.sql_text,
s.clnt_ip,
s.last_send_time
FROM v
l
o
c
k
l
,
s
y
s
o
b
j
e
c
t
s
o
,
v
lock l, sysobjects o, v
lockl,sysobjectso,vsessions s
WHERE l.table_id = o.id AND l.trx_id = s.trx_id),
lock_tr
AS (SELECT trx_id wt_trxid, row_idx blk_trxid
FROM locks
WHERE blocked = 1),
res
AS (SELECT SYSDATE stattime,
t1.name,
t1.sess_id wt_sessid,
s.wt_trxid,
t2.sess_id blk_sessid,
s.blk_trxid,
t2.clnt_ip,
SF_GET_SESSION_SQL (t1.sess_id) fulsql,
datediff (ss, t1.last_send_time, SYSDATE) ss,
t1.sql_text wt_sql
FROM lock_tr s, locks t1, locks t2
WHERE t1.ltype = ‘OBJECT’
AND t1.table_id <> 0
AND t2.ltype = ‘OBJECT’
AND t2.table_id <> 0
AND s.wt_trxid = t1.trx_id
AND s.blk_trxid = t2.trx_id)
–select distinct clnt_ip from res;
SELECT DISTINCT wt_sql, clnt_ip, ss
FROM res;
实例中已执行未提交的 SQL 查询
SELECT t1.sql_text, t1.state, t1.trx_id
FROM v
s
e
s
s
i
o
n
s
t
1
,
v
sessions t1, v
sessionst1,vtrx t2
WHERE t1.trx_id = t2.id AND t1.state = ‘IDLE’ AND t2.status = ‘ACTIVE’;
有事务未提交的表查询
SELECT b.object_name, c.sess_id, a.*
FROM v
l
o
c
k
a
,
d
b
a
o
b
j
e
c
t
s
b
,
v
lock a, dba_objects b, v
locka,dbaobjectsb,vsessions c
WHERE a.table_id = b.object_id AND ltype = ‘OBJECT’ AND a.trx_id = c.trx_id;
长时间的 SQL 查询
SELECT t1.sql_text, t1.state, t1.trx_id
FROM v
s
e
s
s
i
o
n
s
t
1
,
v
sessions t1, v
sessionst1,vtrx t2
WHERE t1.trx_id = t2.id AND t1.state = ‘IDLE’ AND t2.status = ‘ACTIVE’;
找出已执行超过 2 秒的活动 SQL
SELECT *
FROM (SELECT sess_id,
sql_text,
datediff (ss, last_recv_time, SYSDATE) Y_EXETIME,
SF_GET_SESSION_SQL (SESS_ID) fullsql,
clnt_ip
FROM V$SESSIONS
WHERE STATE = ‘ACTIVE’)
WHERE Y_EXETIME >= 2;
linux
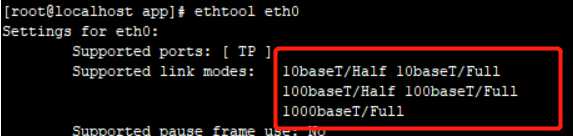
ethtool 查看网卡
单机、主备集群、MPP、读写分离集群要求网卡是千兆网卡以上,DMDSC 集群建议是万兆网卡
防火墙及 selinux 检查
redhat 6
service iptables status
iptables -L --查看防火墙状态
iptables -F --清空防火墙配置
若防火墙开启,检查数据库端口策略
iptables -L -n 查看是否有5236
service iptables status
chkconfig iptables off
redhat 7
systemctl status firewalld
firewall-cmd --list-all
firewall-cmd --state --查看防火墙状态
firewall-cmd --add-port=5236/tcp --临时添加 5236 端口白名单
关闭 selinux
set enforce 0
vim /etc/selinux/config
CPU 型号及核数
cat /proc/cpuinfo
系统资源限制
data seg size
建议用户设置为 1048576 (即 1 GB)以上或 unlimited(无限制),此参数过小 将可能导致数据库启动失败。
file size
建议用户设置为 unlimited(无限制),此参数过小将可能导致数据库安装或初始化失败。
open files
建议用户设置为 65536 以上或 unlimited(无限制)。
virtual memory
建议用户设置为 1048576(即 1 GB)以上或 unlimited(无限制),此参数过小 将可能导致数据库启动失败。
登录数据库运行用户,执行以下命令:
ulimit -a
root 修改 /etc/security/limits.conf
Core 文件设置
ulimit -c
修改 core 文件大小,执行以下命令:(只在当前会话有效)
例如:ulimit -c unlimited 表示不限制生成的core文件大小
修改 limit 配置,即登录 root 修改 /etc/security/limits.conf

查看及修改 core 默认生成路径
执行以下命令:
cat /proc/sys/kernel/core_pattern
echo “/corefile/core-%e-%p-%t” > /proc/sys/kernel/core_pattern
将会控制所产生的 core 文件会存放到 /corefile 目录下,产生的文件名为 core- 命令名 -pid- 时间戳,执行以下命令:
sysctl -w kernel.core_pattern=/corefile/core.%e.%p.%s.%E
磁盘调度算法
查看 sda 盘调度算法命令:cat /sys/block/sda/queue/scheduler,数据库服务器建议使用 deadline io 调度算法
echo deadline > /sys/block/sda/queue/scheduler
修改内核引导参数,加入 elevator= 调度程序名,执行以下命令:(永久修改,需要重启服务器才生效)
[root@localhost ~]# grubby --update-kernel=ALL --args=“elevator=deadline”
[root@localhost ~]# reboot
磁盘读写检查
写入测试
dd if=/dev/zero of=test bs=64k count=4k oflag=dsync
正常写速度:机械磁盘在 50 MB/s~90 MB/s,固态硬盘在 150 MB/s-300 MB/s。
读取测试
dd if=test of=/dev/zero bs=64k count=4k oflag=dsync
操作系统资源利用率
cpu----top
%id:空闲 CPU 百分比,若该值很低,则需要检查 CPU 具体被哪个进程占用,是否存在瓶颈。
%us:用户空间占用 CPU 百分比。
内存
使用命令:<free -m /nmon>,关注 buffer/cache 和 free 内存,若 swap 可用过少,服务器内存使用可能有存在内存问题。
可用 cat /proc/sys/vm/swappiness 查看当物理内存使用多少后才会用到 swap。
该参数建议修改为 60%.
磁盘I/O速率
<iostat -xm -t 1 /nmon>,关注 cpu 使用率及读写率。
如果 %iowait 的值过高,表示硬盘存在 I/O 瓶颈。
如果 %idle 值高,表示 CPU 较空闲。
如果 %idle 值高但系统响应慢时,可能是 CPU 等待分配内存,应加大内存容量。
如果 %idle 值持续低于 10,表明 CPU 处理能力相对较低,系统中最需要解决的资源是 CPU。
数据库版本
select * from v$version;
安全性
密码策略检查
默认2 即密码长度不小于9。
Select * from v$dm_ini where para_name=‘PWD_POLICY’;
用户资源限制检查
DM 管理工具->右键相应用户->修改->资源限制
通讯加密检查
dm.ini 参数 COMM_ENCRYPT_NAME 来实现,消息加密算法名。如果为空则不进行通信加密;如果给的加密算法名错误,则用使用加密算法 DES_CFB。DM 支持的加密算法名可以通过查询动态视图 V$CIPHERS 获取。无特殊要求,请勿开启该参数,以免造成不必要的性能消耗。
集群配置健康检查
获取主备库状态、守护进程状态、以及主备库数据同步情况等信息。
./dmmonitor dmmonitor.ini
切换模式
切换模式分为自动切换和手动切换,可检查主备库 dmwatcher.ini 文件的 DW_MODE 参数。
MANUAL
故障手动切换模式,故障时前台启动监视器进行切换。
AUTO
故障自动切换模式,需要后台运行确认监视器。
1、修改数据表字段类型和长度
–设置字段类型和长度
alter table “SYSDBA”.“MY_TABLE” modify “ID” VARCHAR2(50);
2、增加和去除唯一性设置
注意:唯一性与主键互斥,只能选其一。获取唯一性约束的KEY,参见后面的语句。
–增加唯一
alter table “SYSDBA”.“MY_TABLE” add constraint U_ID unique(id);
–去掉唯一
alter table “SYSDBA”.“MY_TABLE” drop constraint U_ID ;
3、设置可空或不可空特性
–可空
alter table “SYSDBA”.“MY_TABLE” alter column “ID” set null;
–非空
alter table “SYSDBA”.“MY_TABLE” alter column “ID” set not null;
4、增加主键和去除主键
–增加主键
alter table “SYSDBA”.“MY_TABLE” add primary key(“ID”);
–去掉主键
alter table “SYSDBA”.“MY_TABLE” drop constraint “CONS134237151”;–主键ID的获取参见第7条
alter table “SYSDBA”.“MY_TABLE” alter column “ID” set null;
5、查询数据库中的表
SELECT * FROM ALL_TABLES; --查询表
6、查看数据表定义
SELECT TABLEDEF(‘SYSDBA’,‘MY_TABLE’); --查看表定义,入参:模式名,表名
7、查看表具有的约束
–查看所有主键约束
SELECT * FROM ALL_CONSTRAINTS WHERE CONSTRAINT_TYPE=‘P’;
–所有约束种类
SELECT DISTINCT CONSTRAINT_TYPE FROM ALL_CONSTRAINTS;
CONSTRAINT_TYPE取值:
C:检验约束
P:主键约束
U:唯一性约束
R:外键约束
V:未知(编者注)
–查看某张表所有约束
SELECT * FROM ALL_CONSTRAINTS WHERE TABLE_NAME=‘MY_TABLE’;
查看表结构**-注意大小写
SELECT DBMS_METADATA.GET_DDL(‘TABLE’,‘t1’,‘CY123’) FROM dual;
SP_TABLEDEF(‘CY123’,‘t1’);
DM_SQL 语言使用手册
判断某个值是否为空值,若不为空值则输出,若为空值,返回指定值
SELECT employee_name, employee_id, NVL (commission_pct, 0) AS commission_pct FROM dmhr.employee;
基础sql
空值与函数
函数对空值的处理方式各不一样,有些会返回空值,
最大值函数
SELECT GREATEST(16,NULL) FROM dual;返回null
SELECT REPLACE(‘123456’,3,NULL) FROM dual;
where 子句中引用别名列
where 条件引用别名一定要嵌套一层,因为别名是在 select 之后才有效
错误:SELECT employee_id emid, email emna, salary sal FROM dmhr.employee WHERE sal > 10000;
正确:SELECT *
FROM (SELECT employee_id emid, email emna, salary sal FROM dmhr.employee)
WHERE sal > 10000;
列拼接
SELECT employee_name || ’ salary is ’ || salary AS col1 FROM dmhr.employee;
SELECT 'TRUNCATE TABLE ’ || schema_name || ‘.’ || table_name
FROM ALL_TABLES_DIS_INFO
WHERE schema_name = ‘DMHR’;
字符串连接符 || 也可以改成 concat 函数。示例语句如下所示:
SELECT CONCAT (‘ABC’,‘BCD’,‘DDD’,‘BBB’) AS “OUTPUT” FROM DUAL;
WHEN 。。。THEN 。。。
SELECT employee_name,
salary,
CASE
WHEN salary <= 4000 THEN ‘low’
WHEN salary >= 12000 THEN ‘high’
ELSE ‘ok’
END AS salary_status
FROM dmhr.employee;
如何限制返回的行数
SELECT *
FROM (SELECT ROWNUM AS rn, t.*
FROM dmhr.employee t
WHERE ROWNUM <= 10)
WHERE rn = 2;
SELECT * FROM dmhr.employee LIMIT 2;
分区表
DM 支持的分区类型
范围分区
哈希分区
列表分区
组合分区
间隔分区
创建分区表的时候,主键列必须在分区范围内
如果表上存在聚集索引且索引键为主键,并希望各个分区放置在不同表空间上,优化 IO ,则必须在主键列中加入分区键,参考如下建表语句:
创建表空间
CREATE TABLESPACE tbs_p1 DATAFILE ‘/dm/data/DM1_NEW/p1.dbf’ SIZE 32;
CREATE TABLESPACE tbs_p2 DATAFILE ‘/dm/data/DM1_NEW/p2.dbf’ SIZE 32;
CREATE TABLESPACE tbs_p3 DATAFILE ‘/dm/data/DM1_NEW/p3.dbf’ SIZE 32;
CREATE TABLESPACE tbs_pmax DATAFILE ‘/dm/data/DM1_NEW/pmax.dbf’ SIZE 32;
创建分区表
CREATE TABLE dmhr.rp_emp
(
employee_id INT,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT pk_emp PRIMARY KEY (employee_id, hire_date),
CONSTRAINT emp_dept_fk1 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY RANGE (hire_date)
(PARTITION p1 VALUES LESS THAN (‘2011-1-1’) TABLESPACE tbs_p1,
PARTITION p2 VALUES LESS THAN (‘2015-1-1’) TABLESPACE tbs_p2,
PARTITION p3 VALUES LESS THAN (‘2016-1-1’) TABLESPACE tbs_p3,
PARTITION pmax VALUES LESS THAN (MAXVALUE) TABLESPACE tbs_pmax)
范围分区
//创建范围分区,以 hire_date 为分区键,同时增加 MAXVALUE 分区。
CREATE TABLE dmhr.rp_hiredt_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk1 UNIQUE (email),
CONSTRAINT emp_dept_fk1 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY RANGE(hire_date)
(
PARTITION p1 VALUES LESS THAN (‘2007-1-1’),
PARTITION p2 VALUES LESS THAN (‘2008-1-1’),
PARTITION p3 VALUES LESS THAN (‘2009-1-1’),
PARTITION p4 VALUES LESS THAN (‘2010-1-1’),
PARTITION p5 VALUES LESS THAN (‘2011-1-1’),
PARTITION p6 VALUES LESS THAN (‘2012-1-1’),
PARTITION p7 VALUES LESS THAN (‘2013-1-1’),
PARTITION p8 VALUES LESS THAN (‘2014-1-1’),
PARTITION p9 VALUES LESS THAN (‘2015-1-1’),
PARTITION p10 VALUES LESS THAN (‘2016-1-1’),
PARTITION pmax VALUES LESS THAN (MAXVALUE))
STORAGE (NOBRANCH
);
判断一张表是否为分区表
SELECT partitioned FROM dba_tables WHERE table_name=‘RP_HIREDT_EMP’;
查看表的分区状态
SELECT partitioning_type, partition_count, partitioning_key_count,
def_tablespace_name,status FROM dba_part_tables;
查看所有的表分区
SELECT partition_name, high_value, tablespace_name FROM dba_tab_partitions
WHERE table_name=‘RP_HIREDT_EMP’;
列表分区
CREATE TABLE dmhr.lp_job_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk2 UNIQUE (email),
CONSTRAINT emp_dept_fk2 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY LIST (job_id)
(PARTITION p1 VALUES (‘11’,‘12’,‘21’,‘22’),
PARTITION p2 VALUES (‘31’,‘32’,‘41’,‘42’),
PARTITION p3 VALUES (‘51’,‘52’,‘61’,‘62’),
PARTITION p4 VALUES (‘71’,‘72’,‘81’,‘82’),
PARTITION pmax VALUES (DEFAULT))
STORAGE (NOBRANCH);
查询各分区的行数和累加行数
WITH p AS
(SELECT ‘P1’ AS pars, COUNT() AS num FROM dmhr.lp_job_emp PARTITION (P1)
UNION ALL
SELECT ‘P2’, COUNT() FROM dmhr.lp_job_emp PARTITION (P2)
UNION ALL
SELECT ‘P3’, COUNT() FROM dmhr.lp_job_emp PARTITION (P3)
UNION ALL
SELECT ‘P4’, COUNT() FROM dmhr.lp_job_emp PARTITION (P4))
SELECT pars, num, SUM(num) OVER(order by pars rows unbounded preceding)
row_sum FROM p;
哈希分区
CREATE TABLE dmhr.hp_email_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk3 UNIQUE (email),
CONSTRAINT emp_dept_fk3 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY HASH (email)
(PARTITION p1, PARTITION p2, PARTITION p3, PARTITION p4)
STORAGE (NOBRANCH);
查询各分区的行数和累加行数
WITH p AS
(SELECT ‘P1’ AS pars, COUNT() AS num FROM dmhr.hp_email_emp PARTITION (P1)
UNION ALL
SELECT ‘P2’, COUNT() FROM dmhr.hp_email_emp PARTITION (P2)
UNION ALL
SELECT ‘P3’, COUNT() FROM dmhr.hp_email_emp PARTITION (P3)
UNION ALL
SELECT ‘P4’, COUNT() FROM dmhr.hp_email_emp PARTITION (P4))
SELECT pars, num, SUM(num) OVER(order by pars rows unbounded preceding)
row_sum FROM p;
组合分区
组合分区是指范围分区、列表分区或哈希分区的两两组合,以下介绍其中一种组合分区 range-hash。
员工的雇佣时间为主分区键,从 2007 年起,每 3 年划分一个分区,每个分区包含 2 个 hash 子分区
CREATE TABLE dmhr.rhp_emp
(
employee_id INT PRIMARY KEY,
employee_name VARCHAR (20),
identity_card VARCHAR (18),
email VARCHAR (50) NOT NULL,
phone_num VARCHAR (20),
hire_date DATE NOT NULL,
job_id VARCHAR (10) NOT NULL,
salary INT,
commission_pct INT,
manager_id INT,
department_id INT,
CONSTRAINT emp_email_uk4 UNIQUE (email),
CONSTRAINT emp_dept_fk4 FOREIGN KEY
(department_id)
REFERENCES dmhr.department (department_id),
CHECK (salary > 0)
)
PARTITION BY RANGE (hire_date)
SUBPARTITION BY HASH (email)
SUBPARTITION TEMPLATE (SUBPARTITION p1 , SUBPARTITION p2 )
(
PARTITION p1 VALUES LESS THAN (‘2010-1-1’),
PARTITION p2 VALUES LESS THAN (‘2013-1-1’),
PARTITION p3 VALUES LESS THAN (‘2016-1-1’),
PARTITION pmax VALUES LESS THAN (MAXVALUE))
STORAGE (NOBRANCH);
查询每个主分区下的子分区
SELECT partition_name,
subpartition_count,
composite,
high_value,
tablespace_name
FROM dba_tab_partitions
WHERE table_name = UPPER (‘rhp_emp’)
ORDER BY partition_position;
查询组合分区子分区的键信息
SELECT name,object_type,column_name,column_position FROM user_subpart_key_columns;
间隔分区
间隔分区可以在输入相应分区的数据后自动创建分区,是范围分区的扩展。例如:将 dmhr 用户下 employee 表中员工信息按入职时间以年为间隔转换为分区表。
CREATE TABLE dmhr.emp_part
(
EMPLOYEE_ID INT PRIMARY KEY,
EMPLOYEE_NAME VARCHAR (20),
IDENTITY_CARD VARCHAR (18),
EMAIL VARCHAR (50) NOT NULL,
PHONE_NUM VARCHAR (20),
HIRE_DATE DATE NOT NULL,
JOB_ID VARCHAR (10) NOT NULL,
SALARY INT,
COMMISSION_PCT INT,
MANAGER_ID INT,
DEPARTMENT_ID INT
)
PARTITION BY RANGE (hire_date)
INTERVAL ( NUMTOYMINTERVAL (1, ‘year’) )
(
PARTITION
P_BEFORE_2007
VALUES LESS THAN (TO_DATE (‘2007-01-01’, ‘yyyy-mm-dd’)))
STORAGE (FILLFACTOR 85, BRANCH(32,32));
通过 dba_tab_partitions 表查询分区信息,示例语句如下:
SELECT table_name,partition_name, high_value FROM dba_tab_partitions
WHERE table_name=‘EMP_PART’ ORDER BY high_value;
按分区名称检索数据如下,示例语句如下:
SELECT * FROM dmhr.emp_part PARTITION(P_BEFORE_2007);
插入数据,自动新增分区表。在 emp_part 表中插入一条新记录,员工入职时间为 2020 年 5 月 30 日。示例语句如下:
INSERT INTO dmhr.emp_part(EMPLOYEE_ID,EMPLOYEE_NAME,IDENTITY_CARD,EMAIL,
PHONE_NUM,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID)
VALUES(9990,‘武达梦’,‘340102196202303999’,‘wudm@dameng.com’,‘15312348566’,
‘2020-05-30’,‘11’,50000.00,0,1001,101);
commit;
通过系统表 dba_tab_partitions 查询新增数据分区,示例语句如下:
SELECT table_name,partition_name, high_value FROM dba_tab_partitions
WHERE table_name=‘EMP_PART’ ORDER BY high_value;
分区表的维护
增加分区
ALTER TABLE ADD PARTITION 语句将新分区增加到最后一个现存分区的后面。以上面建立的范围分区 rp_hiredt_emp为例。
增加一个分区存储 2016 年雇佣的员工信息,示例语句如下:
ALTER TABLE dmhr.rp_hiredt_emp ADD PARTITION p_before_2017
VALUES LESS THAN (‘2017-1-1’);
输出结果:
新增分区出错
【问题原因】:
分区表中已含有 MAXVALUE 分区,无法再增加分区。
【解决方法】:
使用 SPLIT PARTITION 子句对分区进行拆分。删除 MAXVALUE 分区,新增分区后,再加上 MAXVALUE 分区。示例语句如下:
//1. 删除 MAXVALUE 分区
ALTER TABLE dmhr.rp_hiredt_emp DROP PARTITION pmax;
//2. 新增分区
ALTER TABLE dmhr.rp_hiredt_emp ADD PARTITION p_before_2017 VALUES
LESS THAN (‘2017-1-1’);
//3. 增加 MAXVALUE 分区
ALTER TABLE dmhr.rp_hiredt_emp ADD PARTITION pmax VALUES LESS THAN (MAXVALUE);
删除分区
使用 DROP PARTITION 可将分区的定义连同数据一起删除,示例语句如下:
ALTER TABLE dmhr.rp_hiredt_emp DROP PARTITION pmax;
使用 TRUNCATE PARTITION 仅删除分区的数据,示例语句如下:
ALTER TABLE dmhr.rp_hiredt_emp TRUNCATE PARTITION p7;
合并分区
将 2008 年和 2009 年入职员工各的分区合并为一个分区。
查询分区信息,示例语句如下:
SELECT ‘P3’ AS pars, COUNT() AS num FROM dmhr.rp_hiredt_emp PARTITION (P3)
UNION ALL
SELECT ‘P4’, COUNT() FROM dmhr.rp_hiredt_emp PARTITION (P4)
输出结果:
合并分区前
使用 MERGE……INTO 合并两个分区,示例语句如下:
ALTER TABLE dmhr.rp_hiredt_emp MERGE PARTITIONS p3, p4 into partition p3_4;
查询合并后的分区的记录数,示例语句如下:
SELECT COUNT(*) AS num FROM dmhr.rp_hiredt_emp PARTITION (P3_4);
输出结果:
合并分区后
注意
仅范围分区支持合并,并且待合并的分区必须相邻。
拆分分区
当一个分区变得太大以至于要用很长时间才能完成备份、恢复或维护操作时,可考虑将分区进行拆分。
将上例中已合并的分区 P3_4 重新拆分成 P3 和 P4.
使用 SPLIT……INTO 拆分分区,示例语句如下:
ALTER TABLE dmhr.rp_hiredt_emp SPLIT PARTITION p3_4 AT (‘2009-01-01’)
INTO (PARTITION p3, PARTITION p4);
查询拆分得到的 2 个分区,示例语句如下:
SELECT ‘P3’ AS pars, COUNT() AS num FROM rp_hiredt_emp PARTITION (P3)
UNION ALL
SELECT ‘P4’, COUNT() FROM rp_hiredt_emp PARTITION (P4)
输出结果:
拆分后分区
注意
拆分分区会导致数据的重组和分区索引的重建。因此,拆分分区可能比较耗时,所需时间取决于分区数据量的大小。
分区索引
支持对水平分区表建立普通索引、唯一索引、聚集索引和函数索引。
创建索引时若未指定 GLOBAL 关键字则建立的索引是局部索引。
局部索引是指每个表分区都对应一个索引分区,并且只能检索该分区上的数据。
全局索引是指每个表分区的数据都被索引在同一个 B 树中。
目前,仅堆表的水平分区表支持 GLOBAL全局索引,堆表上的 primary key 会自动变为全局索引。
在 lp_job_emp 表上的 salary 列上建立普通局部索引,示例语句如下:
CREATE INDEX ind_sal ON dmhr.lp_job_emp(salary);
在 lp_job_emp 表上的 email 列上建立局部唯一索引,同时必须将分区键 job_id 列入,示例语句如下:
CREATE UNIQUE INDEX ind_mail ON dmhr.lp_job_emp(job_id, email);
建立局部分区索引后,每一个分区子表都会建立一个索引分区,负责索引分区子表的数据。每个索引分区只负责索引本分区上的数据,其他分区上的数据无法维护。
查询分区索引如下,示例语句如下:
SELECT * FROM user_ind_partitions WHERE index_name=UPPER(‘ind_sal’)
ORDER BY partition_name;
查询分区索引
通过 user_ind_partitions 系统表查询分区索引信息,必须以 dmhr 用户登录数据库。
SELECT index_name, index_type, table_name, uniqueness, tablespace_name, status,
partitioned FROM dba_indexes WHERE TABLE_NAME=UPPER(‘lp_job_emp’);
输出结果:
查询分区索引
注意
不能在水平分区表上建立局部唯一函数索引,只能建立分区键索引,即分区键必须都包含在索引键中。
非分区表转换成分区表
根据原表结构创建所需的分区表,建立各种约束,转换方法如下:
使用 INSERT TABLE <分区表名> SELECT * FROM <非分区表>。
使用 dexp/dimp 将数据从源表导出,再导入到目标分区表。
下面演示第二种情况,目标表为 dmhr 中的 department 表,department_id 为表的主键列。按 department_id 建立范围分区,并且每个分区对应不同的表空间。
数据准备,示例语句如下:
CREATE TABLE dmhr.dept AS SELECT * FROM dmhr.department;
ALTER TABLE dmhr.dept ADD PRIMARY KEY (department_id);
使用 dexp 工具将源表数据导出,示例语句如下:
dexp dmhr/dmhr20201111@172.16.100.80:5237 FILE=dept.dmp LOG=dexp_dept.log
DIRECTORY=/dm/backup/ TABLES=dmhr.dept
使用 dimp 工具将数据导入目标分区表。由于 DM 数据库目前不支持导入导出表映射,故先 drop 掉源表,然后建立同名的分区表。示例语句如下:
DROP TABLE dmhr.dept;
CREATE TABLE dmhr.dept
(
department_id NUMBER PRIMARY KEY,
department_name VARCHAR (30) NOT NULL,
manager_id INT,
location_id INT
)
PARTITION BY RANGE
(department_id)
(
PARTITION p1 VALUES LESS THAN (400) TABLESPACE tbs_dept_400,
PARTITION p2 VALUES LESS THAN (700) TABLESPACE tbs_dept_700,
PARTITION p3 VALUES LESS THAN (1000) TABLESPACE tbs_dept_1000,
PARTITION pmax VALUES LESS THAN (MAXVALUE) TABLESPACE tbs_dept_1000
)
)
数据导出,示例语句如下:
dimp dmhr/dmhr20201111@172.16.100.80:5237 FILE=dept.dmp LOG=dimp_dept.log
DIRECTORY=/dm/backup/ TABLES=dmhr.dept TABLE_EXISTS_ACTION=truncate IGNORE=Y
查看分区信息,示例语句如下:
SELECT table_name, owner, partitioned FROM dba_tables WHERE table_name=UPPER(‘dept’);
输出结果:
查询分区信息1
SELECT ‘P1’ AS pars, COUNT() AS num FROM dmhr.dept PARTITION (P1)
UNION ALL
SELECT ‘P2’, COUNT() FROM dmhr.dept PARTITION (P2)
UNION ALL
SELECT ‘P3’, COUNT(*) FROM dmhr.dept PARTITION (P3)
UNION ALL
SELECT ‘PMAX’, COUNT(*) FROM dmhr.dept PARTITION (PMAX)
查询错误号:
select * from v$err_info;
修改连接数
修改 dm.ini 里面的 MAX_SESSIONS,SP_SET_PARA_VALUE(2,‘MAX_SESSIONS’,2000),修改完重启数据库。
查看版本
disql -id
–统计页大小
select page;
–通过编码格式
select unicode;
–统计大小写敏感参数
select case_sensitive;
查看实例是否运行中的方式:
ps -ef | grep dmserver
./DmServiceDMSERVER status
./dm_services status DmServiceDMSERVER (144及以后版本,zyj)
达梦服务查看器
最好不要systemctl status DmServiceDMSERVER.service查看,有时候不太准确
查询活动会话数,语句如下所示:
SELECT COUNT(*) FROM V$SESSIONS WHERE STATE=‘ACTIVE’;
已执行超过 2 秒的活动 SQL,语句如下所示:
SELECT* FROM (
SELECT SESS_ID,SQL_TEXT,DATEDIFF(SS,LAST_RECV_TIME,SYSDATE) Y_EXETIME,
SF_GET_SESSION_SQL(SESS_ID) FULLSQL,CLNT_IP
FROM V$SESSIONS WHERE STATE=‘ACTIVE’)
WHERE Y_EXETIME>=2;
锁查询,语句如下所示:
SELECT O.NAME,L.* FROM V$LOCK L,SYSOBJECTS O WHERE L.TABLE_ID=O.ID AND BLOCKED=1;
阻塞查询,语句如下所示:
WITH LOCKS
AS (SELECT O.NAME,L.*,S.SESS_ID,S.SQL_TEXT,S.CLNT_IP,S.LAST_SEND_TIME
FROM V
L
O
C
K
L
,
S
Y
S
O
B
J
E
C
T
S
O
,
V
LOCK L, SYSOBJECTS O, V
LOCKL,SYSOBJECTSO,VSESSIONS S
WHERE L.TABLE_ID = O.ID AND L.TRX_ID = S.TRX_ID),
LOCK_TR
AS (SELECT TRX_ID WT_TRXID, ROW_IDX BLK_TRXID
FROM LOCKS
WHERE BLOCKED = 1),
RES
AS (SELECT SYSDATE STATTIME,T1.NAME,T1.SESS_ID WT_SESSID,S.WT_TRXID,
T2.SESS_ID BLK_SESSID,S.BLK_TRXID,T2.CLNT_IP,
SF_GET_SESSION_SQL (T1.SESS_ID) FULSQL,
DATEDIFF (SS, T1.LAST_SEND_TIME, SYSDATE) SS,
T1.SQL_TEXT WT_SQL
FROM LOCK_TR S, LOCKS T1, LOCKS T2
WHERE T1.LTYPE = ‘OBJECT’
AND T1.TABLE_ID <> 0
AND T2.LTYPE = ‘OBJECT’
AND T2.TABLE_ID <> 0
AND S.WT_TRXID = T1.TRX_ID
AND S.BLK_TRXID = T2.TRX_ID)
SELECT DISTINCT WT_SQL,CLNT_IP,SS,WT_TRXID,BLK_TRXID
FROM RES;
SQL 日志
–设置 SQL 过滤规则,只记录必要的 SQL,生产环境不要设成 1
– 2 只记录 DML 语句 3 只记录 DDL 语句 22 记录绑定参数的语句
– 25 记录 SQL 语句和它的执行时间 28 记录 SQL 语句绑定的参数信息
SELECT SF_SET_SYSTEM_PARA_VALUE(‘SQL_TRACE_MASK’,‘2:3:22:25:28’,0,1);
–同步日志会严重影响系统效率,生产环境必须设置为异步日志
SELECT SF_SET_SYSTEM_PARA_VALUE(‘SVR_LOG_ASYNC_FLUSH’,1,0,1);
–下面这个语句设置只记录执行时间超过 200ms 的语句
SELECT SF_SET_SYSTEM_PARA_VALUE(‘SVR_LOG_MIN_EXEC_TIME’,200,0,1);
–下面的语句查看设置是否生效
SELECT * FROM V
D
M
I
N
I
w
h
e
r
e
p
a
r
a
n
a
m
e
=
′
S
V
R
L
O
G
A
S
Y
N
C
F
L
U
S
H
′
;
S
E
L
E
C
T
∗
F
R
O
M
V
DM_INI where para_name='SVR_LOG_ASYNC_FLUSH'; SELECT * FROM V
DMINIwhereparaname=′SVRLOGASYNCFLUSH′;SELECT∗FROMVDM_INI where para_name=‘SQL_TRACE_MASK’;
SELECT * FROM V$DM_INI where para_name=‘SVR_LOG_MIN_EXEC_TIME’;
–开启 SQL 日志:
SP_SET_PARA_VALUE(1, ‘SVR_LOG’, 1);
–关闭 SQL 日志:
SP_SET_PARA_VALUE(1, ‘SVR_LOG’, 0);
AWR日志
启用系统包和 AWR 包:
CALL SP_INIT_AWR_SYS(1);
CALL SP_CREATE_SYSTEM_PACKAGES(1);
查询 AWR 快照:
SELECT *FROM SYS.WRM$_SNAPSHOT;
设置快照间隔,如果不设置快照间隔,手动执行快照后 SYS.WRM$_SNAPSHOT 视图中没有记录:
CALL DBMS_WORKLOAD_REPOSITORY.AWR_SET_INTERVAL(50);
在两个时间点分别手动创建快照,或者等待系统自动生成:
10:00时创建第一快照:
CALL DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT();
30分钟后再创建一个,10:30,
CALL DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT();
查询 AWR 快照:
SELECT* FROM SYS.WRM$_SNAPSHOT;
创建AWR报告,SYS.AWR_REPORT_HTML(快照ID1,快照ID2,‘AWR报告存放路径’,‘AWR报告名称.HTLM’);:
SYS.AWR_REPORT_HTML(1,2,‘C:’,‘AWR1.HTML’);
JDBC 驱动日志

收集统计信息
方法如下所示:
–收集指定用户下所有表所有列的统计信息:
DBMS_STATS.GATHER_SCHEMA_STATS(‘username’,100,TRUE,‘FOR ALL COLUMNS SIZE AUTO’);
–收集指定用户下所有索引的统计信息:
DBMS_STATS.GATHER_SCHEMA_STATS(‘usename’,1.0,TRUE,‘FOR ALL INDEXED SIZE AUTO’);
–或 收集单个索引统计信息:
DBMS_STATS.GATHER_INDEX_STATS(‘username’,‘IDX_T2_X’);
–收集指定用户下某表统计信息:
DBMS_STATS.GATHER_TABLE_STATS(‘username’,‘table_name’,null,100,TRUE,‘FOR ALL COLUMNS SIZE AUTO’);
–收集某表某列的统计信息:
STAT 100 ON table_name(column_name);
自动收集统计信息
DM 数据库支持统计信息的自动收集,当全表数据量变化超过设定阈值后可自动更新统计信息。
–打开表数据量监控开关,参数值为 1 时监控所有表,2 时仅监控配置表
SP_SET_PARA_VALUE(1,‘AUTO_STAT_OBJ’,2);
–设置 SYSDBA.T 表数据变化率超过 15% 时触发自动更新统计信息
DBMS_STATS.SET_TABLE_PREFS(‘SYSDBA’,‘T’,‘STALE_PERCENT’,15);
–配置自动收集统计信息触发时机
SP_CREATE_AUTO_STAT_TRIGGER(1, 1, 1, 1,‘14:36’, ‘2020/3/31’,60,1);
–函数各参数介绍
SP_CREATE_AUTO_STAT_TRIGGER(
TYPE INT, --间隔类型,默认为天
FREQ_INTERVAL INT, --间隔频率,默认 1
FREQ_SUB_INTERVAL INT, --间隔频率,与 FREQ_INTERVAL 配合使用
FREQ_MINUTE_INTERVAL INT, --间隔分钟,默认为 1440
STARTTIME VARCHAR(128), --开始时间,默认为 22:00
DURING_START_DATE VARCHAR(128), --重复执行的起始时间,默认 1900/1/1
MAX_RUN_DURATION INT, --允许的最长执行时间(秒),默认不限制
ENABLE INT --0 关闭,1 启用 --默认为 1
);
定位慢SQL
开启跟踪日志记录执行 SQL
开启跟踪日志记录执行 SQL
跟踪日志文件是一个纯文本文件,以 dmsql_实例名_日期_时间命名, 默认生成在 DM 安装目录的 log 子目录下。
跟踪日志内容包含系统各会话执行的 SQL 语句、参数信息、错误信息、执行时间等。跟踪日志主要用于分析错误和分析性能问题,基于跟踪日志可以对系统运行状态进行分析。
跟踪日志配置方式
根据需要配置数据文件目录下的 sqllog.ini,如下所示:
BUF_TOTAL_SIZE = 10240 #SQLs Log Buffer Total Size(K)(1024~1024000)
BUF_SIZE = 1024 #SQLs Log Buffer Size(K)(50~409600)
BUF_KEEP_CNT = 6 #SQLs Log buffer keeped count(1~100)
[SLOG_ALL]
FILE_PATH = …/log
PART_STOR = 0
SWITCH_MODE = 1
SWITCH_LIMIT = 100000
ASYNC_FLUSH = 0
FILE_NUM = 200
ITEMS = 0
SQL_TRACE_MASK = 2:3:23:24:25
MIN_EXEC_TIME = 0
USER_MODE = 0
USERS =
配置 dm.ini 中 SVR_LOG = 1 启用 sqllog.ini 配置,该参数为动态参数,可通过调用数据库函数直接修改,如下所示:
SP_SET_PARA_VALUE(1,‘SVR_LOG’,1);
如果对 sqllog.ini 进行了修改,可通过调用以下函数即时生效,无需重启数据库,如下所示:
SP_REFRESH_SVR_LOG_CONFIG();
| 参数名 | 缺省值 | 说明 |
|---|---|---|
| 项目 | Value | |
| -------- | ----- |
| 参数名 | 缺省值 | 说明 |
|---|---|---|
| SQL_TRACE_MASK | 1 | LOG 记录的语句类型掩码,是一个格式化的字符串,表示一个 32 位整数上哪一位将被置为 1,置为 1 的位则表示该类型的语句要记录,格式为:号:位号:位号。如:3:5:7 表示第 3,第 5,第 7 位上的值被置为 1。每一位的含义见下面说明(2~17 前提是:SQL 标记位 24 也要设置):1 全部记录(全部记录并不包含原始语句)2 全部 DML 类型语句3 全部 DDL 类型语句4 UPDATE 类型语句(更新)5 DELETE 类型语句(删除)6 INSERT 类型语句(插入)7 SELECT 类型语句(查询)8 COMMIT 类型语句(提交)9 ROLLBACK 类型语句(回滚)10 CALL 类型语句(过程调用)11 BACKUP 类型语句(备分)12 RESTORE 类型语句(恢复)1314 修改对象操作 (ALTER DDL)15 删除对象操作 (DROP DDL)16 授权操作 (GRANT DDL)17 回收操作 (REVOKE DDL)22 绑定参数23 存在错误的语句(语法错误,语义分析错误等)24 是否需要记录执行语句25 是否需要打印计划和语句和执行的时间26 是否需要记录执行语句的时间27 原始语句(服务器从客户端收到的未加分析的语句)28 是否记录参数信息,包括参数的序号、数据类型和值29 是否记录事务相关事件 |
| FILE_NUM | 0 | 总共记录多少个日志文件,当日志文件达到这个设定值以后,再生成新的文件时,会删除最早的那个日志文件,日志文件的命令格式为 dmsql_实例名_日期时间.log。当这个参数配置成 0 时,只会生成两个日志相互切换着记录。有效值范围(0~1024)。例如,当 FILE_NUM=0,实例名为 PDM 时,根据当时的日期时间,生成的日志名称为:DMSQL_PDM_20180719_163701.LOG,DMSQL_PDM_20180719_163702.LOG |
| SWITCH_MODE | 0 | 表示 SQL 日志文件切换的模式:0:不切换1:按文件中记录数量切换2:按文件大小切换3:按时间间隔切换 |
| SWITCH_LIMIT | 100000 | 不同切换模式 SWITCH_MODE 下,意义不同:按数量切换时,一个日志文件中的 SQL 记录条数达到多少条之后系统会自动将日志切换到另一个文件中。一个日志文件中的 SQL 记录条数达到多少条之后系统会自动将日志切换到另一个文件中。有效值范围(1000 至 10000000)按文件大小切换时,一个日志文件达到该大小后,系统自动将日志切换到另一个文件中,单位为 M。有效值范围(1 至 2000)按时间间隔切换时,每个指定的时间间隔,按文件新建时间进行文件切换,单位为分钟。有效值范围(1 至 30000) |
| ASYNC_FLUSH | 0 | 是否打开异步 SQL 日志功能。0:表示关闭;1:表示打开 |
| MIN_EXEC_TIME | 0 | 详细模式下,记录的最小语句执行时间,单位为毫秒。执行时间小于该值的语句不记录在日志文件中。有效值范围(0 至 4294967294) |
| FILE_PATH | …/log | 日志文件所在的文件夹路径 |
| BUF_TOTAL_SIZE | 10240 | SQL 日志 BUFFER 占用空间的上限,单位为 KB,取值范围(1024 至 1024000) |
| BUF_SIZE | 1024 | 一块 SQL 日志 BUFFER 的空间大小,单位为 KB,取值范围(50 至 409600) |
| BUF_KEEP_CNT | 6 | 系统保留的 SQL 日志缓存的个数, 有效值范围(1 至 100) |
| PART_STOR | 0 | SQL 日志分区存储,表示 SQL 日志进行分区存储的划分条件。0 表示不划分; 1 表示 USER:根据不同用户分布存储 |
| ITEMS | 0 | 配置 SQL 日志记录中的那些列要被记录。该参数是一个格式化的字符串,表示一个记录中的那些项目要被记录,格式为:列号:列号:列号。如:3:5:7 表示第 3,第 5,第 7 列要被记录。0 表示记录所有的列。1 TIME 执行的时间2 SEQNO 服务器的站点号3 SESS 操作的 SESS 地址4 USER 执行的用户5 TRXID 事务 ID6 STMT 语句地址7 APPNAME 客户端工具8 IP 客户端 IP9 STMT_TYPE 语句类型10 INFO 记录内容11 RESULT 运行结果,包括运行用时和影响行数(可能没有) |
| USER_MODE | 0 | SQL 日志按用户过滤时的过滤模式,取值0:关闭用户过滤1:白名单模式,只记录列出的用户操作的 SQL 日志2:黑名单模式,列出的用户不记录 SQL 日志 |
| USERS | 空串 | 打开 USER_MODE 时指定的用户列表。格式为:用户名:用户名:用户名 |
根据跟踪日志查找慢 SQL
配置成功后可在 dmsql 指定目录下生成 dmsql 开头的 log 日志文件。日志内容如下所示:
上图中选中记录执行 SQL 语句为:
select * from t1 left join t2 on t1.c1=t2.c1 and t1.c1=999933;
SQL 语句执行时间为 33.815 秒。
可以通过正则表达式在 dmsql 日志文件中查找执行时间超过一定阈值的 SQL 语句。例如:查找执行时间超过 10 秒的 SQL 语句。
[1-9][0-9][0-9][0-9]0-9
如需进行更为系统全面的分析,可使用 Dmlog 工具对 SQL 进行分类汇总。
Dmlog 工具下载:Dmlog_DM7_v5.1.jar
使用说明介绍:Dmlog 小工具使用简要.pdf
通过系统视图查看执行慢 SQL
DM 数据库提供系统动态视图,可自动记录执行时间超过设定阈值的 SQL 语句。
SQL 记录配置
当 INI 参数 ENABLE_MONITOR=1、MONITOR_TIME=1 打开时,显示系统最近 1000 条执行时间超过预定值的 SQL 语句。默认预定值为 1000 毫秒。可通过 SP_SET_LONG_TIME 系统函数修改,通过 SF_GET_LONG_TIME 系统函数查看当前值。
–两个参数均为动态参数,可直接调用系统函数进行修改
SP_SET_PARA_VALUE(1,‘ENABLE_MONITOR’,1);
SP_SET_PARA_VALUE(1,‘MONITOR_TIME’,1);
注意
通过 SP_SET_PARA_VALUE 方式修改的参数值仅对当前会话以及新建会话生效,对其它已建立会话不生效。
查询方式
超过执行时间阈值的 SQL 语句记录在 V$LONG_EXEC_SQLS 系统视图中。
查询该视图获取结果,如下所示:
SELECT * FROM V$LONG_EXEC_SQLS;
慢 SQL 系统视图
各字段详细信息介绍
列名 说明
SESS_ID 会话 ID,会话唯一标识
SQL_ID 语句 ID,语句唯一标识
SQL_TEXT SQL 文本
EXEC_TIME 执行时间(毫秒)
FINISH_TIME 执行结束时间
N_RUNS 执行次数
SEQNO 编号
TRX_ID 事务号















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









