






我对转贴的信息一直有敌意,原因如下:首先,除了制造更多的信息垃圾,转贴不会带来新的价值,想收藏的话一个链接足矣;其次,将错误信息以讹传讹,混淆视听。不妨选一个典型的例子说明一二。
相信《关于Java堆与栈的思考》这个帖子大家并不陌生,转载量极大。但内容如何呢?我就试着分析一下。说明:以下内容,黑色字体为引用别人的帖子,红色字体是我的分析,蓝色字体是引用相关文献。
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
与C++不同,对于堆来说是有道理的。但C++的栈也是由编译器负责安排和布局的,这和java没什么区别。其实,java里提到的堆和栈应该是逻辑层面上的,是jvm划分的,并不同于C++的实际运行时内存,因此根本不是一个层面上的东西,最好不要进行比较。
2. 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
在逻辑上看,可以认为栈比堆快,但是请不要和寄存器比。上面已经提到,java所谓的堆和栈是逻辑上的,《The Java Virtual Machine Specification》中,将运行时数据区分为pc寄存器、java虚拟机栈、堆、方法区、运行时常量池、本地方法栈共6个部分,而CPU中的寄存器是物理实体。
比如java执行一个加法操作,逻辑上看是读取栈顶的两个数据,执行加法,将结果写回栈顶,但实际的代码经过jvm jit编译之后很可能就是在寄存器中执行加法。因此逻辑意义上的比较根本没有什么价值。
"栈数据可以共享",这个说法是该帖子"创造性"的提出来的。翻遍所有的java 资料,根本找不到这样的说法(现在看来,也不全是,国内已经有书籍将这个帖子完全照搬了,抄袭可耻!貌似有本《java程序员面试宝典》,看过的都知道,呵呵)。
3. Java中的数据类型有两种。
一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。
这里混淆了一个问题。首先要知道什么是字面值,所谓的字面值是形如1,3,2.0,2.0f,'c',"Hello"这样的形式出现的常量。基本类型变量里存的是什么?值。存到变量中就不存在"字面值"一说了!"如int a = 3; 这里的a是一个指向int类型的引用",这个例子就太不恰当了,我们要注意的是,int a = 3;我们得到的是一个空间,里面存的是3这个数。这里又"int类型的引用"云云,岂不缪哉?
-
这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
基本类型的变量存在栈里或者堆里不是由"大小可知,生存期可知"就能确定了。关键是上下文。
比如
void func(){
int a = 3;
}
这自然是存在栈里的。
而
class Test{
int a = 3;}
这就肯定是随对象放到堆里的。
因此,不要孤立的看到基本类型就说放到栈里,看到引用类型就说放到堆里。区分引用变量和对象本身特别重要,这个下面再说。
另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。这段就特别离谱了。首先我们要知道基本类型的变量里存的是什么。参考《The Java Language Specification》:Primitive values do not share state with other primitive values. A variable whose type is a primitive type always holds a primitive value of that same type.也就是说基本类型的变量中存放的就是该基本类型的值。
下面我们再看那栈中变量是如何存储的。Java是将所有的局部变量按数组的方式编号存储的。其中,一个int,float占该数组中的1项,一个long,double变量占数组的两项,引用变量占1项。其余byte、char、short等得不到jvm承认的就按int处理了。
看一个实际的例子:
public class Main {
public static void main(String[] args){
int i = 3;
int j = 3;
int p = 10;
int q = 10;
Object o = new Object();
char c = 'c';
double d = 1;
int m = 10;
}
}
javap -c Main,反汇编处理:
public static void main(java.lang.String[]);
Code:
0: iconst_3
1: istore_1
2: iconst_3
3: istore_2
4: bipush 10
6: istore_3
7: bipush 10
9: istore 4
11: new #2; //class java/lang/Object
14: dup
15: invokespecial #1; //Method java/lang/Object."":()V
18: astore 5
20: bipush 99
22: istore 6
24: dconst_1
25: dstore 7
27: bipush 10
29: istore 9
31: return
}
其实反汇编之后可以看出,程序中的变量名已经不存在了,代码中是按变量在局部变量数组中的索引来处理的(学过编译的同学应该很容易明白)。这里main函数的栈帧(Frame)里局部变量的内存布局是:
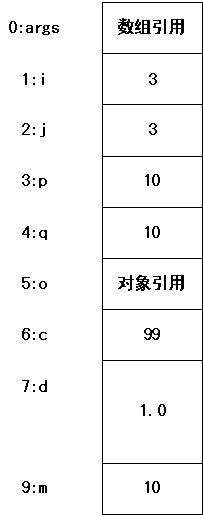
字节码中的istore后的参数指定存储的目标位置索引。
容易看出,即使两个变量存储的数据是相同的,它们也是各自存储自己的变量值,互不干涉。比如对p和q的操作是:
4: bipush 10 //将常数10放到栈顶
6: istore_3 //将栈定的10存入栈变量数组的第三个位置(即p)
7: bipush 10 //同上,同样存储的是10
9: istore 4
当然还有最后的m,也是存储的10。并不是"由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。"
不过必须指出的是,的确存在数据共享的情形。当然,所谓的共享是指编译器在生成class文件时的数据共享。比如下面的例子:
public class Main {
public static void main(String[] args){
int b1 = 64;
int b2 = 64;
int s1 = 128;
int s2 = 128;
int i1 = 65536;
int i2 = 65536;
double d1 = 15;
double d2 = 15;
}
}
反汇编:
public static void main(java.lang.String[]);
Code:
0: bipush 64
2: istore_1
3: bipush 64
5: istore_2
6: sipush 128
9: istore_3
10: sipush 128
13: istore 4
15: ldc #2; //int 65536
17: istore 5
19: ldc #2; //int 65536
21: istore 6
23: ldc2_w #3; //double 15.0d
26: dstore 7
28: ldc2_w #3; //double 15.0d
31: dstore 9
33: return
b1=64<128,我们用1个字节就可以存储这个数了,所以直接用bipush指令+操作数64,该指令一共占2个字节。64<s1=128<65536,常数128两个字节可以表示,因此这里生成的指令是sipush+操作数128,指令占3个字节。而到了65536的时候是如何处理的呢?编译器将它放到了常量池表里,这样编译器生成的class文件中,读取65536这个常数时,只需要1条读取指令和1个1字节的索引,共2个字节。如果直接存这个数的话,我们需要的是加载指令+四个字节操作数。当这个数多次出现时,通过索引进行操作的方式就可以较好的节省操作数所占的字节数(空间)。这样最大的好处就是能有效的减少class文件的大小。
同理,当处理double类型数据的时候,常数15.0d也是放入常量池里的,这样读取常数进行赋值时,读取指令只用了3个字节(ldc2_w #3;操作符1个字节,操作数2个字节,如果直接将15.0这个double常数放到指令中的话,单操作数就占去8个字节)。意义上面已经说明。
注意:不要把我说的共享和原贴所谓的共享混起来。我说的共享是class文件中字面量常数的共享,而变量是独立的、互不影响的,重复一遍,就是double d1 = 15.0;double d2 = 15.0,d1和d2都存的都是15.0,互不影响,但用来初始化它们的参数在class文件中只保存了一份。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
4. String是一个特殊的包装类数据。即可以用String str = new String("abc");的形式来创建,也可以用String str = "abc";的形式来创建(作为对比,在JDK 5.0之前,你从未见过Integer i = 3;的表达式,因为类与字面值是不能通用的,除了String。而在JDK 5.0中,这种表达式是可以的!因为编译器在后台进行Integer i = new Integer(3)的转换)。前者是规范的类的创建过程,即在Java中,一切都是对象,而对象是类的实例,全部通过new()的形式来创建。Java中的有些类,如DateFormat类,可以通过该类的getInstance()方法来返回一个新创建的类,似乎违反了此原则。其实不然。该类运用了单例模式来返回类的实例,只不过这个实例是在该类内部通过new()来创建的,而getInstance()向外部隐藏了此细节。那为什么在String str = "abc";中,并没有通过new()来创建实例,是不是违反了上述原则?其实没有。对于Integer i = 3;编译器并不是进行了Integer i = new Integer(3)这样的转换,而是这样处理:
Integer i = Integer.valueOf(3);
为什么要这样处理呢?因为Java的设计者们有以下考虑(《The Java Language Specification》):
Ideally, boxing a given primitive value p, would always yield an identical reference.[理想的情况下,将一个基本类型值p装箱,总是得到一个同样的引用〕 In practice, this may not be feasible using existing implementation techniques. The rules above are a pragmatic compromise. The final clause above requires that certain common values always be boxed into indistinguishable objects. The implementation may cache these, lazily or eagerly.
因技术手段所限,于是有了这样的规定:
If the value p being boxed is true, false, a byte, a char in the range /u0000 to /u007f, or an int or short number between -128 and 127, then let r1 and r2 be the results of any two boxing conversions of p. It is always the case that r1 == r2.
也就有了这样的现象:
Integer i = 3;
Integer j = 3;
System.out.println(i==j);
打印true。
而
Integer i = 128;
Integer j = 128;
System.out.println(i==j);
打印false。
至于实现,有兴趣的可以参考Integer 类中public static Integer valueOf(int i)方法。
关于这一点,有些人也给出了好玩的结论,比如说我上面的这个例子,他们说当变量在-128~127时,比较的是对象的值,而此范围之外是比较的是对象的地址。麻烦不?
5. 关于String str = "abc"的内部工作。Java内部将此语句转化为以下几个步骤:
(1)先定义一个名为str的对String类的对象引用变量:String str;
(2)在栈中查找有没有存放值为"abc"的地址,如果没有,则开辟一个存放字面值为"abc"的地址,接着创建一个新的String类的对象o,并将o的字符串值指向这个地址,而且在栈中这个地址旁边记下这个引用的对象o。如果已经有了值为"abc"的地址,则查找对象o,并返回o的地址。
(3)将str指向对象o的地址。
值得注意的是,一般String类中字符串值都是直接存值的。但像String str = "abc";这种场合下,其字符串值却是保存了一个指向存在栈中数据的引用!这段讲解问题是比较严重的。String具体是如何处理的呢?前面通过大于65535的int值和一般的double值已经说明了class文件中数据共享的原理,String的处理也是一样的。javac对.java文件进行处理,最后生成Class文件的字节码表示时,会同时生成一个常量池结构。在将数据放入常量池时,会对重复的数据进行过滤(其实是一个Map),保证值保存一份。这一点可以参考OpenJDK中javac的实现,常量池的代码在openjdk/langtools/src/share/classes/com/sun/tools/javac/jvm/Pool.java中,看一下put方法的实现就都清楚了。
我们可以通过分析class文件证明这些常量的唯一性,例如:
public class Main {
public static void main(String[] args){
double d1 = 15;
double d2 = 15;
String s1 = "Hello World!";
String s2 = "Hello World!";
}
}
反汇编:
public static void main(java.lang.String[]);
Code:
0: ldc2_w #2; //double 15.0d
3: dstore_1
4: ldc2_w #2; //double 15.0d
7: dstore_3
8: ldc #4; //String Hello World!
10: astore 5
12: ldc #4; //String Hello World!
14: astore 6
16: return
常数15.0在常量池的第二项,而常量String "Hello World!"在常量池的第4项。可以通过javap -verbose 类名,得到常量池的信息。
需要注意的是class文件中的常量池是静态信息,类加载的时候jvm会根据这个常量池的信息在内存中真正建立起常量池结构。
那常量池中的String对象"Hello World!"是何时创建的呢?我们再来看《Java Virtual Machine Specification 》:
- Loading of a class or interface that contains a String literal may create a new String object (§2.4.8) to represent that literal. This may not occur if the a String object has already been created to represent a previous occurrence of that literal, or if the String.intern method has been invoked on a String object representing the same string as the literal.
-
To derive a string literal, the Java virtual machine examines the sequence of characters given by the CONSTANT_String_info structure.
- If the method String.intern has previously been called on an instance of class String containing a sequence of Unicode characters identical to that given by the CONSTANT_String_info structure, then the result of string literal derivation is a reference to that same instance of class String.
- Otherwise, a new instance of class String is created containing the sequence of Unicode characters given by the CONSTANT_String_info structure; that class instance is the result of string literal derivation. Finally, the intern method of the new String instance is invoked.
通过上面的说明,我们知道类加载之后,常量池中已经创建好了字符串常量对象。
在我们的例子中就是,加载Main类的时候,创建了"Hello World!"所表示的字符串对象。因此,执行到String s1 = "Hello World!"; String s2 = "Hello World!";不过把通过#2解析出的字符串常量对象的引用赋给s1和s2。
综上可知,字符串字面中的常量数据是保存在常量池中的。相同的内容也没有帖子中所谓的栈查找过程,当然就更没有所谓的"栈地址旁边记录引用" 之类的东东了。
原帖中又弄了一大堆例子试图说明"栈数据共享"这个论断,这里就不一一引用了。
还有一点需要交代一下,常量池在内存中的Perm区,这里一般不会被垃圾回收器打扰的。所以,不要认为对常量字符串的引用不存在了之后它就会被回收了。
6. 数据类型包装类的值不可修改。不仅仅是String类的值不可修改,所有的数据类型包装类都不能更改其内部的值。
7. 结论与建议:
(1)我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,我们创建了String类的对象str。担心陷阱!对象可能并没有被创建!唯一可以肯定的是,指向String类的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑,除非你通过new()方法来显要地创建一个新的对象。因此,更为准确的说法是,我们创建了一个指向String类的对象的引用变量str,这个对象引用变量指向了某个值为"abc"的String类。清醒地认识到这一点对排除程序中难以发现的bug是很有帮助的。
这里总结的不错。说到这简单提一下,其实很多书上经常将对象和引用混在一起。比如说Object obj = new Object();说obj是个对象云云。我感觉这是个很坏的习惯。按照《The Java Language Specification》上的说明:
There are two kinds of types in the Java programming language: primitive types (§4.2) and reference types (§4.3). There is also a special null type, the type of the expression null, which has no name.
在初学时就自然的把变量分为两种(基本类型变量和引用类型变量)是再好不过的了。我们也不用费力的去分析==和equals()什么关系。因为很自然,==就是比较变量的"值",基本类型变量存的就是数据值,数据相等就可以确定"=="为 true,而引用类型存的是可以找到对象的信息(一般的jvm实现中都将引用作为一个指针,起码SUN和IBM的虚拟机都是这么处理的,可以参考相关资料,这种意义下就可以认为引用保存的是地址值),如果两个引用变量的"值"能让我们找到同一个对象,那它们的"=="也为true。
(2)使用String str = "abc";的方式,可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。这个思想应该是享元模式的思想,但JDK的内部在这里实现是否应用了这个模式,不得而知。
String str = new String("abc");千万不要这样写代码!
(3)当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==。
(4)由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。
虽然分析基本错误,但原帖中的结论是比较有价值的。
我这里只是以《关于java栈与堆的思考》为例说明一个现象,就是错误的知识因转载和共享也会成为大多数人认定的真理。类似的还有很多很多这样形成的"真理",比如:
《Java关键字final、static使用总结》中有一句话,注意:父类的private成员方法是不能被子类方法覆盖的,因此private类型的方法默认是final类型的。
想不明白这个因为所以怎么推出来的,本来不相关的两个概念。
有一个帖子《如何优化JAVA程序开发,提高JAVA性能》,对性能分析给出了很多好的建议,但使用String类型举例子,结果带来了很多错误的证据。
还有一个耳熟能详的说法,"如果自己不定义构造方法,编译器自动提供一个public的缺省构造方法",谁说一定是public的呢?
再比如,"一个引用变量不用了之后,使用obj = null;是个好习惯",了解GC的话,这并不是什么好习惯。可以参考http://developers.sun.com/learning/javaoneonline/2007/pdf/TS-2906.pdf。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









