







总结一下前几天使用python的pyspider框架爬美食的过程
事前准备 :
python的pysipder框架.
爬取思路 :
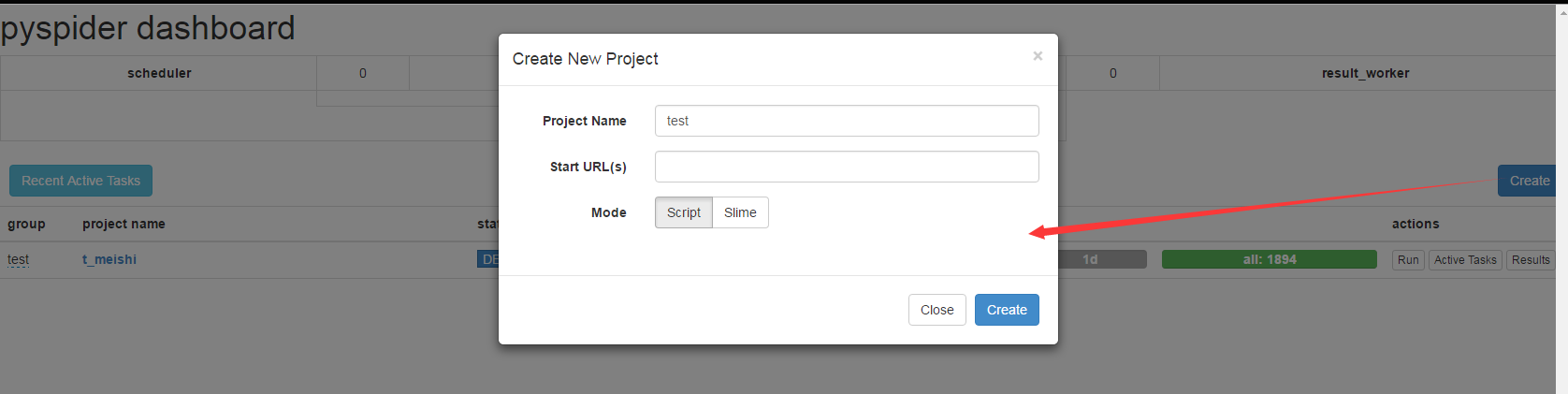
在pyspider创建一个项目
点create后进入到pyspider的代码面板
左边是调试信息,右边是代码编辑区
选择爬取网站.就以美食网为例子
http://www.ttmeishi.com/CaiXi/JiaChangCai/
选择列表页on_start方法是pyspider的入口,我们在
crawl当中填写需要爬取的网页
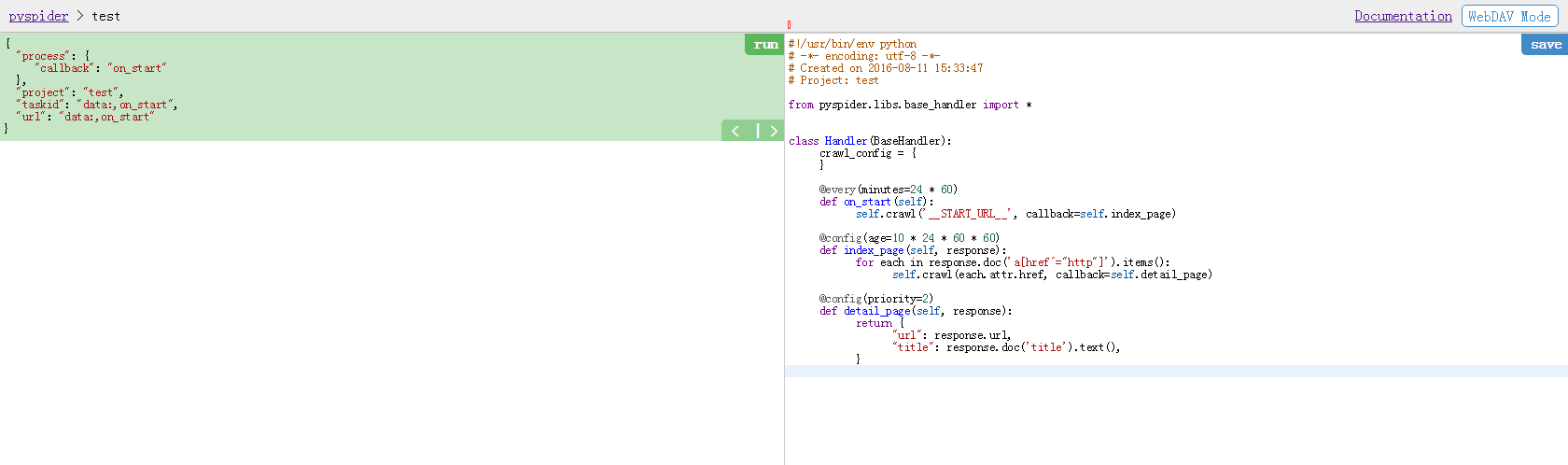
def on_start(self):
self.crawl('http://www.ttmeishi.com/CaiXi/JiaChangCai/', callback=self.index_page)第一个参数是要爬取的url,第二个参数callback是回调方法.在访问url后调起index_page
后面的先不管,save代码,点击run .看一下效果
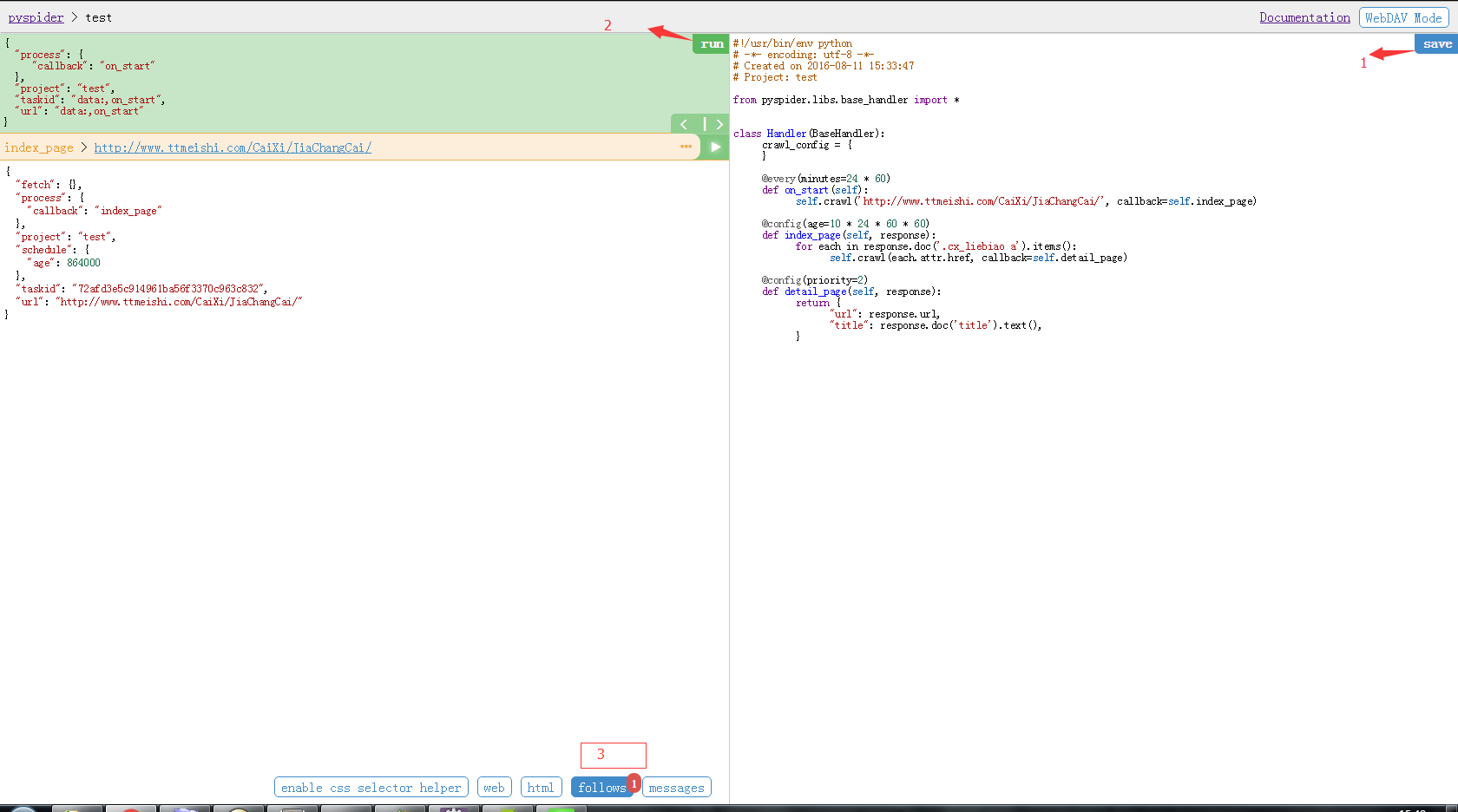
可以看到follows中有一条记录.点击左侧连接的绿箭头,进入下一步.也就是index_page方法.
def index_page(self, response):
for each in response.doc('.cx_liebiao a').items():
self.crawl(each.attr.href, callback=self.detail_page)response.doc里面填要寻找的标签或者样式等.我们可以使用浏览器自带的debug工具
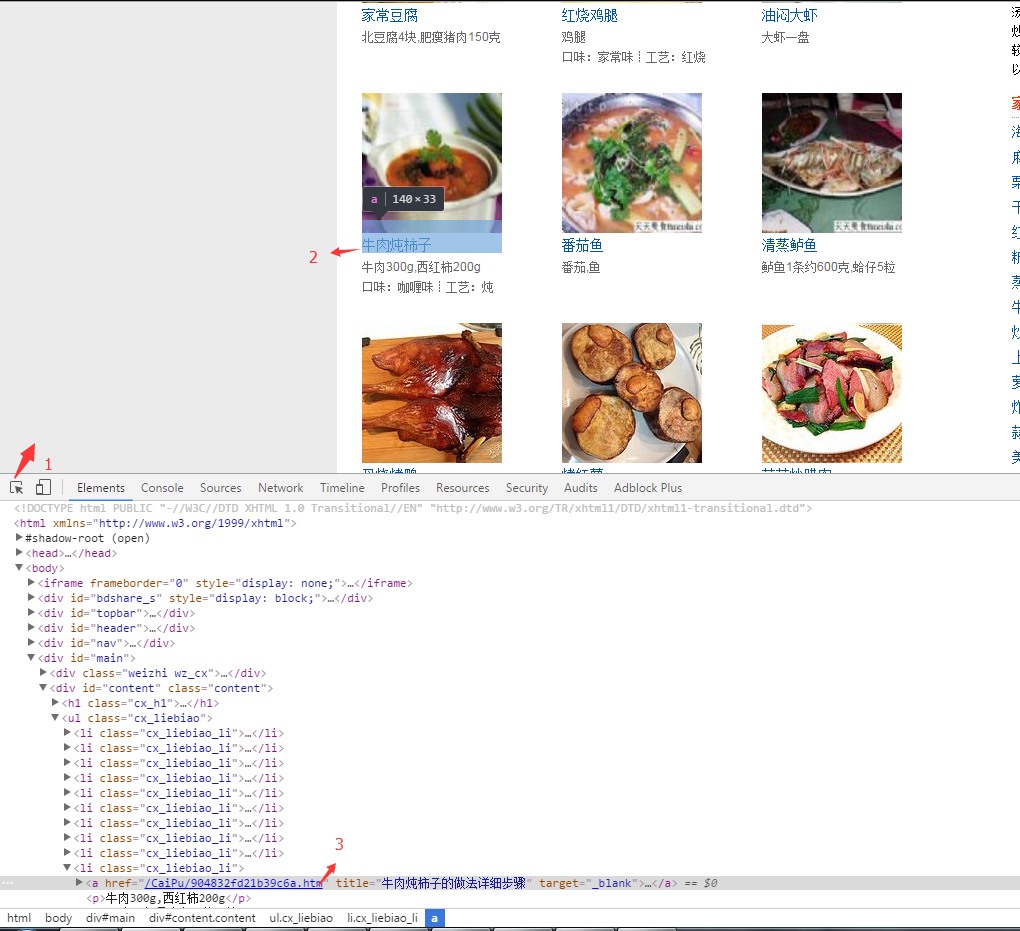
可以看到详细的链接在content的div下面的li下的a标签.选择器可以这样写
response.doc('.content li > a').items()也可以这样写
response.doc('.cx_liebiao a').items()写法多种多样,目的相同,具体更详细的使用需要进一步学习.
上面说了使用浏览器自己寻找, 现在说说更加省事的方法.pyspider自带的样式选择器辅助工具
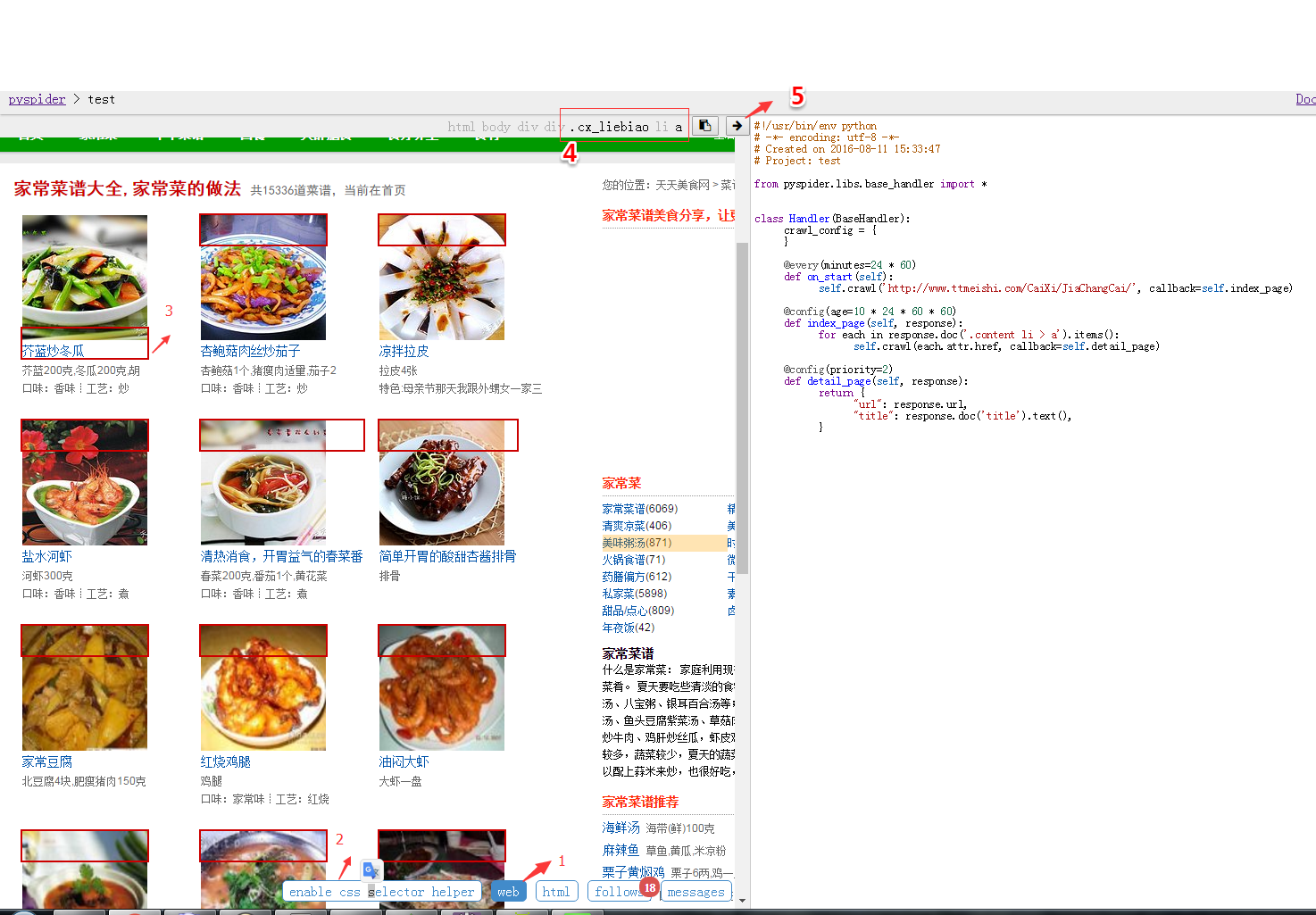
工具帮助我们选择,我们只需要将最后的代码填进去就可以了,是不是很方便.
在点击run试试效果.
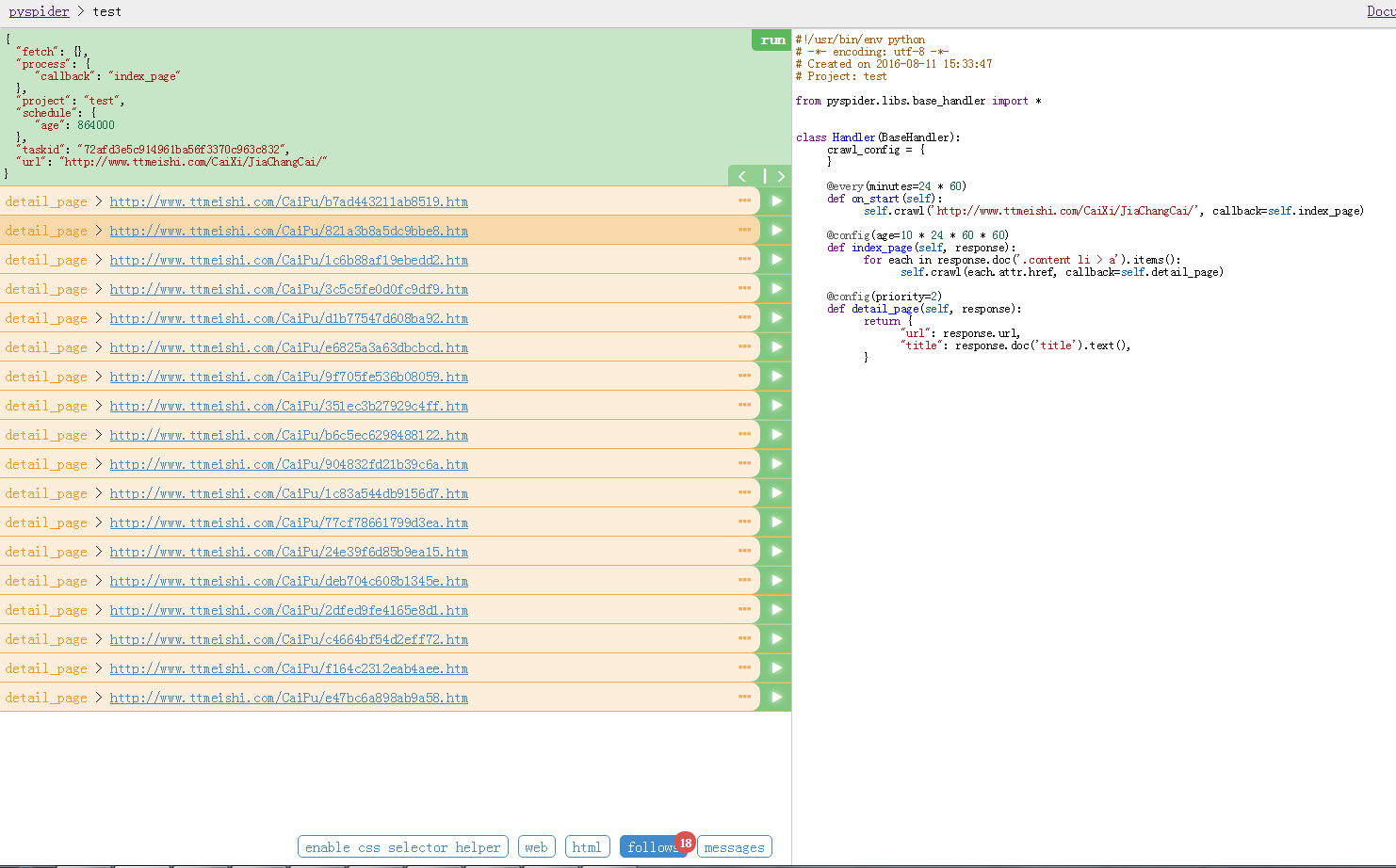
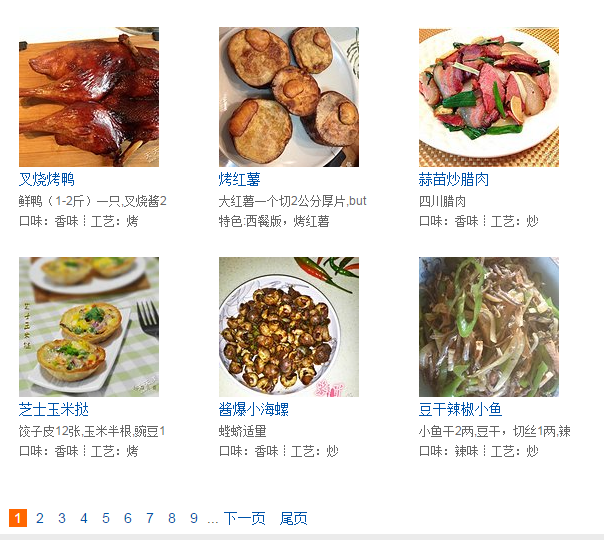
列表页的详细内容链接已经整齐排列出来了.接下来选择一个链接点击率箭头进入
detail_page方法.detail_page中结息详细页面内容,目前只返回了源url和title.
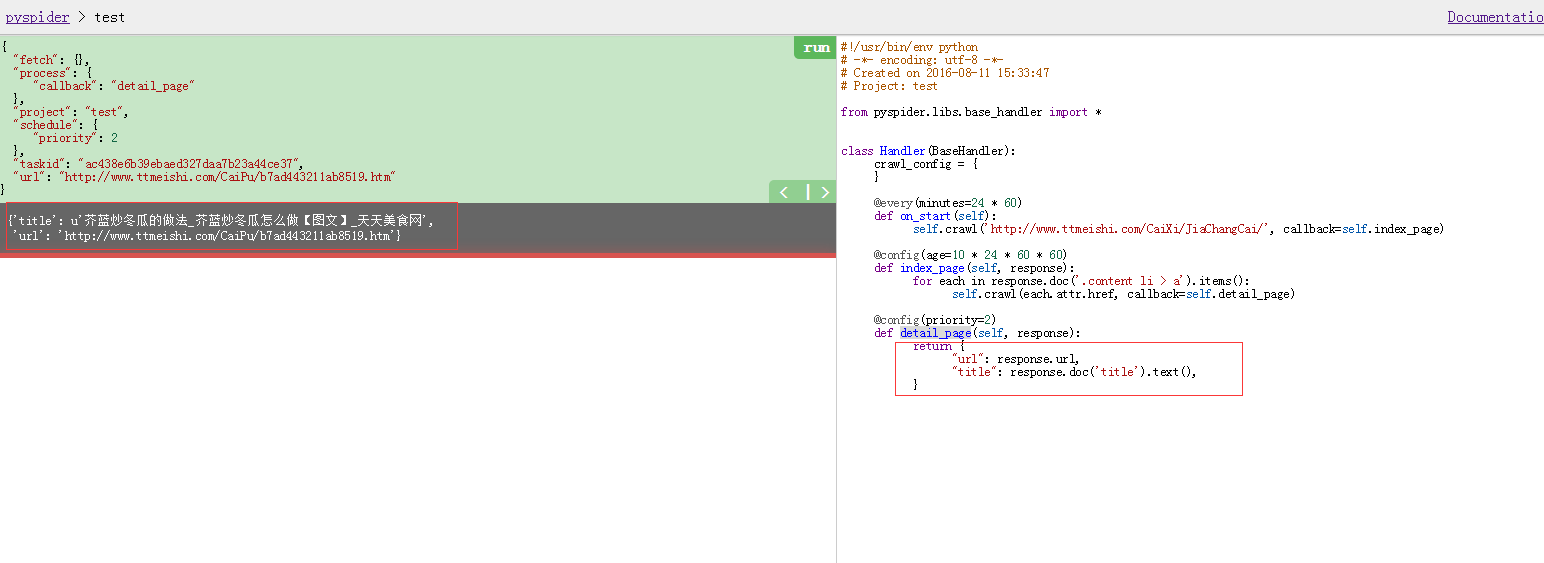
数据整理 :
然而这么点内容不是我们所期望的.我们想要的是这样的内容:
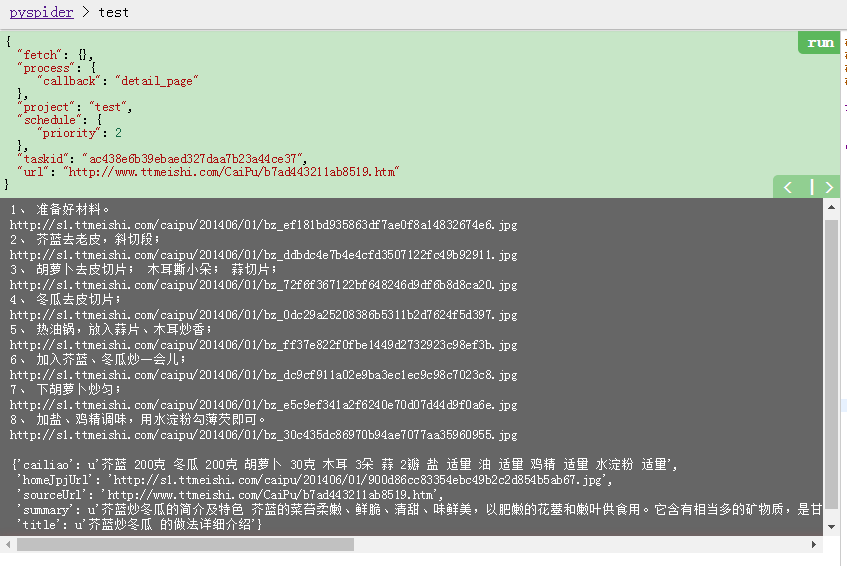
整理数据其实就是重复上面的工作,找到想要的内容,选择样式,获取内容.
后续 :
内容获取到了,接下来是需要将数据落地.我选择存储在数据库,以方便后面前台页面显示
入库的内容放在下一篇介绍
最后
附上代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2016-08-11 15:33:47
# Project: test
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.ttmeishi.com/CaiXi/JiaChangCai/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('.content li > a').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
imgs = response.doc('.c_bz_img img').items()
contexts = response.doc('.c_bz_neirong').items()
try:
while contexts:
print contexts.next().text()
print imgs.next().attr.src
except StopIteration as e:
print e
return {
"title" : response.doc('.content h1').text()+"",
"summary" : response.doc('.c_jianjie').text()+"",
"cailiao" : response.doc('.c_leibie .c_leibie_sc').text()+"",
"sourceUrl" : response.url,
"homeJpjUrl": response.doc('.c_img_show1 img').attr.src,
}















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









