










缓存全景图
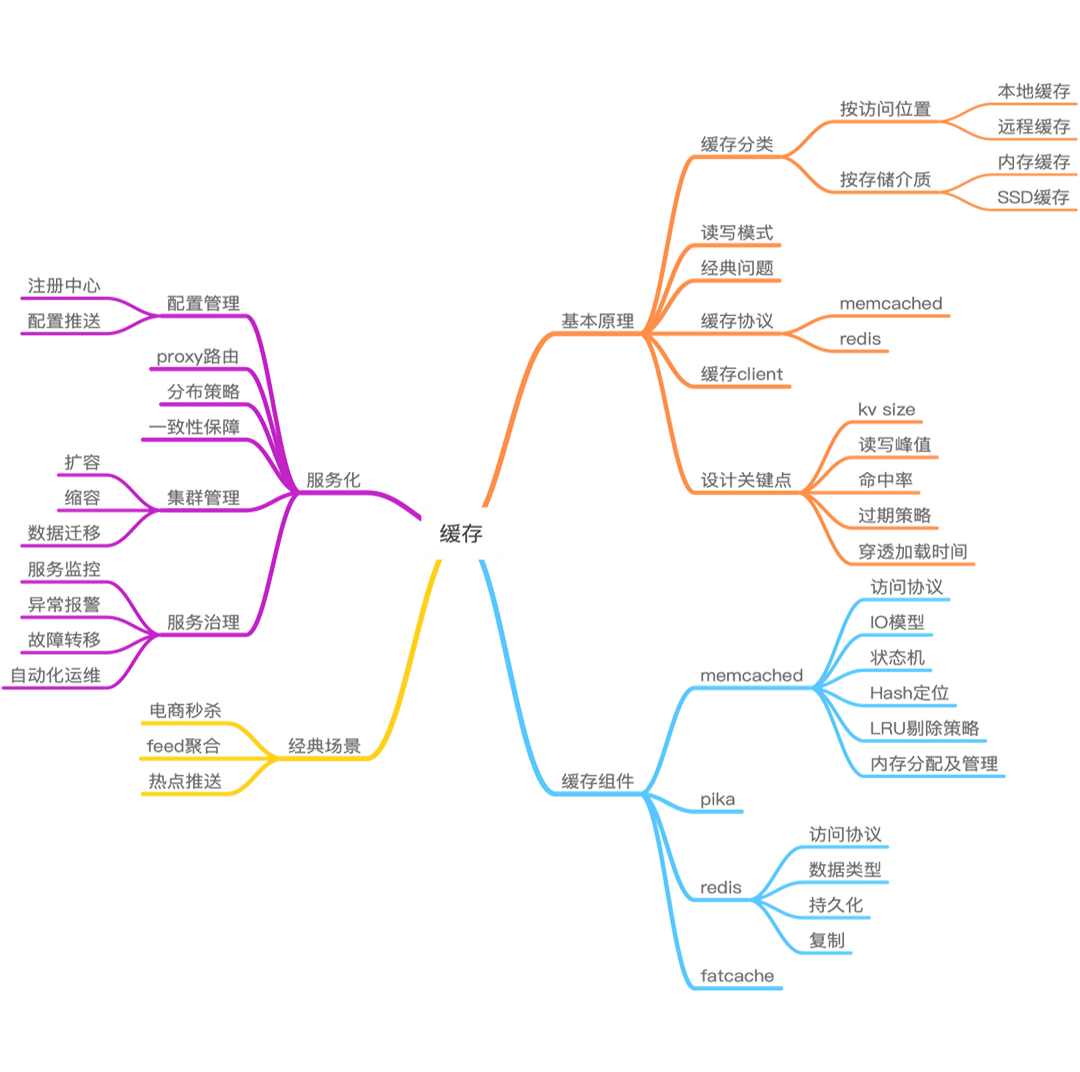
一、缓存的定义
-
狭义缓存:起源于硬件层面,指 CPU 内部或与 CPU 紧密耦合的快速存储——静态 RAM(SRAM),用于加速对主存(DRAM)的数据交换。
-
广义缓存:凡是能提升数据访问速度的软硬件层次均可称作缓存,如操作系统的页缓存、应用层的
Redis、Memcached等中间件。
存在意义:当原始数据获取代价过高时,开辟高速缓冲区存储热点数据,借助“近水楼台”效应,实现更快的访问。
二、缓存的基本思想
缓存构建围绕三大核心原则展开:
-
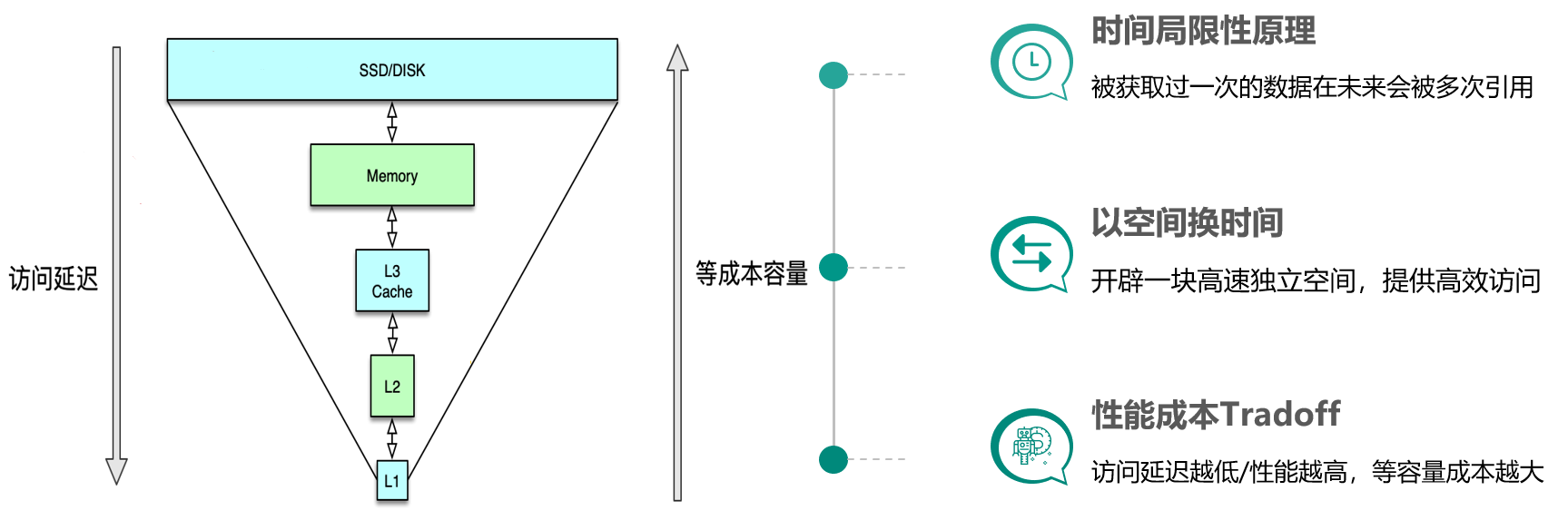
时间局限性原理
- 热点数据“读一次、用多次”。
- 典型场景:一条热门微博,初次加载后会被大量用户继续阅读。
-
空间换时间
- 用高性能存储(内存、SSD Cache 等)为热点数据提供专属访问通道。
-
性能—成本 Tradeoff
- 高性能存储成本居高不下;容量与延迟、吞吐之间需权衡。
- 例如:同等预算下,SSD 容量可比内存大 10~30 倍,但读写延迟却高 50~100 倍。
三、缓存的优势
-
提升访问性能
- 毫秒级甚至微秒级读取,显著优于传统数据库。
-
降低网络拥堵
- 缓存中多为中间结果或聚合后的小体量数据,减少远程查询流量。
-
减轻后端负载
- 缓解数据库和计算服务压力,缩短端到端处理链路。
-
增强可扩展性
- 缓存层可横向扩容,应对突发及持续高并发场景。
四、缓存的代价
-
系统复杂度上升
- 设计、部署与运维都需额外考虑缓存层的拓扑、路由、监控与故障恢复。
-
硬件/运维成本提高
- 内存或高速存储资源单价高,且需维持多副本与高可用。
-
数据一致性挑战
- 多副本/多层缓存带来脏读、过期、丢失更新等风险;
- 缓存与数据库双写或回源逻辑设计不当,易造成“读脏”、“写不全”等问题。
五、实例对比:数据库 vs. 缓存
| 指标 | MySQL 单实例 | Memcached/Redis |
|---|---|---|
| 读写 QPS | 3 000–6 000 | 10⁵–10⁶ |
| 单次访问延迟 | 10–100 ms | < 1 ms |
| 并发扩展能力 | 纵向扩展受限 | 横向扩展灵活,分片/集群 |
若一个请求需聚合 20 条记录,单依赖 DB 访问耗时可达数百毫秒;使用缓存后,即便是百条并发访问,也可在毫秒级内完成。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











