








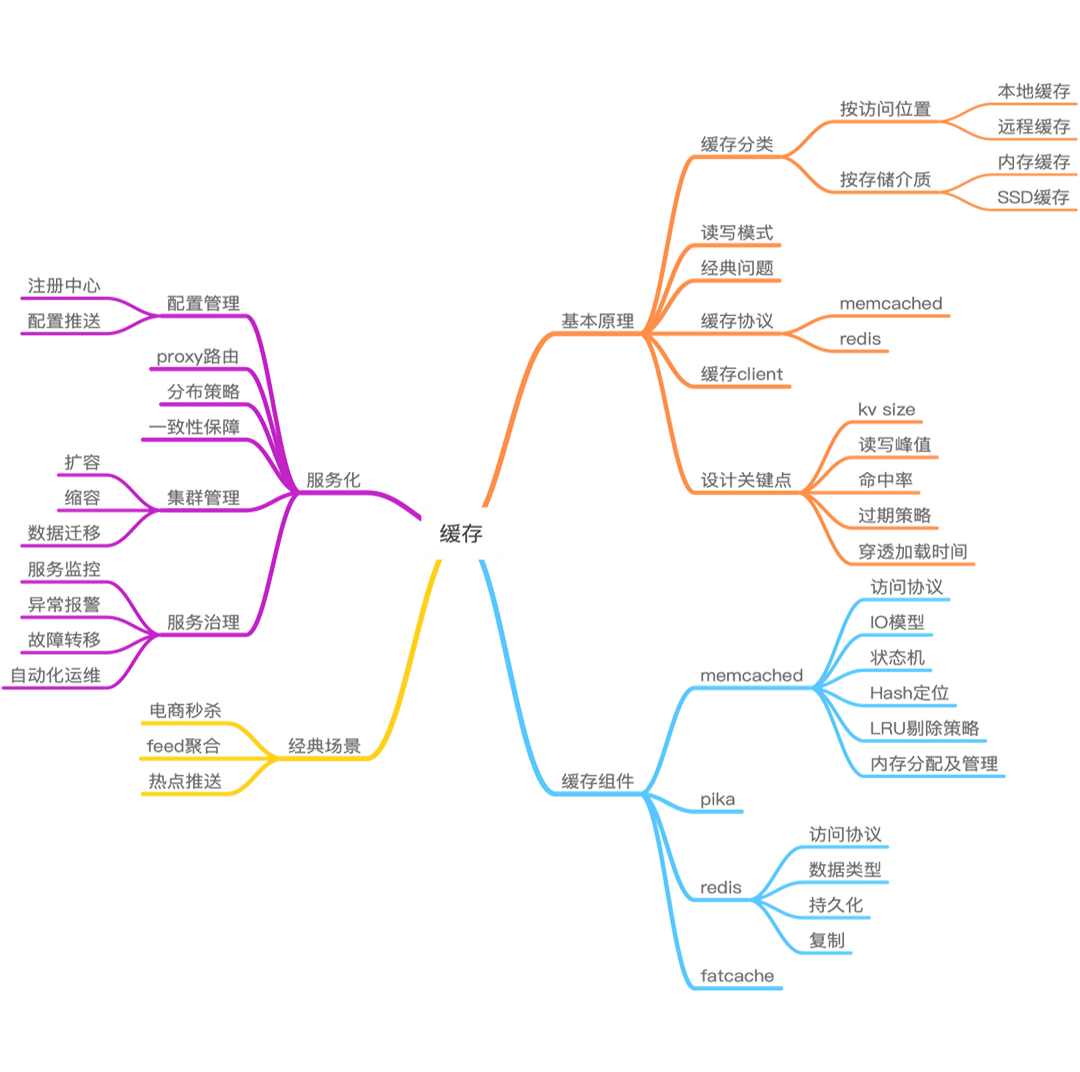
缓存全景图
Pre
分布式缓存:缓存设计中的 7 大经典问题_缓存失效、缓存穿透、缓存雪崩
分布式缓存:缓存设计中的 7 大经典问题_数据不一致与数据并发竞争
一、Hot Key
1. 问题描述
当某个缓存 Key 被短期内海量请求集中访问时,即成为“Hot Key”。此时请求流量高度聚焦于单一节点,极易导致该节点的网络带宽、CPU、连接数等资源饱和,出现卡顿甚至宕机。
2. 原因分析
- 流量骤增:突发热点事件让数十万、百万级请求瞬间命中同一 Key。
- 单点瓶颈:缓存集群根据哈希算法将该 Key 分配到单一节点,未做分流处理。
- 资源限制:物理网卡和 CPU 无法承受瞬态高并发,导致响应时延剧增。
3. 业务场景
- 突发新闻/社交热点:名人绯闻、重大事件爆发后,用户同时刷取同一条信息。
- 大促活动:“双11”“618”秒杀商品详情页缓存瞬时落空。
- 重要节庆实时数据:奥运赛事比分、春节红包活动等。
4. 解决方案
-
热 Key 分片
- 将单一 Key 名称拆分为
hotkey#1…hotkey#N,写入与读取时随机或轮询选择后缀; - 请求均摊到 N 个缓存节点上,显著降低单点压力。
- 将单一 Key 名称拆分为
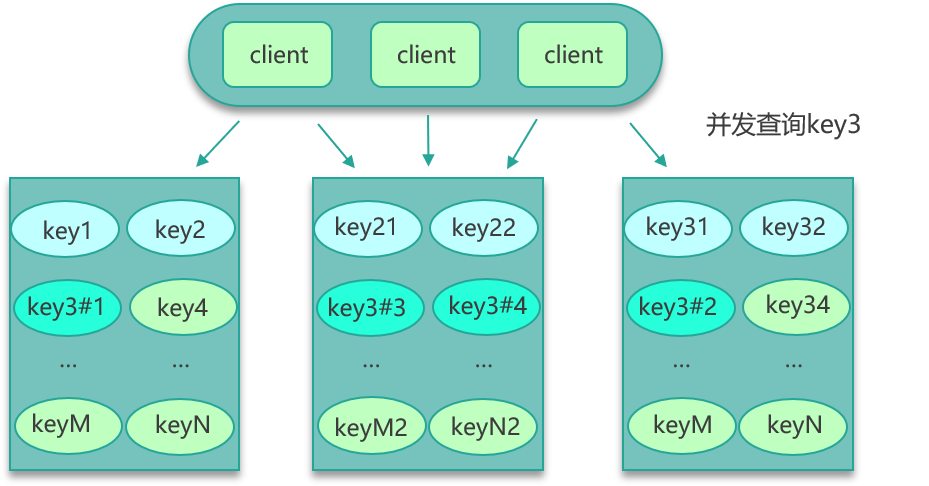
-
多副本+多级缓存
- 对热点 Key 提前部署多副本,或在本地(JVM/C)+分布式两级缓存组合中均存一份;
- 读请求先命中本地缓存,未命中再访问远程,极大减少网络调用。
-
动态扩容与监控
- 通过监控系统实时感知热点 Key 的 QPS 与响应时延;
- 触发自动扩容(增加实例或水平扩展缓存槽位),缓解压力峰值。
-
客户端本地缓存
- 将热点数据短期缓存在客户端(内存或轻量级本地存储);
- 频繁访问直接就地命中,减少对远程缓存的打击。
二、Big Key
1. 问题描述
当某个 Key 对应的 Value 体积过大(如几 MB 级别或元素数万级的集合),在读写、网络传输或序列化/反序列化时容易超时或阻塞,严重拖慢缓存组件。
2. 原因分析
- 内存分配碎片:以 Memcached 为例,大 Key 容易占用或频繁被淘汰,导致 slab 分配效率低下。
- 网络传输瓶颈:大体积数据穿越网卡和 TCP 栈耗时长,影响后续请求。
- 并发读写冲突:频繁变更的大 Key 与高并发读取互相干扰,导致性能波动。
- DB 重新加载代价高:一旦大 Key 穿透,回源到 DB 的读取与组装开销显著高于小 Key。
3. 业务场景
- 超长社交内容:微博或论坛中 1,000+ 字的长帖。
- 大规模集合数据:用户前 10,000 粉丝列表、商品历史浏览记录等。
- 复杂对象缓存:含多级属性、嵌套列表与 Map 的用户画像。
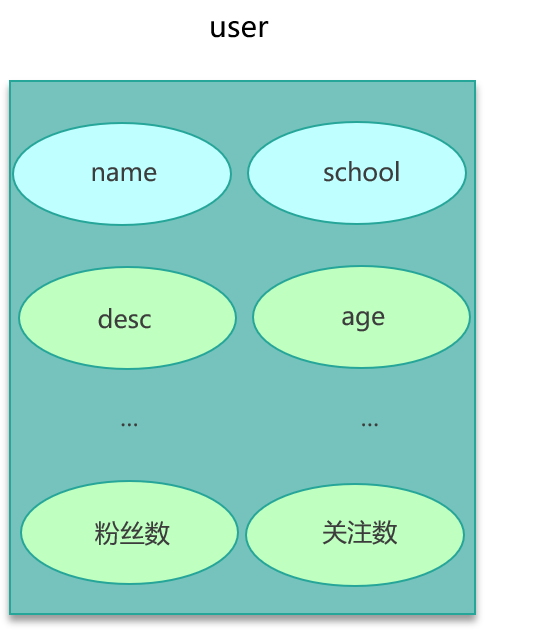
4. 解决方案
-
阈值压缩+预分配
- 对 Value 长度超过阈值的内容做压缩存储,减小网络与内存占用;
- 在缓存启动阶段预写一定量大 Key 数据,预先分配足够的 large slab,避免运行中碎片化。
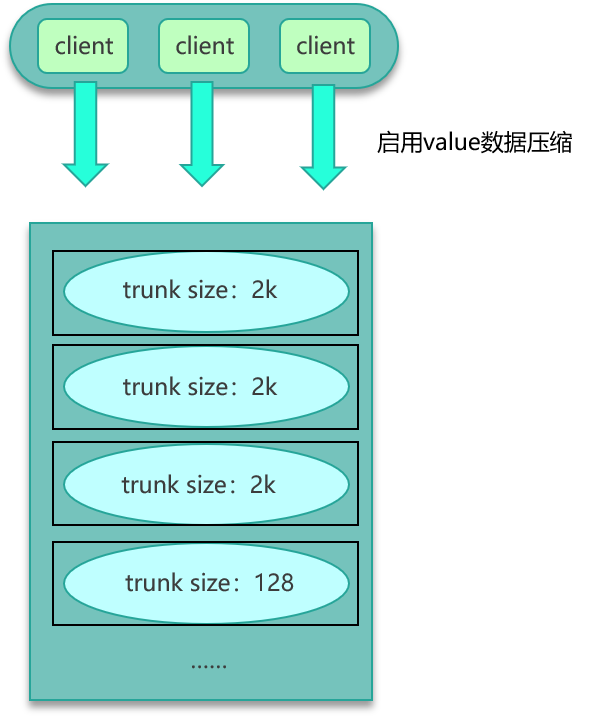
-
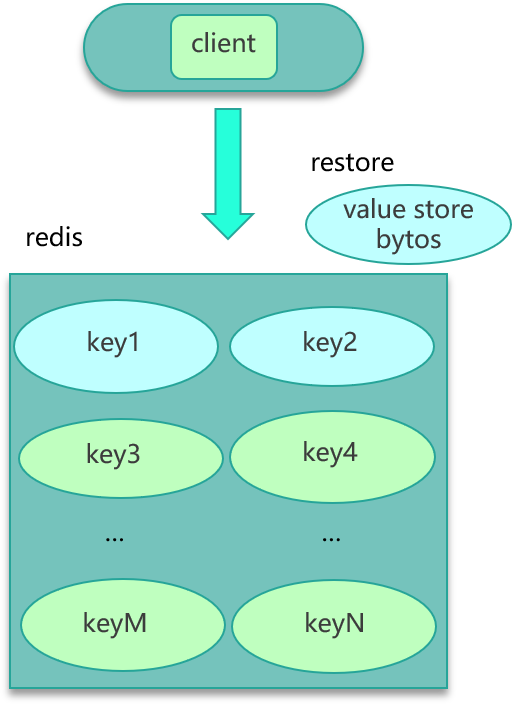
批量 Restore 写入(仅限 Redis)
- 在客户端将大 Key 序列化构建为 RDB 格式或 RESTORE 命令参数;
- 一次性写入 Redis,避免多次写入带来的网络与 CPU 开销。
- Key 分拆(Sharding)
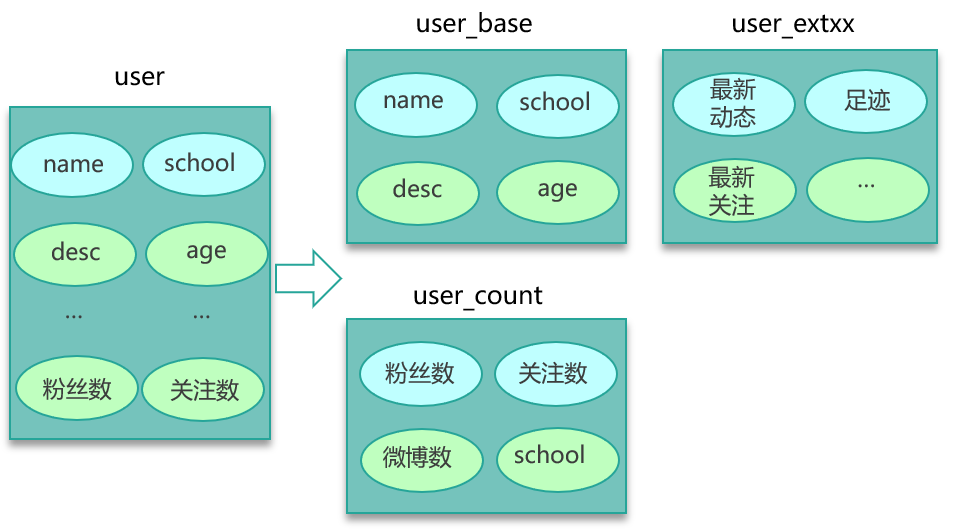
- 将一个大 Key 分割为多个小 Key,如
bigkey:part:0…bigkey:part:N; - 读写时并行或按需加载子 Key,单次操作的数据量大幅下降;
- 子 Key 缓存穿透时仅需回源对应分片,减轻 DB 压力。
三、小结
- Hot Key 与 Big Key 均是缓存系统的“热点”与“大块头”难题,直接关联到分布式架构的均衡与吞吐。
- 通过 分片、多级缓存、本地缓存、动态扩容等多种维度组合,可构建柔性且高可用的缓存方案。
- 在实践中,应结合业务流量特征与运维成本,灵活选择并测试多种策略,做好监控与预案。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











