








Pre
性能优化 - 案例篇:池化对象_Commons Pool 2.0通用对象池框架
性能优化 - 案例篇: 19 条常见的 Java 代码优化法则
- 引言:JIT 优化的重要性与背景
- 方法内联:原理、配置与案例
- 编译层次与分层编译:C1、C2、Graal 及 profiling
- 逃逸分析及标量替换:栈上分配与同步消除
- Code Cache 管理:容量、监控与调优
- JITWatch 工具演示
- 小结
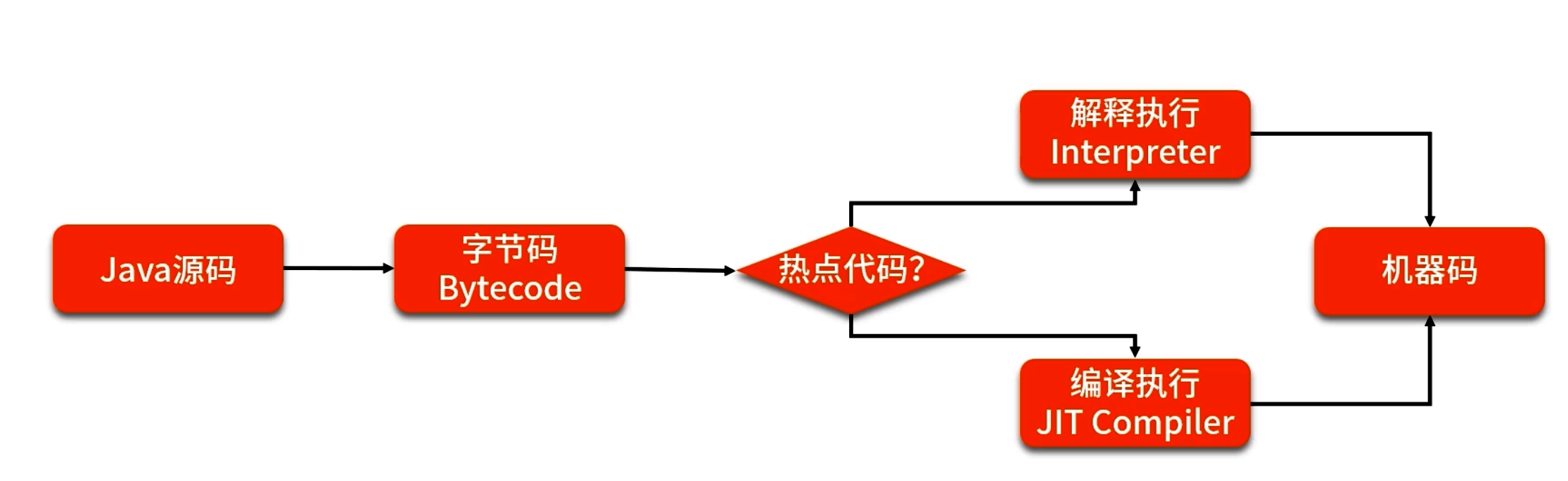
JIT 最主要的目标是把解释执行变成编译执行
1. 引言
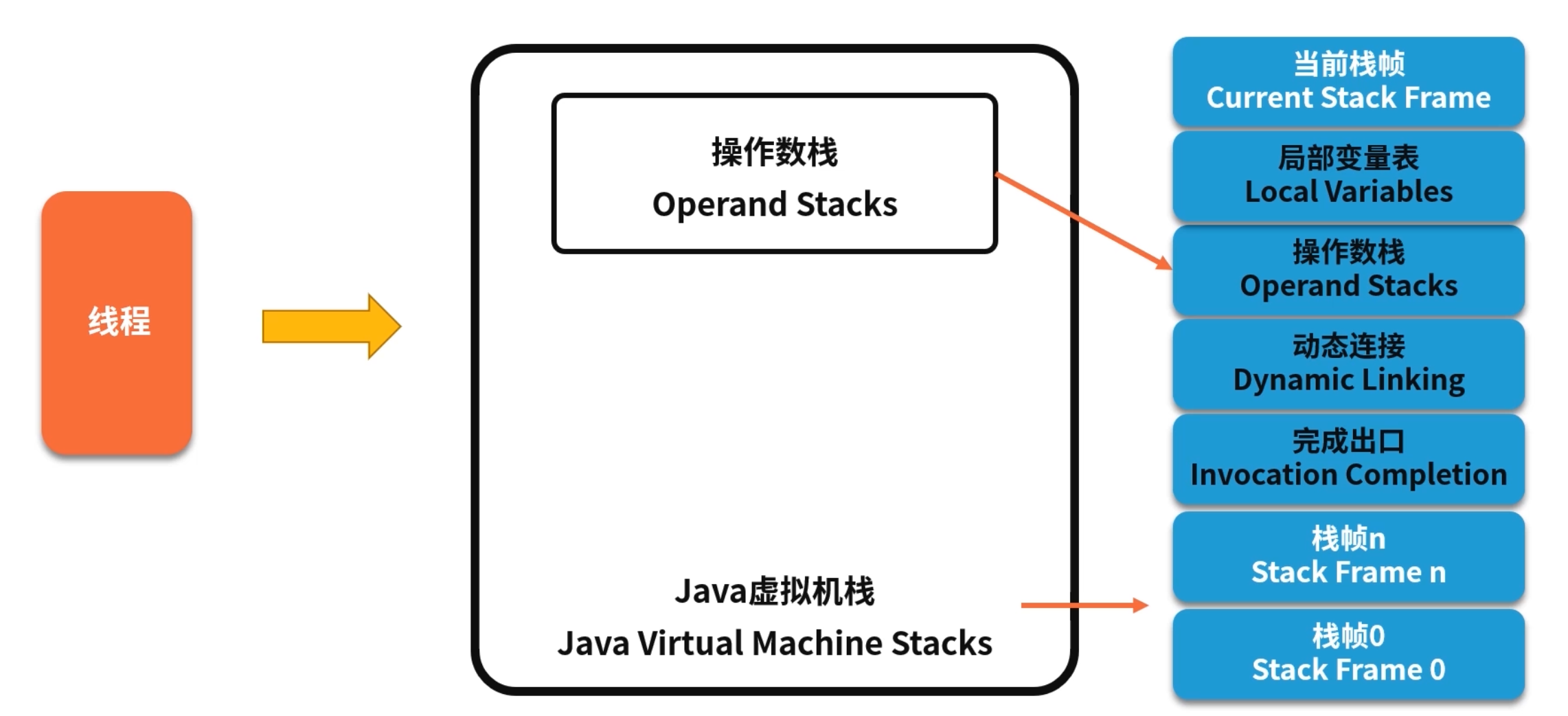
Java 虚拟机栈的“栈帧+操作数栈”模型虽能保证跨平台,但解释执行开销巨大。JIT(Just-In-Time 编译器)正是为了解决这类热点路径上的性能瓶颈:将反复执行的字节码动态编译为本地机器码,并在运行时做多种优化,从而显著提升吞吐与响应速度。
2. 方法内联
-
原理:将短小方法体直接“拷贝”到调用处,省去一次调用/返回过渡,减少栈帧创建,降低指令跳转。
-
Java 参数:
-XX:+Inline/-XX:-Inline启用或禁用内联。-XX:CompileCommand=exclude,类名.方法名精细排除。
-
注解控制:
@ForceInline强制内联,@DontInline禁止内联。 -
案例(JMH Benchmark):
baseline ≈0.48 ns/op dontInline ≈1.93 ns/op exclude ≈57.6 ns/op inline ≈0.48 ns/op内联后比不内联快约 5 倍;整体 JIT 与解释执行差距可达数百倍。
3. 编译层次与分层编译
-
即时编译器:HotSpot 提供 C1(客户端)和 C2(服务器),JDK10+ 可选 Graal。
-
分层编译流程:
- 解释执行字节码;
- C1 无 profiling 执行;
- C1 部分 profiling(方法/循环计数);
- C1 全 profiling;
- C2 优化执行。
-
触发阈值:
-XX:CompileThreshold,分层编译时失效,改用动态自适应策略。 -
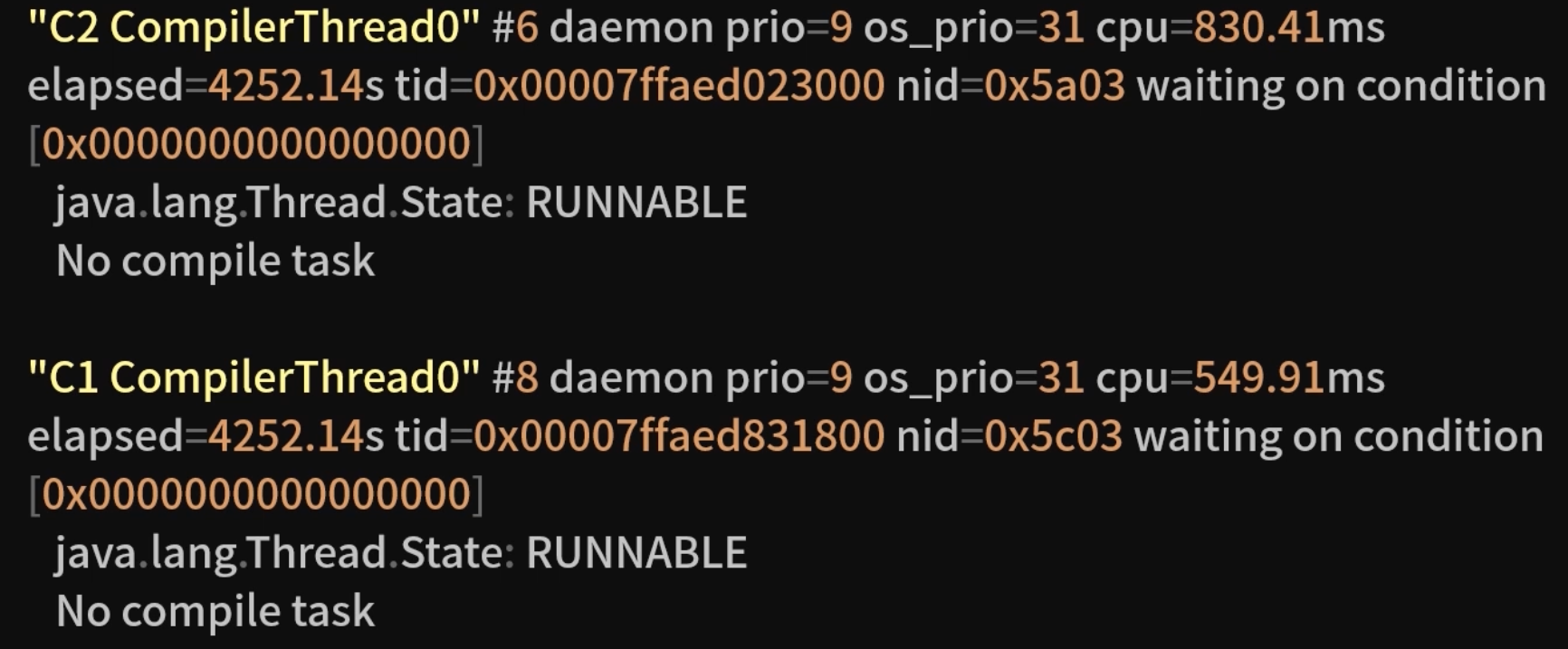
后台编译:C1/C2 线程与业务线程并行,不阻塞解释执行。
4. 逃逸分析与标量替换
-
逃逸分析:JIT 通过
-XX:+DoEscapeAnalysis(默认开启)判断对象是否“逃出”方法或线程。- 场景:赋值给字段/静态变量、通过
return返回即视为逃逸。
- 场景:赋值给字段/静态变量、通过
-
优化手段:
- 栈上分配:对“未逃逸对象”直接在栈帧分配,减少堆分配与 GC 压力;
- 标量替换:将对象拆解为基本类型局部变量;
- 同步消除:对仅限单线程访问的
synchronized区块可去除,需-XX:+EliminateLocks。
-
示例:
public Object test() { Object obj = new Object(); // 若未逃逸,可栈上分配 return obj; // 返回即逃逸,不优化 }
5. Code Cache 管理
- 作用:存储 JIT 编译后的本地机器码,启动后不可自动扩容。
- 风险:满后停止编译,退化为解释执行;过度编译还会增加 CPU 占用。
- 调优:
-XX:ReservedCodeCacheSize=xxxM增加缓存上限;可配合监控工具观察CodeCacheUsage。
6. JITWatch 工具演示
-
安装与日志
-XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation -XX:LogFile=jitdemo.log -
可视化:使用 JITWatch 打开
jitdemo.log,查看内联、逃逸分析、汇编级别的编译决策。 -
案例:在 for 循环中对
add(a,b)方法进行内联,观察热点路径已被替换为一段机器码。
小结
- JIT 是 JVM 性能的关键驱动力,通过方法内联、分层编译、逃逸分析等多种策略,将解释执行转换为高效本地执行。
- 合理调优
Inline、CompileThreshold、CodeCacheSize,并借助 JITWatch 等工具,可精细掌控编译效果。 - 同时也要警惕优化副作用,如过度编译、JIT 失效导致的逆优化场景。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











