







文章目录

概述
继续跟中华石杉老师学习ES,第29篇
课程地址: https://www.roncoo.com/view/55
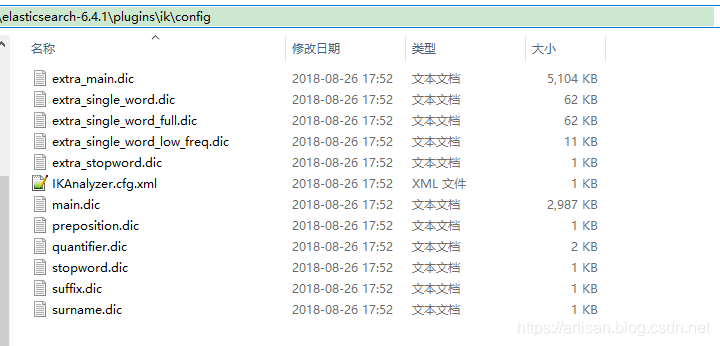
ik配置文件
配置文件位置: ${ES_HOME}/plugins/ik/config/IKAnalyzer.cfg.xml
IKAnalyzer.cfg.xml:
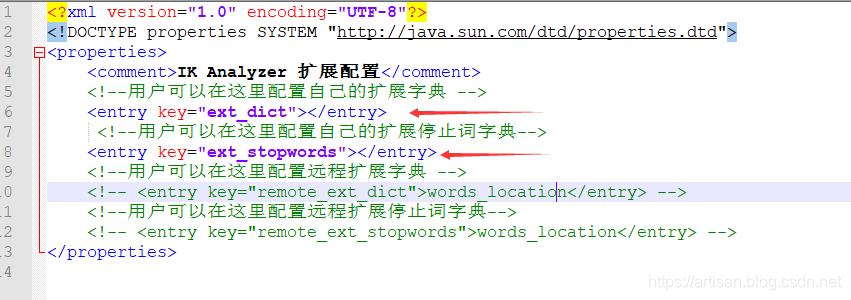
这里使用的是6.4.1版本对应的ik分词器,可以看到 配置文件中 ext_dict和ext_stopwords 默认是空的,如果需要的话,我们可以修改该配置项。
几个配置文件的作用
-
IKAnalyzer.cfg.xml:用来配置自定义词库
-
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
-
quantifier.dic:存放了一些单位相关的词
-
suffix.dic:存放了一些后缀
-
surname.dic:中国的姓氏
-
stopword.dic:英文停用词
最常用的两个
- main.dic:包含了原生的中文词语,会按照这个里面的词语去分词,只要是这些单词,都会被分在一起
- stopword.dic:包含了英文的停用词 ( 停用词 stop word ,比如 a 、the 、and、 at 、but 等 . 通常像停用词,会在分词的时候,直接被干掉,不会建立在倒排索引中 )
IK自定义词库
自定义词库
有一些特殊的流行词,一般不会在ik的原生词典main.dic里。
举个例子,比如2019年很火的 “盘他”,我们到原生词典main.dic中去查找下看看
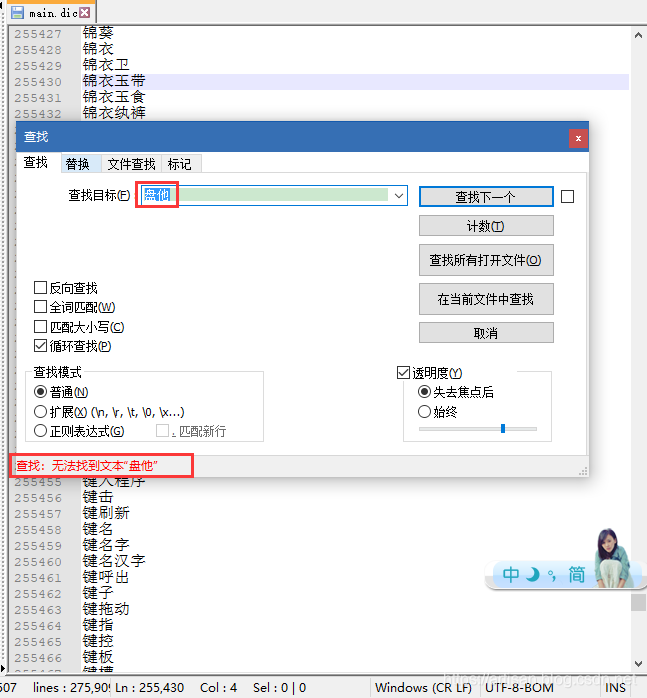
这个时候,我们用ik的ik_max_word分词器来查下分词
GET _analyze
{
"text": ["盘他","杠精","脱粉"],
"analyzer": "ik_max_word"
}
返回
{
"tokens": [
{
"token": "盘",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "他",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "杠",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 2
},
{
"token": "精",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 3
},
{
"token": "脱",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 4
},
{
"token": "粉",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 5
}
]
}
可以看到使用ik的 ik_max_word分词器还是将每个汉字作为一个term , 这个时候去使用这些词语去搜索,效果肯定不是很理想。
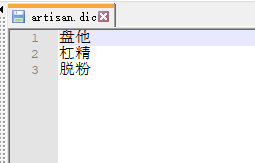
Step1 : 新建自定义分词库
我们这里新建个目录 custom , 在该目录下新建一个文件: artisan.dic

将希望不分词的词语放到该文件中,比如
盘他
杠精
脱粉
Step2 : 添加到ik的配置文件中
在 ext_ditc节点 添加自定义的扩展字典 , ik本身提供的 extra_main.dic 词语更加丰富,这里我们也添加进去吧
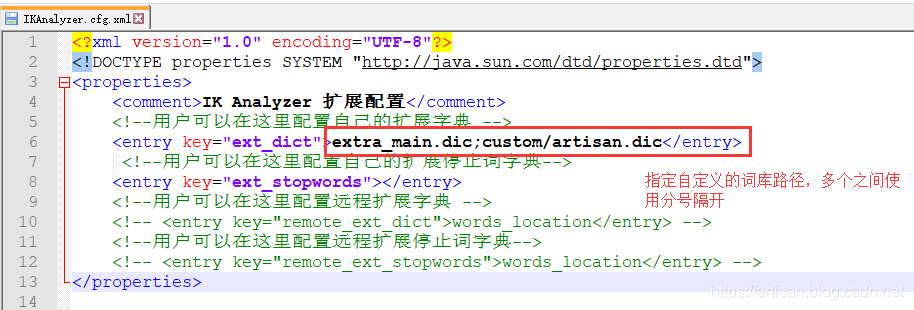
Step3 :重启es ,查看分词
重启es
GET _analyze
{
"text": ["盘他","杠精","脱粉"],
"analyzer": "ik_max_word"
}
返回
{
"tokens": [
{
"token": "盘他",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "盘",
"start_offset": 0,
"end_offset": 1,
"type": "CN_WORD",
"position": 1
},
{
"token": "他",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 2
},
{
"token": "杠精",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 3
},
{
"token": "脱粉",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 4
}
]
}
可以看到,和未添加自定义词典相比,已经可以按照自己指定的规则进行分词了。
自定义停用词库
比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索
可以看到
- stopword.dic 中是 英文 停用词
- extra_stopword.dic 中文停用词
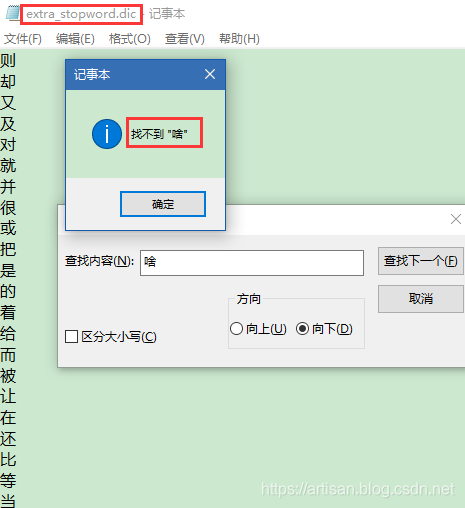
验证下分词
GET _analyze
{
"text": ["啥类型"],
"analyzer": "ik_max_word"
}
返回
{
"tokens": [
{
"token": "啥",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "类型",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "类",
"start_offset": 1,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "型",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 3
}
]
}
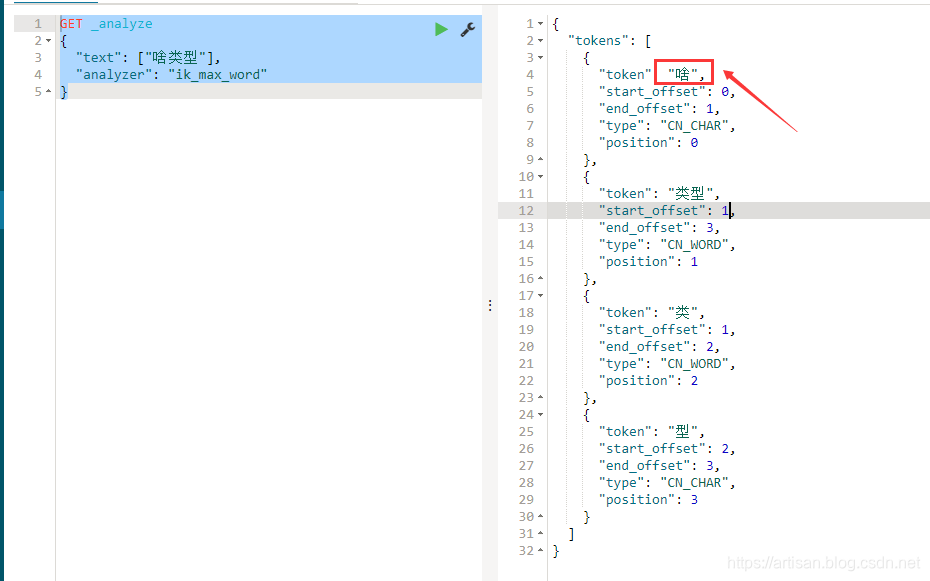
可以看到 “啥”是建立了倒排索引的。那我们下面来将 “啥”添加到自定义的停用词里,来验证下吧。
Step1 : 新建自定义停用词词典
我们在新建的目录 custom , 在该目录下新建一个文件: artisan_stopword.dic , 添加停用词

Step2 : 添加到ik的配置文件中
在 ext_stopwords节点 添加自定义的停用词扩展字典 , ik本身提供的 extra_stopword.dic 这里我们也添加进去吧
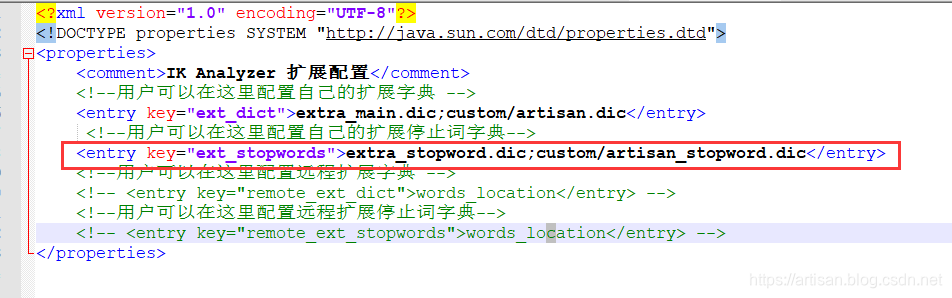
Step3 : 重启es ,查看停用词
重启es ,验证停用词
GET _analyze
{
"text": ["啥类型"],
"analyzer": "ik_max_word"
}
返回
{
"tokens": [
{
"token": "类型",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "类",
"start_offset": 1,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "型",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
}
]
}
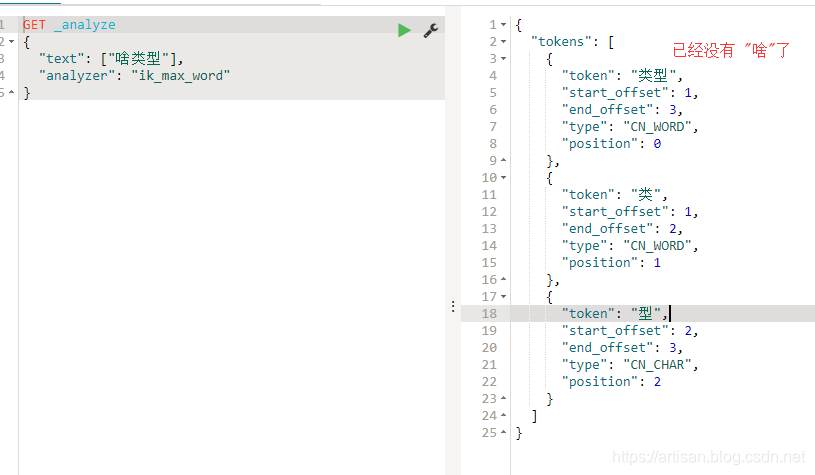
可以看到 “啥”已经不会在倒排索引中了,自定义停用词功能成功。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











