







zookeeper 是一个开源的分布式协调服务,由雅虎公司创建,是 google chubby 的开源实现。zookeeper 的设计目
标是将哪些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集(由若干条指令组成的,完成
一定功能的一个过程),并且以一些列简单一用的接口提供给用户使用。
那么什么是分布式协调技术?
那么我来告诉大家,其实分布式协调技术 主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成”脏数据”的后果。
ZooKeeper性能上的特点决定了它能够用在大型的、分布式的系统当中。从可靠性方面来说,它并不会因为一个节点的错误而崩溃。除此之外,它严格的序列访问控制意味着复杂的控制原语可以应用在客户端上。ZooKeeper在一致性、可用性、容错性的保证,也是ZooKeeper的成功之处,它获得的一切成功都与它采用的协议——Zab协议是密不可分的,这些内容将会在后面介绍。
ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
server.A=B:C:D
A:其中 A 是一个数字,表示这个是服务器的编号;
B:是这个服务器的 ip 地址;
C:Zookeeper服务器之间的通信端口。
D:Leader选举的端口;
搭建ZooKeeper服务器集群
(1) zk服务器集群规模不小于3个节点
(2) 要求各服务器之间系统时间要保持一致。
ZooKeeper不支持递归的删除操作,因此在删除父节点之前必须先删除子节点。
zookeeper常常用来做分布式事务锁。
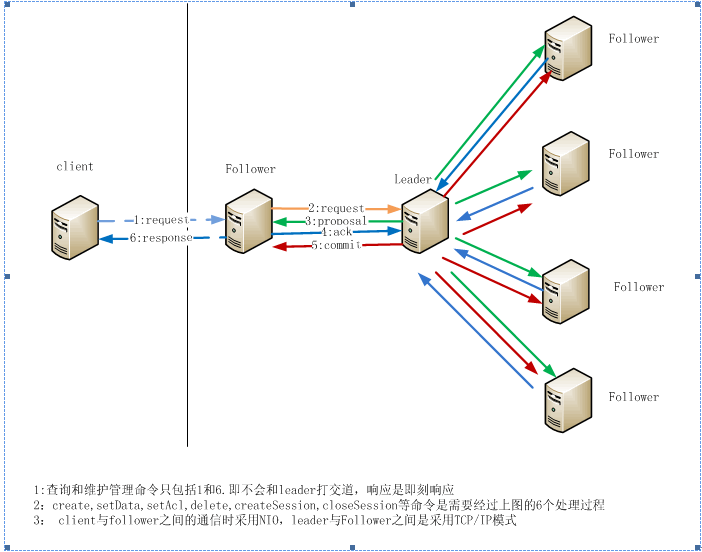
Zookeeper所使用的ZAB协议也是类似paxos协议的。所有分布式自协商一致性算法都是paxos算法的简化或者变种。Client是使用zookeeper服务的机器,Zookeeper自身包含了Acceptor, Proposer, Learner。Zookeeper领导选举就是paxos过程,还有Client对Zookeeper写Znode时,也是要进行Paxos过程的,因为不同Client可能连接不同的Zookeeper服务器来写Znode,到底哪个Client才能写成功?需要依靠Zookeeper的paxos保证一致性,写成功Znode的Client自然就是被最终接受了,Znode包含了写入Client的IP与端口,其他的Client也可以读取到这个Znode来进行Learner。也就是说在Zookeeper自身包含了Learner(因为Zookeeper为了保证自身的一致性而会进行领导选举,所以需要有Learner的内部机制,多个Zookeeper服务器之间需要知道现在谁是领导了),Client端也可以Learner,Learner是广义的。
ookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理
我们知道ZooKeeper的数据存储在一个叫ReplicatedDataBase 的数据库中,该数据是一个内存数据库
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









