






先在py文件中导入相应的库 ,创建浏览器实例
from selenium import webdriver
browser = webdriver.Chrome()
要定位的页面打开f12后如下图(图1)
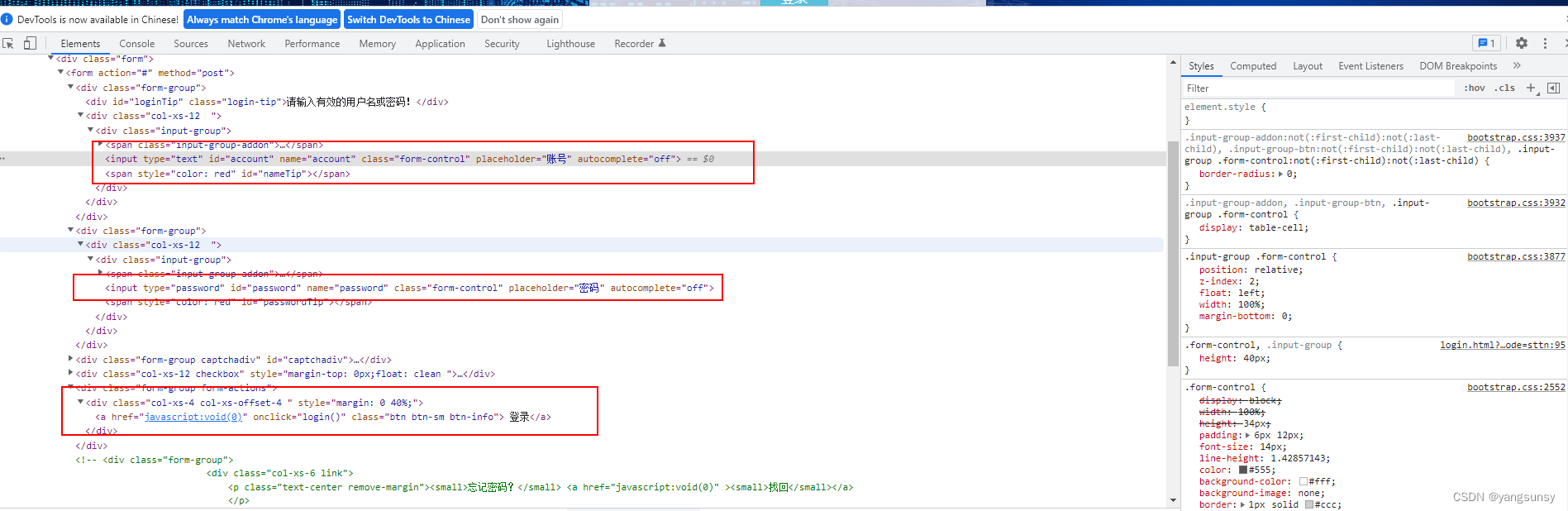
1.by_id,图1中定位账号输入框可用id定位
browser.find_element_by_id('account')
2.by_name,图1中定位账号输入框也可以用name定位
browser.find_element_by_name('account')
3.by_class_name,图1中定位账号输入框也可以用class定位
browser.find_element_by_class_name('form-control')
但是,观察到class名为form-control不唯一,不可用
4.link_text,图1中,定位登录按钮可用根据连接的文字定位
browser.find_element_by_link_text("登录")
5.xpath,任何元素,均可以用xpath去定位,如图1中定位账号输入框可以用xpath
xpath有多种写法。xpath的id定位,等同于根据id定位
browser.find_element_by_xpath('//*[@id="account"]')
xpath的class定位,等同于根据class_name定位
browser.find_element_by_xpath('//*[@class="form-control"]')
xpath的name定位
browser.find_element_by_xpath('//*[@name="account"]')
xpath的路径探索定位:解释一下这个://*[@id=“nameTip”]是跟账号同级那个span元素(如图2),且其可以根据id唯一定位。定位span后/…表示span的上一级div元素,div下面的一个input即为账号输入框。
browser.find_element_by_xpath('//*[@id="nameTip"]/../input')
图2

用xpath的text定位:text的值要为标签间的文本,比如登录 如果为是定位不到的。
browser.find_element_by_xpath("//*[text()='登录'")
xpath的src定位:像如下图所示的iframe定位,无id,class也不唯一,此时可以用xpath的src定位
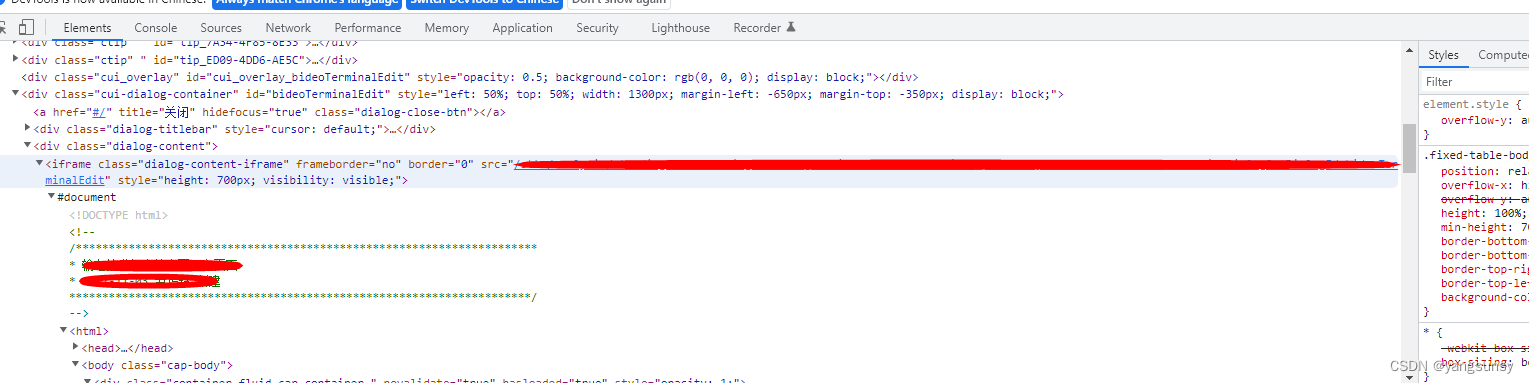
xpath的src定位
browser.find_element_by_xpath("//*[@src='xxxxxxxxx']")















 2549
2549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









