





想了解Google,Bing或Yahoo的工作原理吗?想知道如何抓取网页,以及一个简单的网络爬虫看起来像什么?在50行以下的Python(版本3)代码中,这里有一个简单的网络爬虫!(带有注释的完整源代码位于本文的底部)。
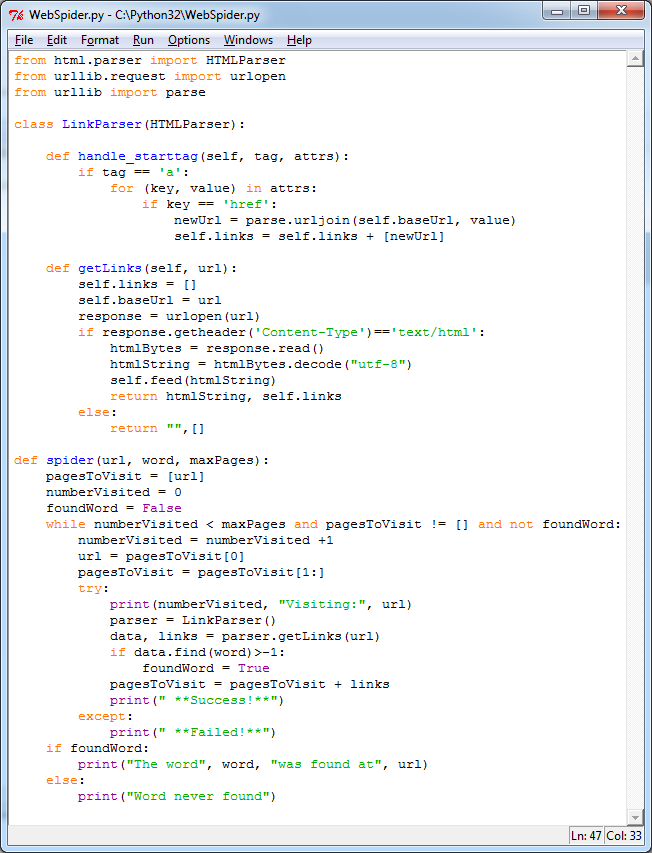
让我们看看它是如何运行的。请注意,您输入起始网站,要查找的字词以及要搜索的最大页数。
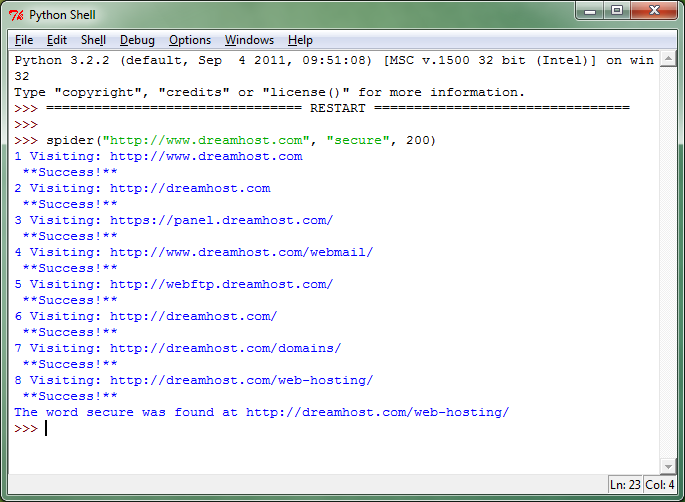
好吧,但它是如何工作的?
让我们先来谈谈网络爬虫的目的是什么。如维基百科页面上所述,网络爬虫是一种以有条不紊的方式浏览万维网收集信息的程序。网络爬虫收集什么样的信息?通常有两件事:
- 网页内容(页面上的文本和多媒体)
- 链接(到同一网站上的其他网页,或完全到其他网站)
这正是这个小“机器人”的作用。它从您在spider()函数中键入的网站开始,并查看该网站上的所有内容。这个特定的机器人不检查任何多媒体,而是它正在寻找“text / html”如代码中所述。每次访问网页时, 它会收集两组数据:页面上的所有文本以及页面上的所有链接。如果在页面上的文本中找不到该单词,机器人将收集其集合中的下一个链接,并重复该过程,再次收集下一页上的文本和链接集。一次又一次地,重复这个过程,直到机器人找到了这个词或已经跑进了你输入到spider()函数的极限。
这是Google的工作原理吗?
有点。Google有一整套网络抓取工具不断抓取网络,抓取是发现新内容(或跟踪不断更新的网站或添加新内容的网站)的重要组成部分。但是,您可能注意到此搜索需要一段时间才能完成,也许只有几秒钟。在更困难的搜索词可能需要更长时间。搜索引擎有另一个很大的组成部分,称为索引。索引是您对Web爬网程序收集的所有数据的处理。索引意味着您解析(浏览和分析)网页内容并创建一个容易访问和快速检索的 信息的大集合(思考数据库或表)。因此,当您访问Google并输入“kitty cat”时,您的搜索字词将直接用于已经抓取,解析和分析的数据集合。事实上,你的搜索结果已经坐在那里等待一个神奇的短语“小猫猫”释放他们。这就是为什么你可以在0.14秒内获得超过1400万的结果。
*您的搜索字词实际上同时访问多个数据库,例如拼写检查,翻译服务,分析和跟踪服务器等。
让我们更详细地看代码!
以下代码应该完全适用于Python 3.x. 它是使用Python 3.2.2在2011年9月编写和测试的。继续并复制+粘贴到您的Python IDE,运行它或修改它!
from html.parser import HTMLParser
from urllib.request import urlopen
from urllib import parse
# We are going to create a class called LinkParser that inherits some
# methods from HTMLParser which is why it is passed into the definition
class LinkParser(HTMLParser):
# This is a function that HTMLParser normally has
# but we are adding some functionality to it
def handle_starttag(self, tag, attrs):
# We are looking for the begining of a link. Links normally look
# like <a href="www.someurl.com"></a>
if tag == 'a':
for (key, value) in attrs:
if key == 'href':
# We are grabbing the new URL. We are also adding the
# base URL to it. For example:
# www.netinstructions.com is the base and
# somepage.html is the new URL (a relative URL)
#
# We combine a relative URL with the base URL to create
# an absolute URL like:
# www.netinstructions.com/somepage.html
newUrl = parse.urljoin(self.baseUrl, value)
# And add it to our colection of links:
self.links = self.links + [newUrl]
# This is a new function that we are creating to get links
# that our spider() function will call
def getLinks(self, url):
self.links = []
# Remember the base URL which will be important when creating
# absolute URLs
self.baseUrl = url
# Use the urlopen function from the standard Python 3 library
response = urlopen(url)
# Make sure that we are looking at HTML and not other things that
# are floating around on the internet (such as
# JavaScript files, CSS, or .PDFs for example)
if response.getheader('Content-Type')=='text/html':
htmlBytes = response.read()
# Note that feed() handles Strings well, but not bytes
# (A change from Python 2.x to Python 3.x)
htmlString = htmlBytes.decode("utf-8")
self.feed(htmlString)
return htmlString, self.links
else:
return "",[]
# And finally here is our spider. It takes in an URL, a word to find,
# and the number of pages to search through before giving up
def spider(url, word, maxPages):
pagesToVisit = [url]
numberVisited = 0
foundWord = False
# The main loop. Create a LinkParser and get all the links on the page.
# Also search the page for the word or string
# In our getLinks function we return the web page
# (this is useful for searching for the word)
# and we return a set of links from that web page
# (this is useful for where to go next)
while numberVisited < maxPages and pagesToVisit != [] and not foundWord:
numberVisited = numberVisited +1
# Start from the beginning of our collection of pages to visit:
url = pagesToVisit[0]
pagesToVisit = pagesToVisit[1:]
try:
print(numberVisited, "Visiting:", url)
parser = LinkParser()
data, links = parser.getLinks(url)
if data.find(word)>-1:
foundWord = True
# Add the pages that we visited to the end of our collection
# of pages to visit:
pagesToVisit = pagesToVisit + links
print(" **Success!**")
except:
print(" **Failed!**")
if foundWord:
print("The word", word, "was found at", url)
else:
print("Word never found")














 95
95

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









