







目录
一、分页查询的问题
在我们日常开发中,当使用limit实现分页查询时,当limit的偏移量越大时,sql语句的耗时也越大。
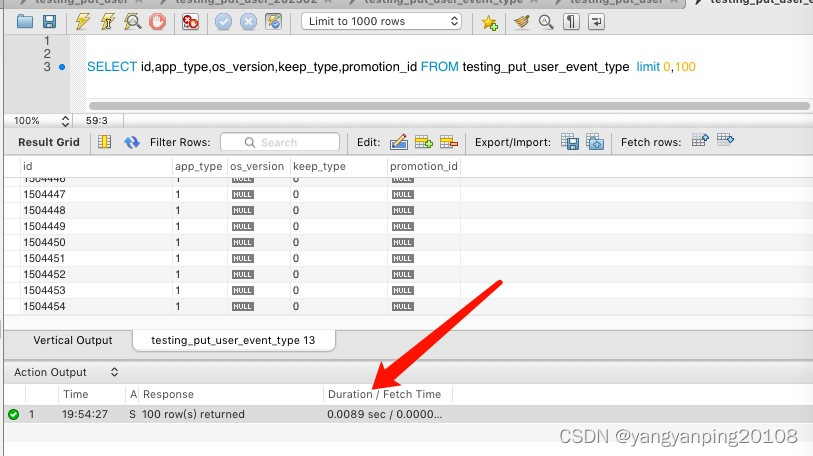
上图偏移量为0时,sql语句耗时在8.9毫秒。
顺便说下偏移量与页码、页大小的关系:
偏移量 = (页码 - 1) x 页的大小
比如页的大小是每页100行记录, 那么:
第一页的偏移量就是 (1 - 1) x 100 = 0
第二页的偏移量就是 (2 - 1) x 100 = 100
以此类推
我们看下,当增大偏移量查询的耗时 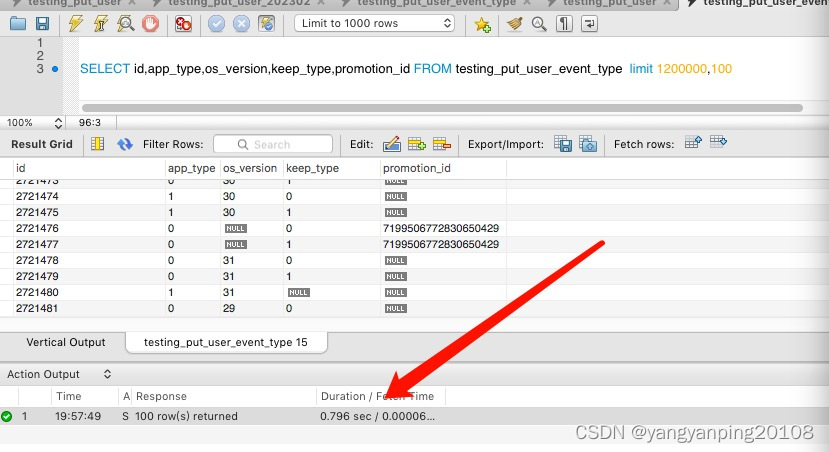
当偏移量加到1200000时,耗时也增大到796毫秒。
为什么偏移量会对性能有这么大影响呢?
二、MySQL的体系结构 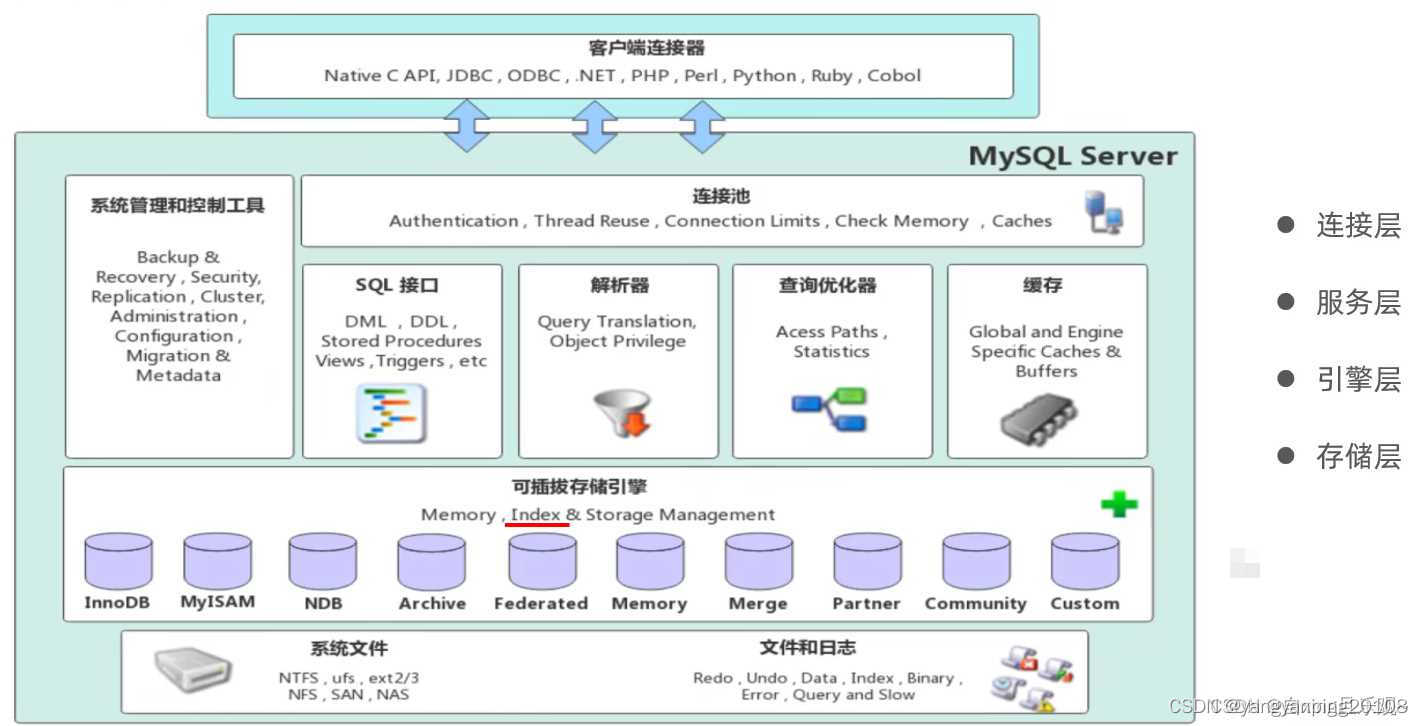
各层功能
连接层:最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方 案。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
服务层:第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析 和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。
引擎层:存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。 不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。
存储层:主要是将数据存储在文件系统之上,并完成与存储引擎的交互。
三、Limit性能优化
上图是MySQL的系统结构图,客户端程序发送sql语句查询请求给服务层,服务层会解析、优化sql语句,之后交给存储引擎,也就是说,存储引擎是真正完成查询的(增加、删除、修改也是由存储引擎负责的)。
SELECT * FROM testing_put_user_event_type limit 1200000,100
当存储引擎查询数据库文件后返回的不是一页的数据(100行), 而是从第1行 到 第 (1200000 + 100)行的数据一起返回给服务层。 服务层收到数据后会抛弃前面的1200000行,只留下最后的100行返回给客户端。
数据库表中行数据、索引都是以文件的形式存储到磁盘(硬盘)上的,而硬盘的速度相对来说要慢很多,存储引擎运行sql语句时,需要访问硬盘查询文件,然后返回数据给服务层。当返回的数据越多时,访问磁盘的次数就越多,就会越耗时。这就是为什么偏移量越大、返回的数据越多,越耗时的原因。
所以说,如果想优化上面的sql时,必须要减少返回的数据。
当表的主键是有序的,或者是自增的,可以使用id限定查询,查询过程是:
当已经查询了某页的数据后,记录下该页最后一行记录的主键id值(本例中是id为主键),查询下一页时就可以使用如下sql:
select * from testing_put_user_event_type
where 主键列名 > 当前页最后一行的主键值 limit 0, 100
比如:
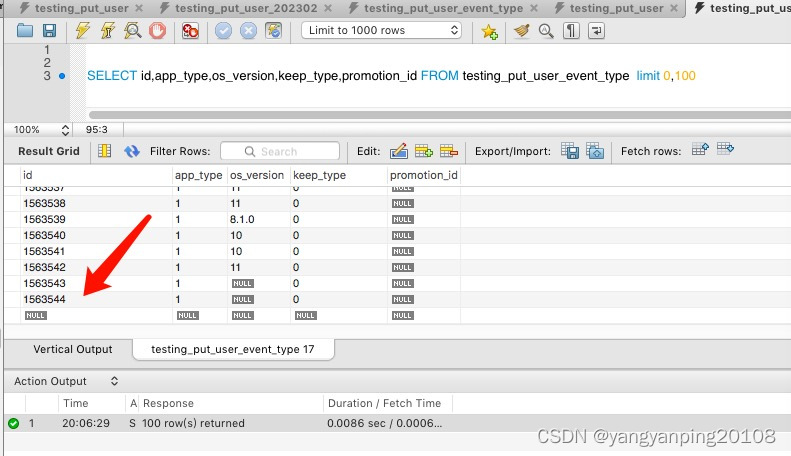
当前页最后一行的主键值是1563544,查询下一页就可以使用:
SELECT id,app_type,os_version,keep_type,promotion_id FROM testing_put_user_event_type
where id>1563544 limit 0,100
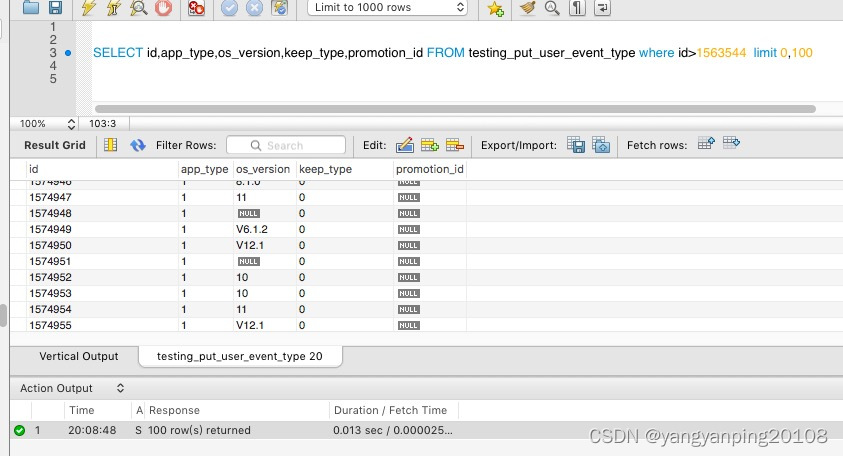
那么第一页怎么查询呢?
可以选择一个比所有主键值都小的值,比如0或者负数 :
SELECT id,app_type,os_version,keep_type,promotion_id FROM testing_put_user_event_type
where id>0 limit 0,100















 3274
3274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









