







平时在写代码时,经常用到java的集合,使用最多的就是ArrayList与HashMap等,对其它的接口就不甚了解。最近抽出时间对集合整理一下。
collection是集合最顶层接口,位于java.utils包中,接口继承了Iterable接口,因此集合实现迭代功能。
public interface Collection<E> extends Iterable<E> {继承Collection接口的接口包括Set、List、Queue。这些接口及其实现类关系图:
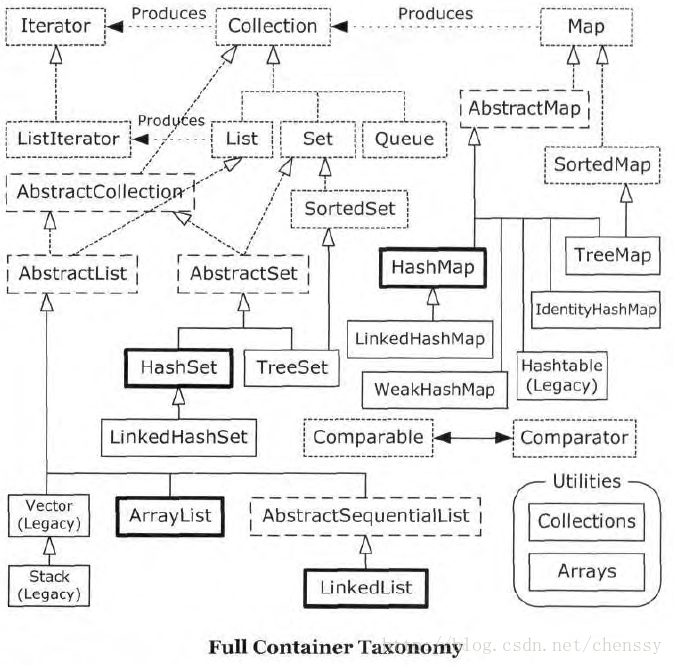
请先忽略图中的Map接口,稍后理解Map接口。
实现List接口的类包括Vector、ArrayList、LinkedList。因此这三者共同的特征是存储的数据有序、可重复。三者之间的区别为:
- ArrayList是基于数组的列表,内部元素可以通过get与set访问。适合于数据的查询与遍历。
- LinkedList是双链表结构,在添加或删除元素方面比ArrayList更适合。
- Vector与ArrayList结构类似,但是Vector有一个重要特征就是线程安全,因此适合并发多线程操作。另外Vector还有一个子类Stack(栈),Stack的特征是先进后出。
Set是最简单的一种集合,相当于一个可变大小的数组,它的特征是数据无序、不能重复,这些特征是因为它的实现类底层结构是Map,数据存储在Map的key上。实现Set接口的类包括HashSet、TreeSet、linkedHashSet。内部各自使用的Map结构对应HashMap、TreeMap、LinkedHashMap。
Queue是一种队列集合,发现图中没有实现该接口的类,其实LinkedList是实现了Queue接口:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{public interface Deque<E> extends Queue<E> {因此LinkedList具有队列的特征,即先进先出。另外对于多线程编程模式在很大程序上都依赖于Queue实现的线程安全性的知识会在另一博文中单独讨论。
Map是一个键值对形式的集合,它的元素由键和值组成,其中键(key)是唯一的,值(value)可以重复,键值被封装在Entry对象中。在底层它是基于数组和链表的混合数据结构。实现Map接口的类包括HashMap、HashTable、TreeMap、WeakHashMap和IdentityHashMap。
- HashMap 线程不安全、效率高。通过hashcode、equal来确保键的唯一性。HashMap添加元素的原理步骤:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//第一步,判断key是否为null,jdk将key为null时单独处理了,其实与非null的key的操作一致
if (key == null)
return putForNullKey(value);
//第二步,获取key的hash值
int hash = hash(key);
//第三步,根据hash值和数组的长度计算需要将元素放置的下标
int i = indexFor(hash, table.length);
//第四步,遍历该下标中的Entry链表,判断要添加元素的key与现有元素key是否一致,根据hash值与equals方法判断;若存在,替换value,结束;否则直到next为null结束。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//第五步,相同key不存在,添加键值对元素。
addEntry(hash, key, value, i);
return null;
} void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//第六步,创建Entry,bucketIndex为下标
createEntry(hash, key, value, bucketIndex);
}void createEntry(int hash, K key, V value, int bucketIndex) {
//第七步,获取数组当前下标的Entry
Entry<K,V> e = table[bucketIndex];
//第八步,数组当前下标指向新添加的Entry,新添加的entry中next指向原始数组下标对应的Entry
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}可知,HashMap中数据是无序的。HashMap还有一个子类LinkedHashMap,LinkedHashMap是在HashMap的基础上维护了一个双向循环链表,链表定义迭代顺序,该顺序就是数据存入的顺序,因此LinkedHashMap与HashMap不同的地方就是它是有序的。由于LinkedHashMap额外维护链表,因此效率不如HashMap。
2.HashTable 是线程安全的, 效率低。HashTable不仅实现了Map接口,还继承了Dictionary类,
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {因此,HashTable在遍历数据时使用的是枚举,不能使用迭代器,而目前迭代器已经逐渐取代枚举,另外HashTable不允许null,hashMap允许null,在获取元素时,HashTable也是线程安全的;等等其他原因,建议HashMap替换HashTable,若为了达到线程安全,可以使用concurrentMap,或者collections中的synchronizedMap()方法包裹HashMap。
3.TreeMap是基于红黑二叉树实现的。因此TreeMap是有序的,而且是唯一带有subMap()方法的Map,它可以返回一个子树。关于红黑二叉树实现原理请参阅另外两篇博文:
java源码分析之TreeMap基础篇
通过分析 JDK 源代码研究 TreeMap 红黑树算法实现
4.WeakHashMap 短时间内缓存等用途。
5.IdentityHashMap,在判断key是否相等时,用的是“==”,因此允许内容相同的多个对象的key存在。
结束!!!















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









