






系列文章目录
提示:需要强调,笔者是基于pytorch,来完成的模型训练。
第一章 数据的获取
第二章 模型训练
第三章 可视化界面
一、数据的获取。
从网上查找,我们可以知道,猫的十二类分别是: 布偶猫,阿比西亚猫, 孟加拉豹猫, 暹罗猫, 无毛猫, 波斯猫, 缅因猫, 俄罗斯蓝猫, 埃及猫, 英国短毛猫, 伯曼猫, 孟买猫。
下面就以“ 布偶猫”为例子,实战爬取中国视觉图片(为什么选择中国视觉网站,因为它上面的分类明显,并且图片适合模型训练),以得到图片资源。
进入中国视觉网站(视觉中国—正版高清图片、视频、音乐、字体下载—商业图片下载网站 (vcg.com))后,
搜索“布偶猫”并点击检查,得到如下图所示的网页源代码。分析得出(经过页面抓取和js文件分析,没有得到想要的图片源代码。)页面隐藏了图片下载源。
我们可以借助selenium来完成图片url获取。(文章不在介绍有关selenim的安装)
代码解释已经放在注释当中,可以直接看代码:
import asyncio
import re
import aiohttp
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
def ks_download_uel(image_urls):
async def download_images(url_list):
async with aiohttp.ClientSession() as session:
global k
for url in url_list:
try:
async with session.get("https:" + url) as response: # "https:" + url 进行网址拼接
response.raise_for_status()
file_path = fr"D:\布偶猫\{k}.jpg" # 指定保存地址
with open(file_path, 'wb') as file:
while True:
chunk = await response.content.read(8192)
if not chunk:
break
file.write(chunk)
print(f"已经完成 {k} 张")
except Exception as e:
print(f"下载第 {k} 张出现错误 :{str(e)}")
k += 1 # 为下一张做标记
# 创建事件循环对象
loop = asyncio.get_event_loop()
# 调用异步函数
loop.run_until_complete(download_images(image_urls))
if __name__ == '__main__':
base_url = 'https://www.vcg.com/creative-image/buoumao/?page={page}' # "buoumao"为布偶猫的拼音,如果想搜索其他品种的猫,直接更改拼音就可以
edge_options = Options()
edge_options.add_argument("--headless") # 不显示浏览器敞口, 加快爬取速度。
edge_options.add_argument("--no-sandbox") # 防止启动失败
driver = webdriver.Edge(options=edge_options)
k = 1 # 为保存的每一种图片做标记
for page in range(1, 5): # 每一页150张,十页就够了。
if page == 1: # 目的是就打开一个网特,减少内存开销
driver.get(base_url.format(page=page)) # 开始访问第page页
elements = driver.find_elements(By.XPATH, '//*[@id="imageContent"]/section[1]') # 将返回 //*[@id="imageContent"]/section/div 下的所有子标签元素
urls_ls = [] # 所要的图片下载地址。
for element in elements:
html_source = element.get_attribute('outerHTML')
urls_ls = re.findall('data-src="(.*?)"', str(html_source)) # 这里用了正则匹配,可以加快执行速度
# 下面给大家推荐一个异步快速下载图片的方法, 建议这时候尽量多提供一下cpu和内存为程序
ks_download_uel(urls_ls)
driver.execute_script(f"window.open('{base_url.format(page=page)}', '_self')") # 在当前窗口打开新网页,减少内存使用
driver.quit() # 在所有网页访问完成后退出 WebDriver
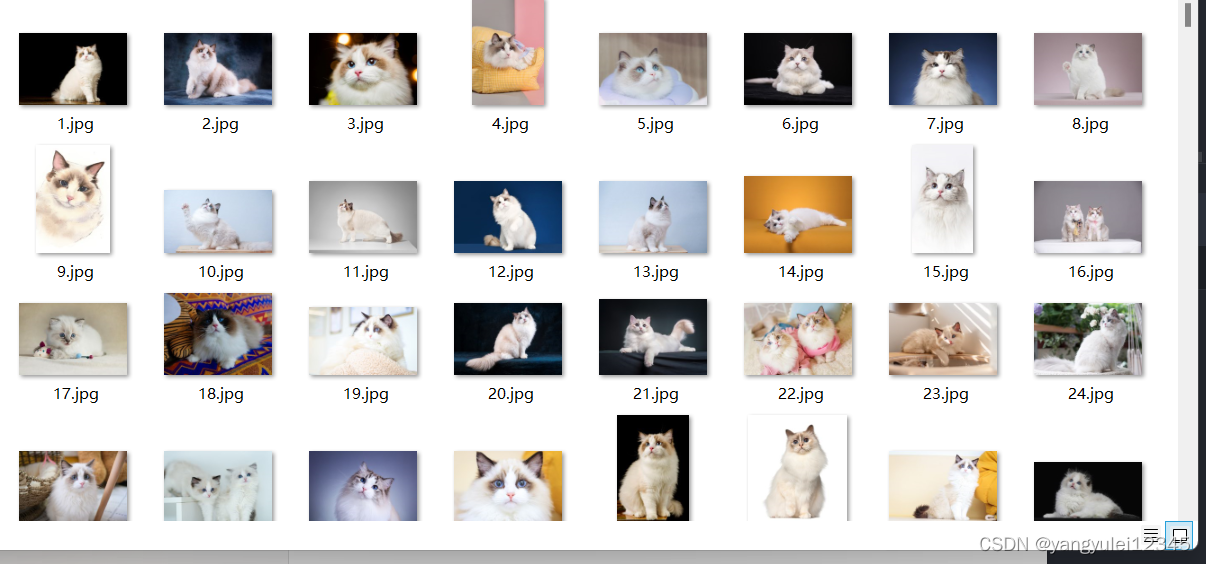
速度还是很快的,下面就是保存后的图片:
二、模型搭建与训练。
完成数据的获取后,就可以进行模型搭建和训练了。
下面是基于resnet50的模型训练,解释都在代码中。(后期可以自己更改参数,来进一步提高准确率,代码风格有点乱,勿喷):
特别强调一点,在代码中,他会随机的把你的训练集中不同标签分成训练集和测试级,另外,训练集中,不同的类别放在不同的文件夹下就好了,它可以根据文件名称自动分类。
代码如下(示例):
from collections import Counter
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
import torchvision
from torch.utils.data import WeightedRandomSampler
from torchvision import transforms
from tqdm import tqdm
loss = None # 可以避免警告,不用这句话也行
def train(model1, device, dataset, optimizer1, epoch1):
global loss
model1.train() # 设置模型为训练模式
correct = 0
all_len = 0
for i, (x, y) in tqdm(enumerate(dataset)):
x, y = x.to(device), y.to(device) # 将数据移动到设备上进行计算
optimizer1.zero_grad() # 梯度清零
output = model1(x) # 模型前向传播
pred = output.max(1, keepdim=True)[1] # 获取预测结果
correct += pred.eq(y.view_as(pred)).sum().item() # 统计预测正确的数量
all_len += len(x) # 统计样本数量
loss = nn.CrossEntropyLoss()(output, y) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer1.step() # 更新模型参数
print(f"第 {epoch1} 次训练的Train准确率:{100. * correct / all_len:.2f}%") # 打印训练准确率
def vaild(model, device, dataset):
model.eval() # 设置模型为评估模式
global loss
correct = 0
test_loss = 0
all_len = 0
with torch.no_grad():
for i, (x, target) in enumerate(dataset):
x, target = x.to(device), target.to(device) # 将数据移动到设备上进行计算
output = model(x) # 模型前向传播
loss = nn.CrossEntropyLoss()(output, target) # 计算损失
test_loss += loss.item() # 累计测试损失
pred = output.argmax(dim=1, keepdim=True) # 获取预测结果
correct += pred.eq(target.view_as(pred)).sum().item() # 统计预测正确的数量
all_len += len(x) # 统计样本数量
print(f"Test 准确率:{100. * correct / all_len:.2f}%") # 打印测试准确率
return 100. * correct / all_len # 返回测试准确率
if __name__ == '__main__':
if torch.cuda.is_available():
DEVICE = torch.device('cuda')
else:
DEVICE = torch.device('cpu')
LR = 0.0001 # 学习率
EPOCH = 30 # 训练轮数
BTACH_SIZE = 32 # 批量大小
train_root = r"自己训练集地址" # 训练数据根目录
# 数据加载及处理
train_transform = transforms.Compose([
transforms.Resize(256), # 调整图像大小为256x256
transforms.RandomResizedCrop(244, scale=(0.6, 1.0), ratio=(0.8, 1.0)), # 随机裁剪图像为244x244
transforms.RandomHorizontalFlip(), # 随机水平翻转图像
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0), # 改变图像的亮度
torchvision.transforms.ColorJitter(brightness=0, contrast=0.5, saturation=0, hue=0), # 改变图像的对比度
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize(mean=[0.4848, 0.4435, 0.4023], std=[0.2744, 0.2688, 0.2757]) # 对图像进行标准化
])
# 图像读取转换
all_data = torchvision.datasets.ImageFolder(
root=train_root,
transform=train_transform
)
dic = all_data.class_to_idx # 类别映射表
print(dic) # 建议大家打印一下dic,因为在进行读取图片进行分类的时候,不一定按照顺序,为了和真实数据进行比对。
# 计算每个类别的样本数量
class_counts = Counter(all_data.targets) # 假设类别信息在 all_data.targets 中
# 计算每个类别的样本权重
weights = [1.0 / class_counts[class_idx] for class_idx in all_data.targets]
# 创建一个权重采样器
sampler = WeightedRandomSampler(weights, len(all_data), replacement=True)
# 使用采样器对数据集进行划分
train_data = torch.utils.data.Subset(all_data, list(sampler))
# 获取采样器的样本索引
sampler_indices = list(sampler)
# 根据采样器的样本索引获取验证集样本索引
valid_indices = [idx for idx in range(len(all_data)) if idx not in sampler_indices]
# 创建验证集数据集
valid_data = torch.utils.data.Subset(all_data, valid_indices)
# 训练大小,随机
train_set = torch.utils.data.DataLoader(
train_data,
batch_size=BTACH_SIZE,
shuffle=True
)
# 训练大小,随机
test_set = torch.utils.data.DataLoader(
valid_data,
batch_size=BTACH_SIZE,
shuffle=False
)
# 加载预训练的 ResNet-50 模型,并替换掉最后一层全连接层(fc),使其适应当前任务(共12个类别)。
model_1 = torchvision.models.resnet50(weights='ResNet50_Weights.DEFAULT')
model_1.fc = nn.Sequential(nn.Linear(2048, 12))
# 加载已训练好的模型参数, 可选。
# model_1.load_state_dict(torch.load(r'E:\日常练习\pytorch_Project\best_model_train99.71.pth'))
# model_1.train()
# 设置模型为训练模式
model_1.to(DEVICE)
# 通过 optim.SGD(model_1.parameters(), lr=LR, momentum=0.9) 定义了 SGD 优化器。这里的 model_1.parameters() 表示优化器需要更新的模型参数,lr=LR 表示学习率为 LR,momentum=0.9 表示使用动量(momentum)参数为0.9。
optimizer = optim.SGD(model_1.parameters(), lr=LR, momentum=0.9)
# 设置初始的最高准确率为 90.0,并初始化最优模型。
max_accuracy = 90.0
# 最优模型全局变量
best_model = None
for epoch in range(1, EPOCH + 1):
train(model_1, DEVICE, train_set, optimizer, epoch)
accu = vaild(model_1, DEVICE, test_set)
# 保存准确率最高的模型
if accu > max_accuracy:
max_accuracy = accu
best_model = model_1.state_dict() # 或者使用 torch.save() 保存整个模型
# 打印最高准确率
print("最高成功率: ", max_accuracy)
# 保存最优模型
torch.save(best_model, fr"E:\best_model_train{max_accuracy:.2f}.pth")三、模型调用,以及可视化界面。
对与可视化界面,目前比较流行的是pyqt 和 gradio。两者都有各自的优势,模型训练这一块推荐大家使用gradio。(为什么呢?因为等你了解完他们的在完成模型应用的差距后,你就会明白了)
(1)、用pyqt实现的相关代码。
下面是pyqt实现的相关代码,具体解释都在代码中。(之前一直在学习pyqt6,所以就以pyqt6来实现可视化。)
from sys import argv, exit
from os.path import join, abspath, dirname
from torch import device, load, cuda, unsqueeze, max
from torch.nn import Sequential, Linear
from torchvision.models import resnet50
from PIL.Image import open
from PyQt6 import QtCore
from PyQt6.QtGui import QImage, QPixmap, QFont, QIcon
from PyQt6.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("猫的分类") # 设置窗口标题为"猫的分类"
self.central_widget = QWidget() # 创建一个中心部件
self.setCentralWidget(self.central_widget) # 将中心部件设置为窗口的中心部件
self.font = QFont()
self.font.setBold(True) # 设置字体为加粗
self.font.setPointSize(14) # 设置字体大小为14
self.image_label = QLabel(self.central_widget) # 创建一个标签用于显示图片
self.image_label.setFixedSize(self.central_widget.size()) # 设置标签大小与窗口大小一致
self.image_label.setAlignment(QtCore.Qt.AlignmentFlag.AlignCenter) # 设置标签文本居中对齐
self.result_label = QLabel(self.central_widget) # 创建一个标签用于显示分类结果
self.result_label.setWordWrap(True) # 设置标签文本自动换行
self.result_label.setAlignment(QtCore.Qt.AlignmentFlag.AlignCenter) # 设置标签文本居中对齐
self.upload_button = QPushButton("上传图片", self.central_widget) # 创建一个按钮用于上传图片
self.upload_button.setStyleSheet("background-color: Grey;") # 设置按钮的背景颜色为灰色
self.upload_button.clicked.connect(self.load_image) # 将按钮的点击事件与加载图片的方法连接起来
layout = QVBoxLayout(self.central_widget) # 创建一个垂直布局管理器
layout.addWidget(self.image_label) # 将图片标签添加到布局中
layout.addWidget(self.result_label) # 将结果标签添加到布局中
layout.addWidget(self.upload_button) # 将上传按钮添加到布局中
self.dic1 = {
0: '阿比西亚猫', 1: '孟加拉豹猫', 2: '暹罗猫', 3: '无毛猫', 9: '波斯猫', 8: '缅因猫', 11: '俄罗斯蓝猫',
10: '布偶猫', 7: '埃及猫', 6: '英国短毛猫', 4: '伯曼猫', 5: '孟买猫'
} # 创建一个字典,将类别索引与猫的品种名称对应起来和训练时打印的标签要一至
if cuda.is_available():
self.DEVICE = device('cuda') # 如果可用的话,将设备设置为CUDA
else:
self.DEVICE = device('cpu') # 否则将设备设置为CPU
self.model = resnet50() # 创建一个ResNet-50模型
# 加载权重并替换原模型的fc层
self.model.fc = Sequential(Linear(2048, 12))
# 加载保存的模型参数
self.model.load_state_dict(load(r"E:\日常练习\pytorch_Project\best_model_train99.71.pth"))
# 将模型移动到 GPU 上(如果可用的话)
self.model.to(self.DEVICE)
# 设置模型为评估模式
self.model.eval()
self.transform = Compose([
Resize((224, 224)), # 将图片调整大小为 224x224 像素
ToTensor(), # 将图片转换为张量
Normalize(mean=[0.4848, 0.4435, 0.4023], std=[0.2744, 0.2688, 0.2757]) # 对图片进行标准化处理
]) # 创建一个图片转换器,用于将上传的图片进行预处理
def load_image(self):
# 创建一个文件对话框
file_dialog = QFileDialog(self)
# 设置文件过滤器,仅显示图片文件
file_dialog.setNameFilter("Images (*.png *.jpg *.jpeg)")
# 如果对话框返回结果为 Accepted,表示用户选择了文件
if file_dialog.exec() == QFileDialog.DialogCode.Accepted:
# 获取用户选择的文件路径
selected_file = file_dialog.selectedFiles()[0]
# 使用选中的文件创建 QPixmap 对象
pixmap = QPixmap.fromImage(QImage(selected_file))
# 将 QPixmap 对象缩放到指定大小并显示在 image_label 上
self.image_label.setPixmap(pixmap.scaled(self.image_label.size()))
# 打开选中的文件并转换为 RGB 格式的图像
image = open(selected_file).convert("RGB")
# 使用预处理函数对图像进行处理
img = self.transform(image)
# 将预处理后的图像转换为指定设备上的张量
img = img.to(self.DEVICE)
# 在第一维上添加一个维度,将图像扩展为一个批次
image = unsqueeze(img, 0)
# 将图像输入模型进行推理
outputs = self.model(image)
# 从模型输出中获取预测标签
_, predicted_labels = max(outputs, dim=1)
# 获取预测结果的标签索引
want = predicted_labels.item()
# 设置结果标签的字体
self.result_label.setFont(self.font)
# 在结果标签上显示预测品种
self.result_label.setText(f"品种: {self.dic1[want]}")
if __name__ == "__main__":
# 创建应用程序对象
app = QApplication(argv)
# 设置应用程序窗口的图标
app.setWindowIcon(QIcon('1280750-200.ico'))
# 创建主窗口对象
window = MainWindow()
# 显示主窗口
window.show()
# 进入应用程序的主循环,等待事件触发
exit(app.exec())编写好代码后,如果想打包成应用,可以在终端输入:
pyinstaller -F -w --add-data "C:/path/to/model/model.pkl;model" my_pretty.py
-
-F 表示将脚本打包成单个可执行文件。
-
-w 表示以无命令行
-
C:/path/to/model/model.pkl;model 是你训练好模型绝对地址。
之前吃过亏,这里强烈建议大家把my_pretty.py也换成绝对地址。
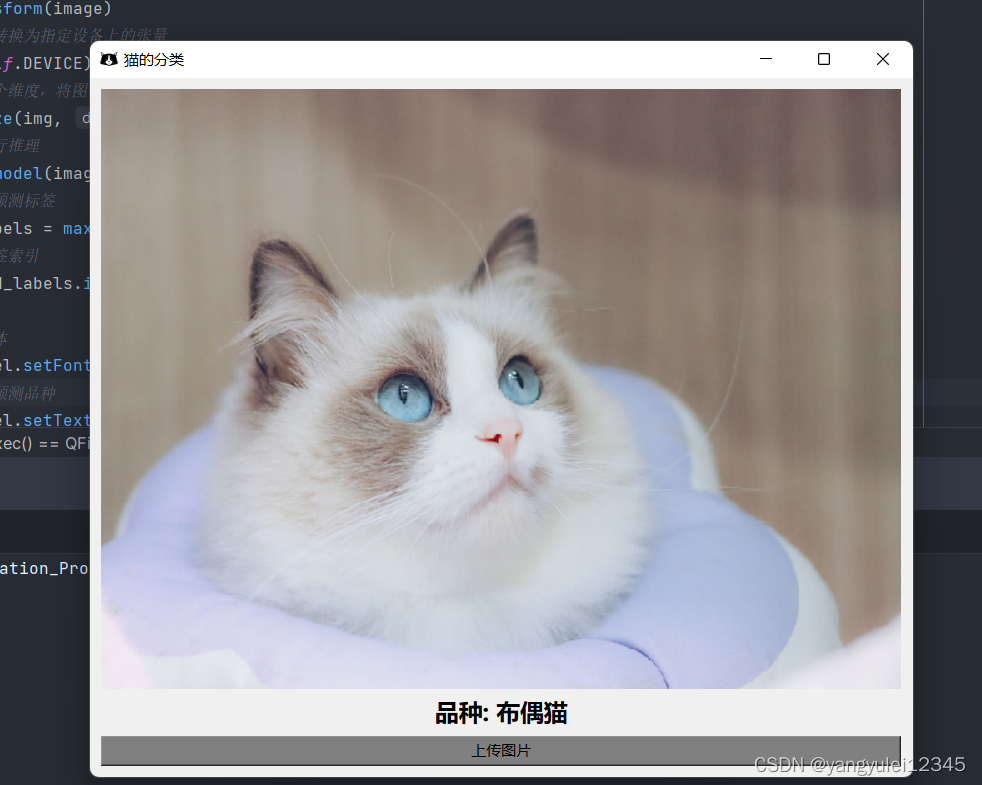
大概需要6分钟的打包时间,而且因为要调用"Gpu"的原因,应用巨大(2.74G)不建议打包:

下面是运行后的整体效果(后期大家也可以自己加一些个性化设置):
(2)、用gradio实现(推荐)。
具体解释都在代码中。(这个是团队其他成员完成的,做的都很优秀,代码风格可能和前面的不太一样。)
import torch
import torchvision
import gradio as gr
from torch import nn
import os
import pandas as pd
def serve_chicken(image, shu):
dic = {
0: '阿比西亚猫',
1: '孟加拉豹猫',
2: '暹罗猫',
3: '无毛猫',
9: '波斯猫',
8: '缅因猫',
11: '俄罗斯蓝猫',
10: '布偶猫',
7: '埃及猫',
6: '英国短毛猫',
4: '伯曼猫',
5: '孟买猫'
}
ll = torch.device('cuda')
# 创建模型实例
model = torchvision.models.resnet50()
# 加载权重并替换原模型的fc层
model.fc = nn.Sequential(nn.Linear(2048, 12))
# 加载保存的模型参数
model.load_state_dict(torch.load(r'E:\日常练习\pytorch_Project\best_model_train99.71.pth'))
# 将模型移动到 GPU 上(如果可用的话)
model.to(ll)
# 设置模型为评估模式
model.eval()
# 定义图像预处理的转换(例如,缩放、标准化、裁剪等)
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
# 将 Image 对象转换为 NumPy 数组
image = transform(image) # 使用加载的模型 model 对预处理后的图片 image 进行预测,得到输出结果 outputs,其中每个元素表示对应猫品种的得分。
image = image.to(ll)
image = torch.unsqueeze(image, 0)
ls = {}
outputs = model(image)
_, predicted_labels = torch.topk(outputs, k=shu) # 使用 torch.topk 函数找到得分最高的 shu 个猫品种的索引 predicted_labels 和对应的得分 _。
# 假设您的 Tensor 如下所示
tensor_name = predicted_labels.clone().detach() # 将预测的猫品种索引 predicted_labels 克隆为新的 Tensor tensor_name,并与计算图分离以避免梯度计算。
tensor_biaoq = _.clone().detach() # 将预测的得分 _ 克隆为新的 Tensor tensor_biaoq,并与计算图分离。
# 将 Tensor 转换为 Python 列表
values = tensor_name.tolist()[0] # 将预测的猫品种索引 tensor_name 转换为 Python 列表,并获取其中的第一个元素,存储在列表 values 中。
tensor_biaoq = tensor_biaoq.tolist()[0] # 将预测的得分 tensor_biaoq 转换为 Python 列表,并获取其中的第一个元素,存储在列表 tensor_biaoq 中。
new_values = [] # 创建一个空列表 new_values 用于存储将猫品种索引转换为具体名称后的结果。
for i in values: # 根据猫品种索引将其对应的具体名称添加到列表 new_values 中。
new_values.append(dic[i])
ls['name'] = new_values # 将转换后的猫品种名称列表 new_values 存储在字典 ls 的 ‘name’ 键下。
summ = sum([i+10 for i in tensor_biaoq]) # 计算得分列表 tensor_biaoq 中每个得分加上10后的总和,并将结果存储在变量 summ 中。
ls['biaoq'] = [(i + 10) / summ for i in tensor_biaoq] # 计算得分列表 tensor_biaoq 中每个得分加上10后的百分比,将结果存储在字典 ls 的 ‘biaoq’ 键下。
df = pd.DataFrame(ls) # 将字典 ls 转换为 Pandas DataFrame 对象 df。
res = dict(zip(df['name'], df['biaoq'])) # 将 DataFrame df 中 ‘name’ 和 ‘biaoq’ 两列转换为字典,并将结果存储在变量 res 中。
return res # 返回最终的预测结果,即猫品种名称及对应的置信度的字典。
# 样例展示图片上传
def get_img_list():
# 设置图像文件所在的文件夹路径
path = r"D:\finallycat"
# 定义支持的图像文件扩展名列表
img_extensions = ['.png']
# 创建一个空列表用于存储图像文件路径
img_list = []
# 遍历指定路径下的文件和文件夹
for file_name in os.listdir(path):
# 检查文件的扩展名是否在支持的扩展名列表中
if any(file_name.endswith(ext) for ext in img_extensions):
# 如果是图像文件,则将其完整路径添加到img_list中
img_list.append(os.path.join(path, file_name))
# 返回图像文件路径列表
return img_list
def get_selected_image(state_image_list, evt: gr.SelectData):
# 根据索引获取选中的图像文件路径
return state_image_list[evt.index]
# 文心一言
def wenxin(question):
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = "4cc775e40f9548032e4b7e8541"
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': "请给我讲解{}的具体特征,越详细越好,开头词为亲爱的用户您查询的猫品种简介如下:".format(question)}],
)
return response.result
def teac_math():
with gr.Blocks() as demo:
# 根据 get_img_list() 函数获取样例图列表
image_result_list = get_img_list() # 样例图展示
# 创建一个 State 对象,设置初始值为样例图列表
state_image_list = gr.State(value=image_result_list) # 样例图展示
# 创建一个行组件
with gr.Row(equal_height=False):
# 创建一个列组件(左侧面板)
with gr.Column(variant='panel'):
# 在左侧面板中添加一个 Markdown 组件,显示猫的品种名称
gr.Markdown('''"伯曼猫","俄罗斯蓝猫","埃及猫","孟买猫","孟加拉豹猫","布偶猫"<br/>"无毛猫","暹罗猫","波斯猫","缅因猫","英国短毛猫","阿比西亚猫"''')
# 添加一个 Gallery 组件,显示样例图
image_results = gr.Gallery(value=image_result_list, label='样例图', allow_preview=False,
columns=6, height=250)
# 创建一个输入组件列表,包括一个 Image 组件和一个 Dropdown 组件
inputs = [gr.Image(type='pil', label="传入需要预测的猫的图片"),
gr.components.Dropdown(choices=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
label="选择输出多少个猫的概率")]
# 添加一个 Button 组件,点击后执行 serve_chicken() 函数
text_button_img = gr.Button("确定上传")
# 添加一个 Label 组件,用于显示上传的猫的图片的预测结果
outputs = gr.Label(label='上传的猫的图片的预测结果为')
# 创建一个列组件(右侧面板)
with gr.Column(variant='panel'):
with gr.Box():
with gr.Row():
# 显示提示信息,要求用户输入查询的猫品种的名字
gr.Markdown("请输入需要查询猫品种的名字,获得相应的简介")
# 添加一个 Textbox 组件,用于接收用户输入的猫品种名字
text_input = gr.Textbox(label="请输入要查询猫品种的名字")
# 添加一个 Button 组件,点击后执行 wenxin() 函数
text_button = gr.Button(" 确定查询 ")
# 添加一个 Textbox 组件,用于显示查询的猫品种的简介
text_outputs = gr.Textbox(label="您查询的猫的品种的简介如下:", lines=10)
# right
# 设置 image_results 组件的选择回调函数为 get_selected_image,并传入相关参数
image_results.select(get_selected_image, state_image_list, queue=False) # 样例图展示
# 设置 text_button_img 组件的点击回调函数为 serve_chicken,并传入相关参数
text_button_img.click(fn=serve_chicken, inputs=inputs, outputs=outputs)
# left
# 设置 text_button 组件的点击回调函数为 wenxin,并传入相关参数
text_button.click(fn=wenxin, inputs=text_input, outputs=text_outputs)
return demo
if __name__ == "__main__":
# 创建一个 gradio.Blocks 对象,指定样式文件 style.css
with gr.Blocks(css='style.css') as demo:
# 在 demo 中添加一个 Markdown 组件,显示标题
gr.Markdown("# <center> \N{fire} 基于ResNet50的猫十二分类 </center>")
# 创建一个选项卡组件
with gr.Tabs():
# 在选项卡中添加一个TabItem,展示猫十二分类预测
with gr.TabItem('\N{clapper board} 猫十二分类预测'):
teac_math() # 调用 teac_math() 函数进行猫十二分类预测
# 启动 demo
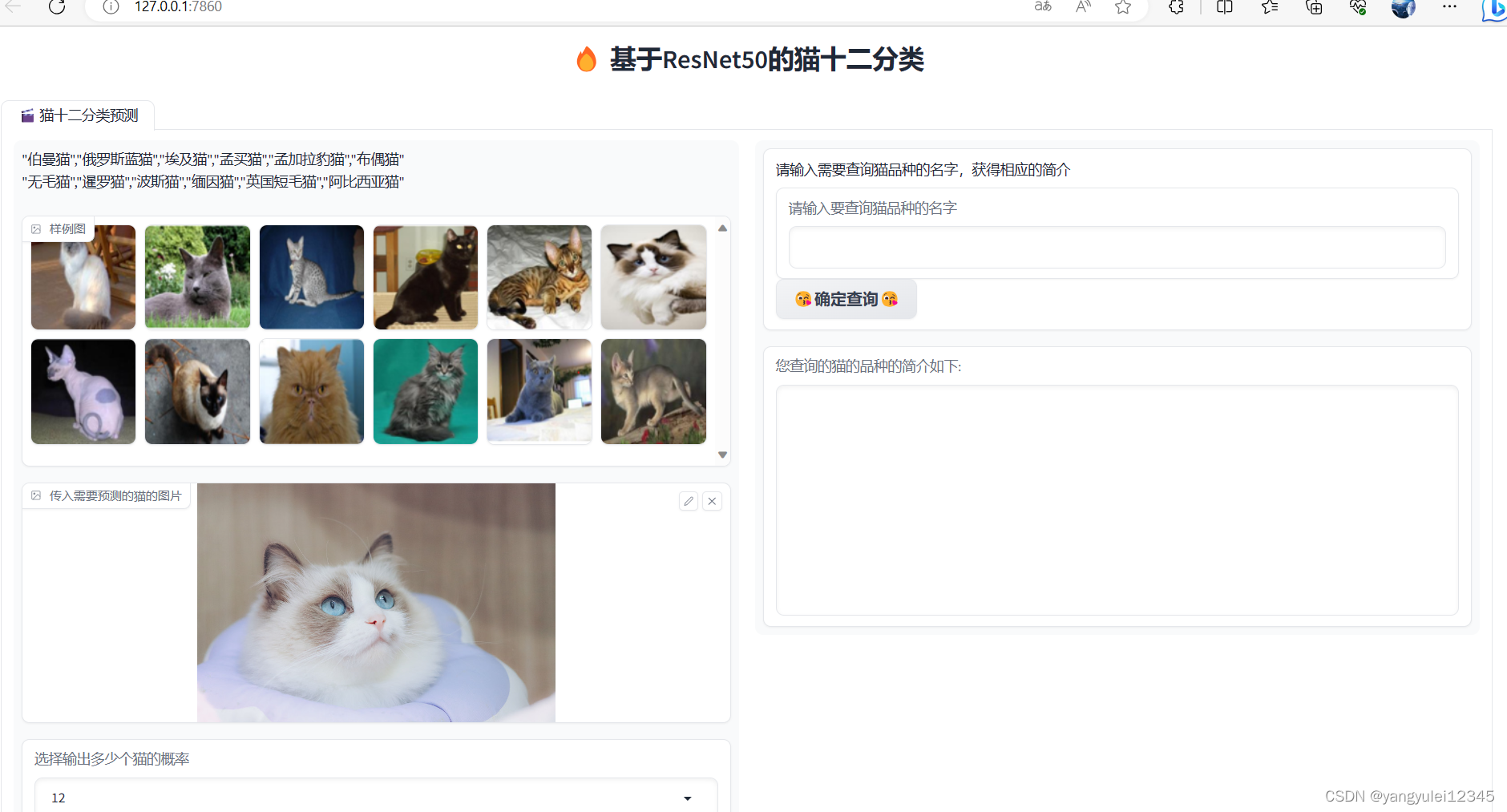
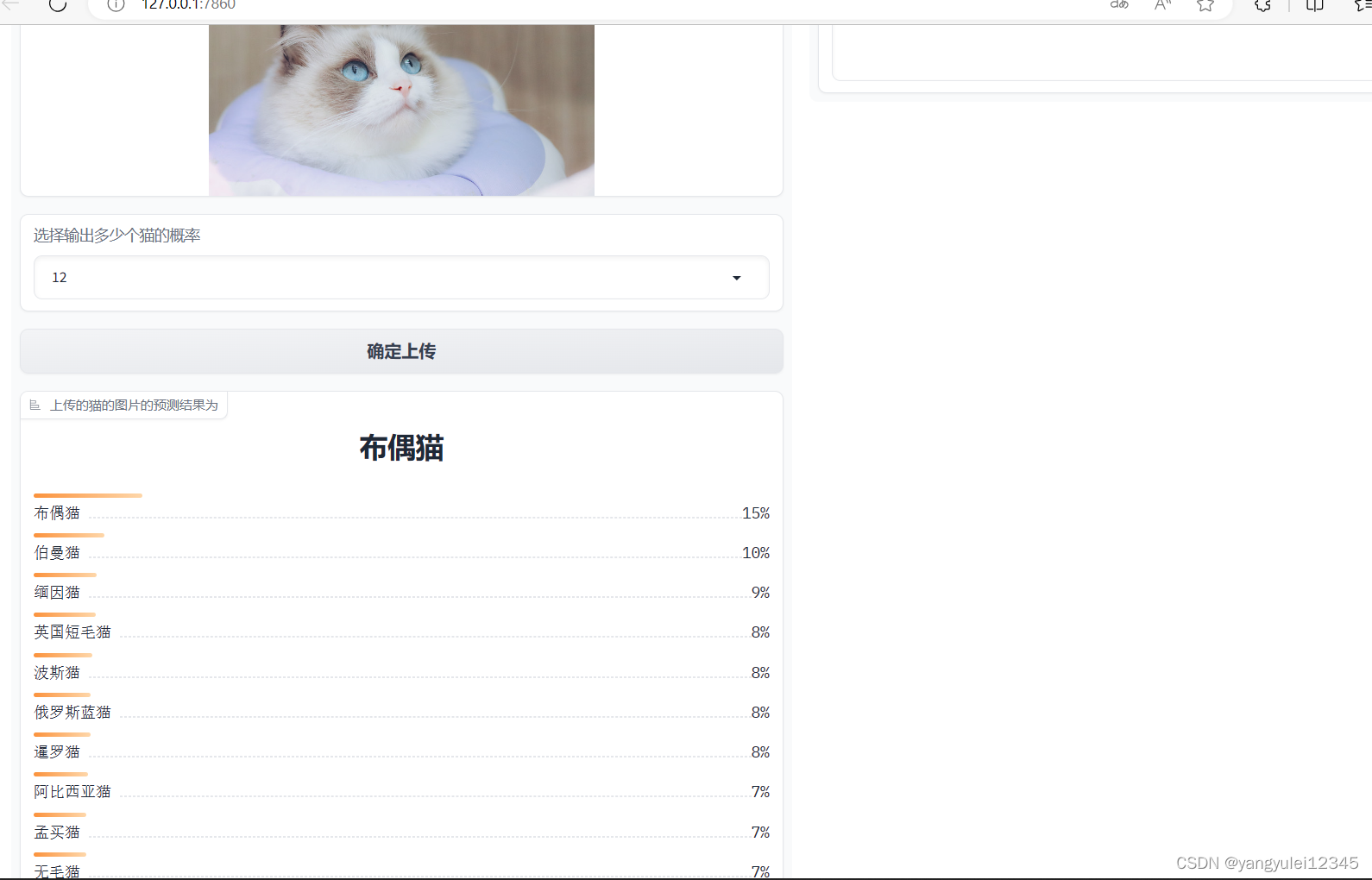
demo.launch()为大家展示一下效果图(Gradio 提供了一种简单、快速和灵活的方式来构建交互式界面,使开发者能够快速实现模型的可视化和演示。对目前的大多深度库都兼容,所以还是推荐用这个)。
总结
最后,感谢大家的观看,同时也希望有不同的意见和想法在评论区进行交流。下一期将带来yolov8的实战项目,可以多关注我们哦~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











