







Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。Impala 为存储在 HDFS 和 HBase 中的数据提供了一个实时 SQL 查询接口。
Impala优点
下图来自zdnet,描述了Impala的一些优点:

从上图中看出主要的优点:SQL友好,比Hive快,支持多种存储引擎文件格式,接口丰富(ODBC,JDBC,Client),开源,部署容易。
Impala架构
Impala解决方案包含下面几大部分:
Clients:包括 Hue, ODBC clients, JDBC clients, and the Impala Shell
Hive Metastore:存放结构定义的元数据,当你创建、删除、修改表结构,或者加载数据到表中时,会自动的通知Impala节点。
Cloudera Impala:运行在数据节点上,分析、调度、执行查询任务,每个Impala实例都可以接收、调度来自客户端的查询,这些查询分发到Impala节点进行查询,Impala节点相当于工作进程,执行查询,并将结果返回。
HBase and HDFS:存储供Impala查询的数据。
下图描述了Impala的架构:
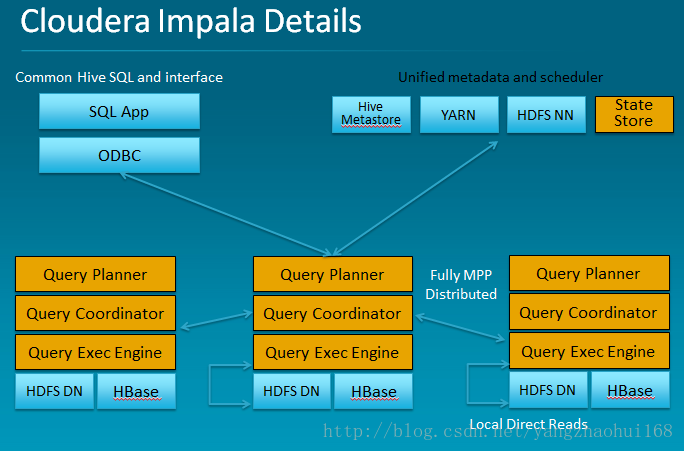
上图中,黄色部分为Impala组件。Impala使用了Hive的SQL接口(包括SELECT、 INSERT、Join等操作),但目前只实现了Hive的SQL语义的子集(例如尚未对UDF提供支持),表的元数据信息存储在Hive的 Metastore中。StateStore是Impala的一个子服务,用来监控集群中各个节点的健康状况,提供节点注册、错误检测等功能。 Impala在每个节点运行了一个后台服务Impalad,Impalad用来响应外部请求,并完成实际的查询处理。Impalad主要包含Query Planner、Query Coordinator和Query Exec Engine三个模块。QueryPalnner接收来自SQL APP和ODBC的查询,然后将查询转换为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的Query Exec Engine负责子查询的执行,最后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
Impala进程
从进程的角度看分为如下的三类进程:
The Impala Daemon
是Impala的核心进程,进程名叫做:impalad,运行在所有的数据节点上,可以读写数据,并接收客户端的查询请求,并行执行来自集群中其他节点的查询请求,将中间结果返回给调度节点。调用节点将结果返回给客户端。
The Impala Statestore
状态管理进程,定时检查The Impala Daemon的健康状况,协调各个运行impalad的实例之间的信息关系,Impala正是通过这些信息去定位查询请求所要的数据,进程名叫做statestored,在集群中只需要启动一个这样的进程,如果Impala节点由于物理原因、网络原因、软件原因或者其他原因而下线,Statestore会通知其他节点,避免查询任务分发到不可用的节点上。
The Impala Catalog Service
元数据管理服务,进程名叫做 catalogd,用于广播Impala中DDL、DML语句导致的元数据变化到所有Impala节点,因此新建表、新载入数据、等等操作对于任意节点提交的查询都可见(Impala 1.2之前,你必须在每个节点上执行 REFRESH 或 INVALIDATE METADATA 语句以同步元数据的更新。现在只需要在Hive中执行DDL、DML语句之后再执行这些语句)。
在搭建的CDH5环境上找到了这些进程:
| hostname | 进程名称 |
|---|---|
| h1.worker.com | statestored、catalogd |
| h2.worker.com | impalad |
| h3.worker.com | impalad |
| h4.worker.com | impalad |
[root@h1 ~]# hostname
h1.worker.com
[root@h1 ~]# ps -ef | grep impala
impala 14048 7910 0 04:13 ? 00:00:30 /opt/cloudera/parcels/CDH-5.0.2-1.cdh5.0.2.p0.13/lib/impala/sbin-retail/catalogd --flagfile=/var/run/cloudera-scm-agent/process/57-impala-CATALOGSERVER/impala-conf/catalogserver_flags
impala 14070 7910 0 04:13 ? 00:03:01 /opt/cloudera/parcels/CDH-5.0.2-1.cdh5.0.2.p0.13/lib/impala/sbin-retail/statestored --flagfile=/var/run/cloudera-scm-agent/process/61-impala-STATESTORE/impala-conf/state_store_flags
root 48029 31543 0 10:13 pts/0 00:00:00 grep impala
[root@h1 ~]# [root@h2 ~]# hostname
h2.worker.com
[root@h2 ~]# ps -ef | grep impala
impala 13919 4405 0 04:13 ? 00:01:12 /opt/cloudera/parcels/CDH-5.0.2-1.cdh5.0.2.p0.13/lib/impala/sbin-retail/impalad --flagfile=/var/run/cloudera-scm-agent/process/58-impala-IMPALAD/impala-conf/impalad_flags
root 24212 18173 0 10:16 pts/0 00:00:00 grep impalaImpala快的原因
从网上找了一段Impala快的原因,主要有以下几方面的原因。
- Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
- 省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
- Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
- 通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
- 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
- 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
Impala源代码
https://github.com/cloudera/impala
后面重点分析下Impala的源代码。个人感觉和分布式数据库查询引擎的架构比较类型。
参考文档
Cloudera aims to bring real-time queries to Hadoop, big data
原创作品,转载请注明出处 http://blog.csdn.net/yangzhaohui168/article/details/34185579















 2019
2019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









