







lambda之Stream流式编程
一、什么是 Stream
Stream中文称为 “流”,通过将集合转换为这么一种叫做“流”的元素序列,通过声明性方式,能够对集合中的每个元素进行一系列并行或串行的流水线操作。换句话说,你只需要告诉流你的要求,流便会在背后自行根据要求对元素进行处理,而你只需要 “坐享其成”。
二、流操作
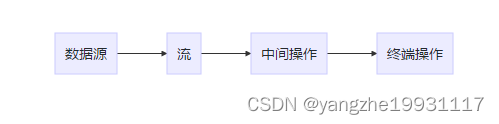
整个流操作就是一条流水线,将元素放在流水线上一个个地进行处理。其中数据源便是原始集合,然后将如 List 的集合转换为 Stream 类型的流,并对流进行一系列的中间操作,比如过滤保留部分元素、对元素进行排序、类型转换等;最后再进行一个终端操作,可以把 Stream 转换回集合类型,也可以直接对其中的各个元素进行处理,比如打印、比如计算总数、计算最大值等等。很重要的一点是,很多流操作本身就会返回一个流,所以多个操作可以直接连接起来,我们来看看一条 Stream 操作的代码:

如果是以前,进行这么一系列操作,你需要做个迭代器或者 foreach 循环,然后遍历,一步步地亲力亲为地去完成这些操作;但是如果使用流,你便可以直接声明式地下指令,流会帮你完成这些操作。
有没有想到什么类似的?是的,就像 SQL 语句一样, select username from user where id = 1,你只要说明:“我需要 id 是 1 (id = 1)的用户(user)的用户名(username )”,那么就可以得到自己想要的数据,而不需要自己亲自去数据库里面循环遍历查找。
三、流与集合
什么时候计算
- Stream 和集合的其中一个差异在于什么时候进行计算。
一个集合,它会包含当前数据结构中所有的值,你可以随时增删,但是集合里面的元素毫无疑问地都是已经计算好了的。
流则是按需计算,你可以想象一个水龙头,假设你需要一个奇数流,从 1 开始,那么这个水龙头会源源不断地流出你需要的数据,假设你只需要 10 个,那么这个流便会按需生成 10 个奇数,换句话来说,就是在用户要求的时候才会计算值,只要你需要,你便可以打开这个水龙头。
又比方说我们通过搜索引擎进行搜索,搜索出来的条目并不是全部呈现出来的,而且先显示最符合的前 10 条或者前 20 条,只有在点击 “下一页” 的时候,才会再输出新的 10 条。
再比方在线观看电影和你硬盘里面的电影,也是差不多的道理。
外部迭代和内部迭代
- Stream 和集合的另一个差异在于迭代。
我们可以把集合比作一个工厂的仓库,一开始工厂比较落后,要对货物作什么修改,只能工人亲自走进仓库对货物进行处理,有时候还要将处理后的货物放到一个新的仓库里面。在这个时期,我们需要亲自去做迭代,一个个地找到需要的货物,并进行处理,这叫做外部迭代。
后来工厂发展了起来,配备了流水线作业,只要根据需求设计出相应的流水线,然后工人只要把货物放到流水线上,就可以等着接收成果了,而且流水线还可以根据要求直接把货物输送到相应的仓库。这就叫做内部迭代,流水线已经帮你把迭代给完成了,你只需要说要干什么就可以了(即设计出合理的流水线)。
Java 8 引入 Stream 很大程度是因为,流的内部迭代可以自动选择一种合适你硬件的数据表示和并行实现;而以往程序员自己进行 foreach 之类的时候,则需要自己去管理并行等问题。
一次性的流
流和迭代器类似,只能迭代一次。
Stream<String> stream = list.stream().map(Person::getName).sorted().limit(10);
List<String> newList = stream.collect(Collectors.toList());
List<String> newList2 = stream.collect(Collectors.toList());
上面代码中第三行会报错,因为第二行已经使用过这个流,这个流已经被消费掉了。
四、 一般方法
首先我们先创建一个 Person 泛型的 List
List<Person> list = new ArrayList<>();
list.add(new Person("jack", 20));
list.add(new Person("mike", 25));
list.add(new Person("tom", 30));
Person 类包含年龄和姓名两个成员变量
private String name;
private int age;
4.1、 stream() / parallelStream()
最常用到的方法,将集合转换为流
List list = new ArrayList();
// return Stream<E>
list.stream();
而 parallelStream() 是并行流方法,能够让数据集执行并行操作,后面会更详细地讲解。
4.2、filter(T -> boolean)
保留 boolean 为 true 的元素
//保留年龄为 20 的 person 元素
list = list.stream()
.filter(person -> person.getAge() == 20)
.collect(Collectors.toList());
//打印输出 [Person{name='jack', age=20}]
collect(toList()) 可以把流转换为 List 类型,这个以后会讲解。
4.3、distinct()
去除重复元素,这个方法是通过类的 equals 方法来判断两个元素是否相等的
如例子中的 Person 类,需要先定义好 equals 方法,不然类似[Person{name='jack', age=20}, Person{name='jack', age=20}] 这样的情况是不会处理的。
4.4、sorted() / sorted((T, T) -> int)
如果流中的元素的类实现了 Comparable 接口,即有自己的排序规则,那么可以直接调用 sorted()方法对元素进行排序,如 Stream
反之, 需要调用 sorted((T, T) -> int) 实现 Comparator 接口
根据年龄大小来比较:
list = list.stream()
.sorted((p1, p2) -> p1.getAge() - p2.getAge())
.collect(Collectors.toList());
当然这个可以简化为
list = list.stream()
.sorted(Comparator.comparingInt(Person::getAge))
.collect(Collectors.toList());
4.4.1、数字排序
/**
* 数字排序
*/
public static void testIntegerSort() {
List<Integer> list = Arrays.asList(4, 2, 5, 3, 1);
System.out.println(list);//执行结果:[4, 2, 5, 3, 1]
//升序
list.sort((a, b) -> a.compareTo(b.intValue()));
System.out.println(list);//执行结果:[1, 2, 3, 4, 5]
//降序
list.sort((a, b) -> b.compareTo(a.intValue()));
System.out.println(list);//执行结果:[5, 4, 3, 2, 1]
}
4.4.2、字符串排序
/**
* 字符串排序
*/
public static void testStringSort() {
List<String> list = new ArrayList<>();
list.add("aa");
list.add("cc");
list.add("bb");
list.add("ee");
list.add("dd");
System.out.println(list);//执行结果:aa, cc, bb, ee, dd
//升序
list.sort((a, b) -> a.compareTo(b.toString()));
System.out.println(list);//执行结果:[aa, bb, cc, dd, ee]
//降序
list.sort((a, b) -> b.compareTo(a.toString()));
System.out.println(list);//执行结果:[ee, dd, cc, bb, aa]
}
4.4.3、对象字段排序
class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* 对象串排序
*/
public void testObjectSort() {
List<Person> list = new ArrayList<>();
list.add(new Person("三炮", 48));
list.add(new Person("老王", 35));
list.add(new Person("小明", 8));
list.add(new Person("叫兽", 70));
System.out.println(list); //执行结果:[Person{name='三炮', age=48}, Person{name='老王', age=35}, Person{name='小明', age=8}, Person{name='叫兽', age=70}]
//按年龄升序
list.sort((a, b) -> Integer.compare(a.age, b.getAge()));
System.out.println(list);//执行结果:[Person{name='小明', age=8}, Person{name='老王', age=35}, Person{name='三炮', age=48}, Person{name='叫兽', age=70}]
//按年龄降序
list.sort((a, b) -> Integer.compare(b.age, a.getAge()));
System.out.println(list);//执行结果:[Person{name='叫兽', age=70}, Person{name='三炮', age=48}, Person{name='老王', age=35}, Person{name='小明', age=8}]
//如果按姓名排序,其实就是按字符串排序一样
}
4.5、limit(long n)
返回前 n 个元素
list = list.stream()
.limit(2)
.collect(Collectors.toList());
//打印输出 [Person{name='jack', age=20}, Person{name='mike', age=25}]
4.6、skip(long n)
去除前 n 个元素
list = list.stream()
.skip(2)
.collect(Collectors.toList());
//打印输出 [Person{name='tom', age=30}]
tips:
skip(m)用在 limit(n) 前面时,先去除前 m 个元素再返回剩余元素的前 n 个元素。
limit(n) 用在 skip(m) 前面时,先返回前 n 个元素再在剩余的 n 个元素中去除 m 个元素。
list = list.stream()
.limit(2)
.skip(1)
.collect(Collectors.toList());
//打印输出 [Person{name='mike', age=25}]
4.7、map(T -> R)
将流中的每一个元素 T 映射为 R(类似类型转换)
List<String> newlist = list.stream().map(Person::getName).collect(Collectors.toList());
newlist 里面的元素为 list 中每一个 Person 对象的 name 变量。
4.8、flatMap(T -> Stream)
将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流。
List<String> list = new ArrayList<>();
list.add("aaa bbb ccc");
list.add("ddd eee fff");
list.add("ggg hhh iii");
list = list.stream().map(s -> s.split(" ")).flatMap(Arrays::stream).collect(toList());
上面例子中,我们的目的是把 List 中每个字符串元素以“”分割开,变成一个新的 List。
首先 map 方法分割每个字符串元素,但此时流的类型为 Stream。
4.9、anyMatch(T -> boolean)
流中是否有一个元素匹配给定的 T -> boolean 条件
是否存在一个 person 对象的 age 等于 20:
boolean b = list.stream().anyMatch(person -> person.getAge() == 20);
4.10、 allMatch(T -> boolean)
流中是否所有元素都匹配给定的 T -> boolean 条件
boolean result = list.stream().allMatch(Person::isStudent);
4.11、noneMatch(T -> boolean)
流中是否没有元素匹配给定的 T -> boolean 条件
boolean result = list.stream().noneMatch(Person::isStudent);
4.12、findAny() 和 findFirst()
findAny():找到其中一个元素 (使用 stream() 时找到的是第一个元素;使用 parallelStream()并行时找到的是其中一个元素)
findFirst():找到第一个元素
值得注意的是,这两个方法返回的是一个 Optional 对象,它是一个容器类,能代表一个值存在或不存在,这个后面会讲到。
4.13、reduce((T, T) -> T) 和 reduce(T, (T, T) -> T)
归约是将集合中的所有元素经过指定运算,折叠成一个元素输出,如:求最值、平均数等,这些操作都是将一个集合的元素折叠成一个元素输出。
在流中,reduce函数能实现归约。
reduce函数接收两个参数:
初始值
进行归约操作的Lambda表达式
用于组合流中的元素,如求和,求积,求最大值等
int age = list.stream().reduce(0, (person1,person2)->person1.getAge()+person2.getAge());
//计算年龄总和:
int sum = list.stream().map(Person::getAge).reduce(0, (a, b) -> a + b);
//与之相同:
int sum = list.stream().map(Person::getAge).reduce(0, Integer::sum);
其中,reduce 第一个参数 0 代表起始值为 0,lambda (a, b) -> a + b 即将两值相加产生一个新值
同样地:
//计算年龄总乘积:
int sum = list.stream().map(Person::getAge).reduce(1, (a, b) -> a * b);
当然也可以
Optional<Integer> sum = list.stream().map(Person::getAge).reduce(Integer::sum);
即不接受任何起始值,但因为没有初始值,需要考虑结果可能不存在的情况,因此返回的是 Optional 类型
4.14、count()
返回流中元素个数,结果为 long 类型。
4.15、collect()
收集方法,我们很常用的是 collect(toList()),当然还有 collect(toSet()) 等,参数是一个收集器接口,这个后面会另外讲。
4.16、forEach()
返回结果为 void,很明显我们可以通过它来干什么了,比方说:
//打印各个元素:
list.stream().forEach(System.out::println);
再比如说 MyBatis 里面访问数据库的 mapper 方法:
//向数据库插入新元素:
list.stream().forEach(PersonMapper::insertPerson);
4.17、unordered()
还有这个比较不起眼的方法,返回一个等效的无序流,当然如果流本身就是无序的话,那可能就会直接返回其本身















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









