







每次翻译外文文献的时候,把英文复制到谷歌翻译,会出现PDF格式的文本的换行很麻烦,需要手动来删除换行,影响翻译时思考的质量。
于是,我可不可以用python来解决这个问题呢?
with open('etext.txt','r') as fp:
data = fp.readlines()
data = [line.strip() for line in data]
data = ','.join(data)
data = data.split(',')
data = ' '.join(map(str,data))
with open('welltext.txt','w') as fp:
fp.write(data)
这样就能将
It is widely recognized that a visual texture, which humans
can easily perceive, is very difficult to define [17]. The difficulty
results mainly from the fact that different people can define textures
in application-dependent ways or with different perceptual
motivations, and there is no generally agreed-upon definition
[44]. It is not our intention to add here a new one: we simply
observe that it should be as general as possible, because a too
strict definition would allow one to confine his/her work to images
that better fit with it, eventually leading to narrow-domain
solutions.转换成
It is widely recognized that a visual texture which humans can easily perceive is very difficult to define [17]. The difficulty results mainly from the fact that different people can define textures in application-dependent ways or with different perceptual motivations and there is no generally agreed-upon definition [44]. It is not our intention to add here a new one: we simply observe that it should be as general as possible because a too strict definition would allow one to confine his/her work to images that better fit with it eventually leading to narrow-domain solutions.在谷歌翻译里就是从这样
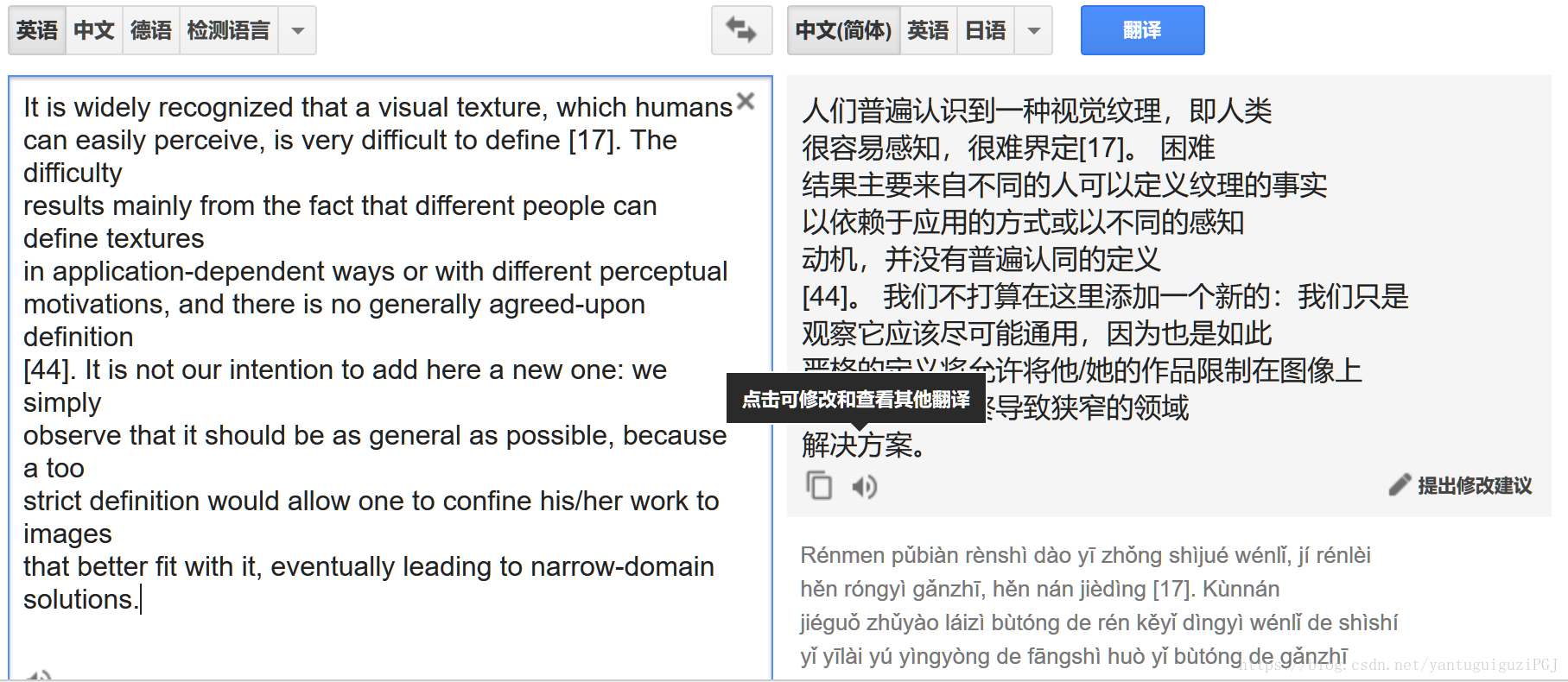
到这样
















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











