







在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的;若具有相同关键字的记录之间的相对次序发生改变,则称这种排序方法是不稳定的。即所有相等的数经过某种排序方法后,仍能保持它们在排序之前的相对次序,则说这种排序算法是稳定的,反之,就是不稳定的。
| 稳定的排序 | 时间复杂度 | 空间复杂度 |
| 冒泡排序(bubble sort) | 最差、平均都是O(n^2),最好是O(n) | 1 |
| 插入排序(insertion sort) | 最差、平均都是O(n^2),最好是O(n) | 1 |
| 归并排序(merge sort) | 最差、平均、最好都是O(n log n) | O(n) |
| 桶排序(bucket sort) | O(n) | O(k) |
| 基数排序(Radix sort) | O(dn)(d是常数) | O(n) |
| 二叉树排序(Binary tree sort) | O(n log n) | O(n) |
| 不稳定的排序 | 时间复杂度 | 空间复杂度 |
| 选择排序(selection sort) | 最差、平均都是O(n^2) | 1 |
| 希尔排序(shell sort) | O(n log n) | 1 |
| 堆排序(heapsort) | 最差、平均、最好都是O(n log n) | 1 |
| 快速排序(quicksort) | 平均是O(n log n),最差是O(n^2) | O(log n) |
1、冒泡排序
冒泡排序(BubbleSort)的基本概念是:依次比较相邻的两个数,将小数放在前面,大数放在后面。即在第一趟:首先比较第1个和第2个数,将小数放前,大数放后。然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后。至此第一趟结束,将最大的数放到了最后。在第二趟:仍从第一对数开始比较(因为可能由于第2个数和第3个数的交换,使得第1个数不再小于第2个数),将小数放前,大数放后,一直比较到倒数第二个数(倒数第一的位置上已经是最大的),第二趟结束,在倒数第二的位置上得到一个新的最大数(其实在整个数列中是第二大的数)。如此下去,重复以上过程,直至最终完成排序。
2、插入排序
思想:在一个已经排好序的序列中,将未被排进的元素按照原先的规定插入到指定位置。
- void InsSort(RecordType r[], int length)
- {
- for(i = 2; I <= length; i++)
- {
- r[0] = r[i];
- j = i – 1;
- while(r[0].key < r[j].key)
- {
- r[j + 1] = r[j]; j = j – 1;
- }
- r[j+1] = r[0];
- }
- }
- void BinSort(RecordType r[], int length)
- {
- for(i = 2; i <= length; i++)
- {
- x = r[i];
- low = 1; high = i – 1;
- while(low <= high)
- {
- mid = (low + high) / 2;
- if(x.key < r[mid].key)
- high = mid – 1;
- else
- low = mid – 1;
- }
- for(j = i – 1; j >= low; --j)
- r[j + 1] = r[j];
- r[low] = x;
- }
- }
归并排序是将两个或两个以上的有序子表合并成一个新的有序表。初始时,把含有n个结点的待排序序列看作由n个长度都为1的有序子表组成,将它们依次两两归并得到长度为2的若干有序子表,再对它们两两合并。直到得到长度为n的有序表,排序结束。
1、申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
2、设定两个指针,最初位置分别为两个已经排序序列的起始位置
3、比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
4、重复步骤3直到某一指针达到序列尾
5、将另一序列剩下的所有元素直接复制到合并序列尾

桶排序的基本思想就是把区间[0,1)划分成n个相同大小的子区间,或称桶,然后将n个输入数分布到各个桶中去。因为输入数均匀分布在[0,1)上,所以一般不会有很多数落在 一个桶中的情况。为得到结果,先对各个桶中的数进行排序,然后按次序把各桶中的元素列出来即可。
在桶排序算法的代码中,假设输入是个含n个元素的数组A,且每个元素满足0≤ A[i]<1。另外还需要一个辅助数组B[O..n-1]来存放链表实现的桶,并假设可以用某种机制来维护这些表。

http://book.51cto.com/art/201405/441260.htm
首先我们需要申请一个大小为11的数组int a[11]。OK,现在你已经有了11个变量,编号从a[0]~a[10]。刚开始的时候,我们将a[0]~a[10]都初始化为0,表示这些分数还都没有人得过。例如a[0]等于0就表示目前还没有人得过0分,同理a[1]等于0就表示目前还没有人得过1分……a[10]等于0就表示目前还没有人得过10分。

下面开始处理每一个人的分数,第一个人的分数是5分,我们就将相对应的a[5]的值在原来的基础增加1,即将a[5]的值从0改为1,表示5分出现过了一次。

第二个人的分数是3分,我们就把相对应的a[3]的值在原来的基础上增加1,即将a[3]的值从0改为1,表示3分出现过了一次。

注意啦!第三个人的分数也是5分,所以a[5]的值需要在此基础上再增加1,即将a[5]的值从1改为2,表示5分出现过了两次。

按照刚才的方法处理第四个和第五个人的分数。最终结果就是下面这个图啦。

最终屏幕输出“2 3 5 5 8”
6、基数排序



平均时间复杂度:O(dn)(d即表示整形的最高位数)
空间复杂度:O(10n) (10表示0~9,用于存储临时的序列)
稳定性:稳定
http://blog.csdn.net/cjf_iceking/article/details/7943609
7、二叉树排序
二叉排序树(Binary Sort Tree)又称二叉查找树。它或者是一棵空树;或者是具有下列性质的二叉树:
8、简单选择排序
① 思想:第一趟时,从第一个记录开始,通过n – 1次关键字的比较,从n个记录中选出关键字最小的记录,并和第一个记录进行交换。第二趟从第二个记录开始,选择最小的和第二个记录交换。以此类推,直至全部排序完毕。
② 时间复杂度:T(n) = O(n²)。
③ 空间复杂度:S(n) = O(1)。
④ 稳定性:不稳定排序,{3, 3, 2}。
⑤ 程序:
9、树形简单排序
① 思想:为了减少比较次数,两两进行比较,得出的较小的值再两两比较,直至得出最小的输出,然后在原来位置上置为∞,再进行比较。直至所有都输出。
② 时间复杂度:T(n) = O(n㏒n)。
③ 空间复杂度:较简单选择排序,增加了n-1个额外的存储空间存放中间比较结果,就是树形结构的所有根节点。S(n) = O(n)。
④ 稳定性:稳定排序。
10、堆排序
思想:把待排序记录的关键字存放在数组r[1…n]中,将r看成是一刻完全二叉树的顺序表示,每个节点表示一个记录,第一个记录r[1]作为二叉树的根,一下个记录r[2…n]依次逐层从左到右顺序排列,任意节点r[i]的左孩子是r[2i],右孩子是r[2i+1],双亲是r[i/2向下取整]。然后对这棵完全二叉树进行调整建堆。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个最小堆:
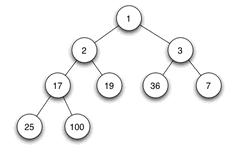
由于其它几种堆(二项式堆,斐波纳契堆等)用的较少,一般将二叉堆就简称为堆。
堆的存储
一般都用数组来表示堆,i结点的父结点下标就为(i – 1) / 2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。

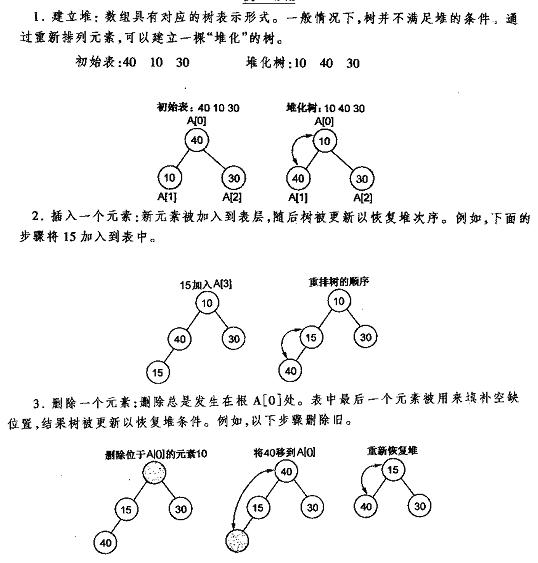
堆的操作——插入删除
下面先给出《数据结构C++语言描述》中最小堆的建立插入删除的图解,再给出本人的实现代码,最好是先看明白图后再去看代码。
堆化数组
有了堆的插入和删除后,再考虑下如何对一个数据进行堆化操作。要一个一个的从数组中取出数据来建立堆吧,不用!先看一个数组,如下图:
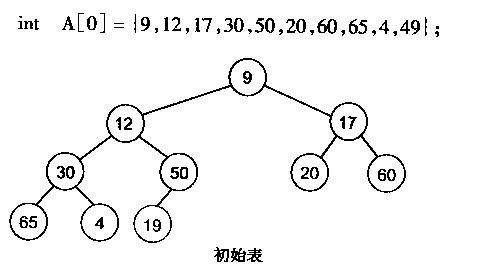
很明显,对叶子结点来说,可以认为它已经是一个合法的堆了即20,60, 65, 4, 49都分别是一个合法的堆。只要从A[4]=50开始向下调整就可以了。然后再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分别作一次向下调整操作就可以了。下图展示了这些步骤:
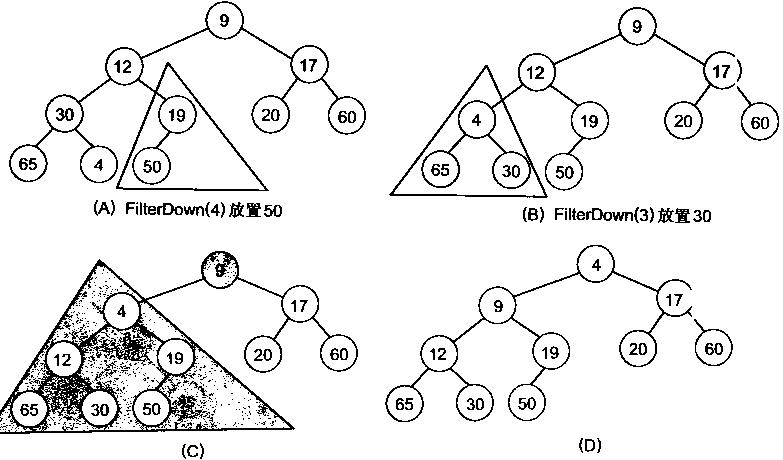
写出堆化数组的代码:
至此,堆的操作就全部完成了(注1),再来看下如何用堆这种数据结构来进行排序。
首先可以看到堆建好之后堆中第0个数据是堆中最小的数据。取出这个数据再执行下堆的删除操作。这样堆中第0个数据又是堆中最小的数据,重复上述步骤直至堆中只有一个数据时就直接取出这个数据。
由于堆也是用数组模拟的,故堆化数组后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n - 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。、
11、希尔排序
希尔(Shell)排序的基本思想是:先取一个小于n的整数d1作为第一个增量把文件的全部记录分成d1个组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取得第二个增量d2<d1重复上述的分组和排序,直至所取的增量di=1,即所有记录放在同一组中进行直接插入排序为止。该方法实质上是一种分组插入方法。

12、快速排序
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 72 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 88 | 85 |
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 48 | 6 | 57 | 42 | 60 | 72 | 83 | 73 | 88 | 85 |
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。















 5006
5006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









