







ArrayList和HashMap是Java项目开发中经常用到的容器,下面来比较一下两者之间的区别!
例子:
ArrayList:
// ArrayList
List<String> list = new ArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
list.add(null);
System.out.println("list的元素个数为:" + list.size());
// 遍历方法一:通过迭代器Iterator进行遍历
System.out.println("遍历方法一:通过迭代器Iterator进行遍历");
Iterator iter = list.iterator();
while (iter.hasNext()) {
String name = (String) iter.next();
System.out.println(name);
}
// 遍历方法二:使用for循环遍历
System.out.println("遍历方法二:使用for循环遍历");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// 遍历方法三:使用stream的forEach循环遍历(JDK1.8后新增)
System.out.println("遍历方法三:使用stream的forEach循环遍历(JDK1.8后新增)");
list.forEach(item -> System.out.println(item));输出结果如下:
list的元素个数为:4
遍历方法一:通过迭代器Iterator进行遍历
张三
李四
王五
null
遍历方法二:使用for循环遍历
张三
李四
王五
null
遍历方法三:使用stream的forEach循环遍历(JDK1.8后新增)
张三
李四
王五
nullHashMap:
// HashMap
Map<String, String> hashMap = new HashMap();
hashMap.put("name", "张三");
hashMap.put("name1", "李四");
hashMap.put("name2", "王五");
hashMap.put(null, null);
System.out.println("HashMap的元素个数为:" + hashMap.size());
// 遍历方法一:hashMap.entrySet()方法,通过迭代器Iterator进行遍历 效率高,推荐使用
System.out.println("遍历方法一:hashMap.entrySet()方法,通过迭代器Iterator进行遍历");
Iterator iter1 = hashMap.entrySet().iterator();
while (iter1.hasNext()) {
Map.Entry<String, String> name = (Map.Entry) iter1.next();
System.out.print("[key=" + name.getKey() + ", value=" + name.getValue() + "] ");
}
// 遍历方法二:hashMap.keySet()方法,通过迭代器Iterator进行遍历 效率低,不推荐使用
System.out.println("");
System.out.println("遍历方法二:hashMap.keySet()方法,通过迭代器Iterator进行遍历");
Iterator iter2 = hashMap.keySet().iterator();
while (iter2.hasNext()) {
Object key = iter2.next();
System.out.print("[key=" + key + ", value=" + hashMap.get(key) + "] ");
}
// 遍历方法三:foreach方法来遍历keySet,和第二种没有什么区别
System.out.println("");
System.out.println("遍历方法三:foreach方法来遍历keySet");
Set keySet = hashMap.keySet();
for (Object key : keySet) {
System.out.print("[key=" + key + ", value=" + hashMap.get(key) + "] ");
}
// 遍历方法四:使用stream的forEach(JDK1.8后新增)
System.out.println("");
System.out.println("遍历方法四:使用stream的forEach(JDK1.8后新增)");
hashMap.forEach((key, value) -> {
System.out.print("[key=" + key + ",value=" + value + "] ");
});输出结果如下:
HashMap的元素个数为:4
遍历方法一:hashMap.entrySet()方法,通过迭代器Iterator进行遍历
[key=null, value=null] [key=name, value=张三] [key=name2, value=王五] [key=name1, value=李四]
遍历方法二:hashMap.keySet()方法,通过迭代器Iterator进行遍历
[key=null, value=null] [key=name, value=张三] [key=name2, value=王五] [key=name1, value=李四]
遍历方法三:foreach方法来遍历keySet
[key=null, value=null] [key=name, value=张三] [key=name2, value=王五] [key=name1, value=李四]
遍历方法四:使用stream的forEach(JDK1.8后新增)
[key=null,value=null] [key=name,value=张三] [key=name2,value=王五] [key=name1,value=李四] 相同点:
1)都是线程不安全,不同步
2)都可以储存null值
3)获取元素个数方法一样,都用size()方法获取
区别:
1)实现的接口
ArrayList实现了List接口(Iterable(接口)-> Collection(接口)-> List(接口)-> ArrayList(类)),底层使用的是数组;
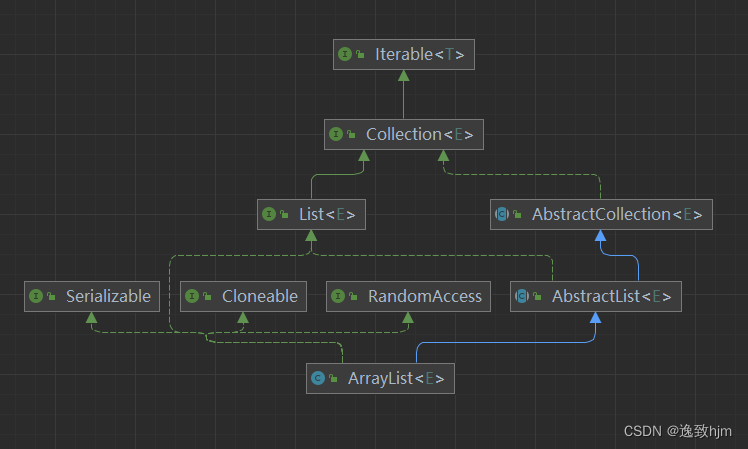
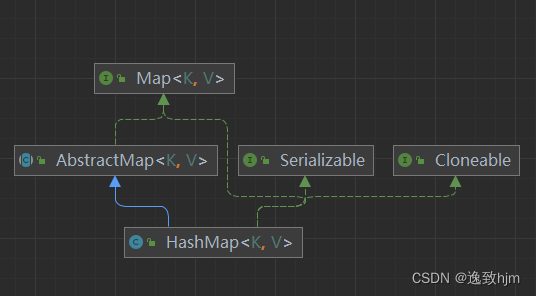
而HashMap现了Map接口(Map(接口)->HashMap(类)),底层使用的是Hash算法存储数据。
2)存储元素
ArrayList以数组的方式存储数据,里面的元素是根据放进去的顺序存储,可以重复的;而HashMap将数据以键值对(key:value)的方式存储,key的哈希码(hashCode)不可以相同,key相同后面的value会将前面的value覆盖,value可以重复,里面的元素无序。
3)添加元素的方法
ArrayList用add(Object object)方法添加元素,而HashMap用put(Object key, Object value)添加元素。
4)默认的大小和扩容
在 Java 7 中,ArrayList的默认大小是 10 个元素,HashMap 的默认大小是16个元素(必须是2的幂)。
// ArrayList源码
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;// HashMap源码
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16ArrayList扩容增量:原容量的0.5倍+1,如 ArrayList的容量为10,容量满时会触发扩容,一次扩容后是容量为16;
HashMap扩容增量:原容量的 1 倍,加载因子为0.75:即当元素个数超过原容量长度的0.75倍时,进行扩容,如 HashSet的容量为16,在里面数据容量到达12(16*0.75)时,后面再添加数据,会进行扩容操作,一次扩容后是容量为32
5)时间复杂度
ArrayList查找的时间复杂度是O(1),因为HashMap是根据hashcode直接获取数据,在哈希冲突少的情况下,时间复杂度是O(1)。如果桶里面没有元素,那么直接将元素插入/或者直接返回未查找到,时间复杂度就是O(1),如果里面有元素,那么就沿着链表进行遍历,时间复杂度就是O(n),链表越短时间复杂度越低,如果是红黑树(JDK1.8后新增,在哈希冲突超过8,且容量超过64的时候会从链表变成红黑树)的话那就是O(logn)。
使用场景:
如果需要储存多个单度元素不需要键值对形式,应该使用ArrayList。需要键值对形式的数据时,应该使用HashMap。
补充内容:
加载因子是表示Hash表中元素的填满的程度。若加载因子越大,填满的元素越多,好处是空间利用率高了,但冲突的机会加大了;反之,加载因子越小,填满的元素越少,好处是冲突的机会减小了,但空间浪费多了。冲突的机会越大,则查找的成本越高,反之,查找的成本越小。因而,查找时间就越小。因此,必须在 "冲突的机会"与"空间利用率"之间寻找一种平衡与折衷。 这种平衡与折衷本质上是数据结构中有名的"时-空"矛盾的平衡与折衷。当元素个数超过 容量长度*加载因子的系数 时,会进行扩容。
如果有写得不对的,望大神多多指教,让小弟修正,感谢!

















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









