








 Apache HBase是一个运行在Hadoop上的分布式数据库,它放弃了ACID特性以实现更好的可扩展性。与关系型数据库相比,HBase更适合存储结构不严格的数据。本文将对比HBase和关系型数据库,探讨其设计理念,包括数据模型和分布式存储特性。
Apache HBase是一个运行在Hadoop上的分布式数据库,它放弃了ACID特性以实现更好的可扩展性。与关系型数据库相比,HBase更适合存储结构不严格的数据。本文将对比HBase和关系型数据库,探讨其设计理念,包括数据模型和分布式存储特性。
什么是HBase
Apache HBase是运行在Hadoop集群上的数据库。为了实现更好的可扩展性(scalability),HBase放松了对ACID(数据库的原子性,一致性,隔离性和持久性)的要求。因此HBase并不是一个传统的关系型数据库。另外,与关系型数据库不同的是,存储在HBase中的数据也不需要遵守某种严格的集合格式,这使得HBase是用来存储结构不严格的数据的理想工具。
HBase在大数据应用的架构中应用非常广泛。但是基于其与关系型数据库迥异的设计模式,实现这些应用也与基于关系型数据库来实现非常不同。下文将会对比HBase和关系型数据库,并浅析HBase的特性。
关系型数据库与HBase的对比
首先我们要明白在已经存在关系型数据库的情况下,为什么产生了所谓的NoSQL/HBase这样的费关系型数据库?要解答这个问题,我们需要先了解一下关系型数据库的优势和缺点。
- 关系型数据库提供了标准的数据持久性模型
- SQL语言是事实上的数据操作标准语言
- 关系型数据库内置了并发数据操作的管理机制
- 关系型数据库提供全面的数据操作工具
关系型数据库是长期以来数据存储的标准工具,那么我们为什么还在寻找新的数据存储方法呢?原因是现在需要存储的数据越来越多,工业界对数据存储工具可伸展性的要求也越来越高。一种简单直接的扩展方法是垂直扩展,也就是采用更大更高效的服务器来存储。但是这种方法成本很高,且可扩展性存在一个上限(单台服务器的性能是有限的)。
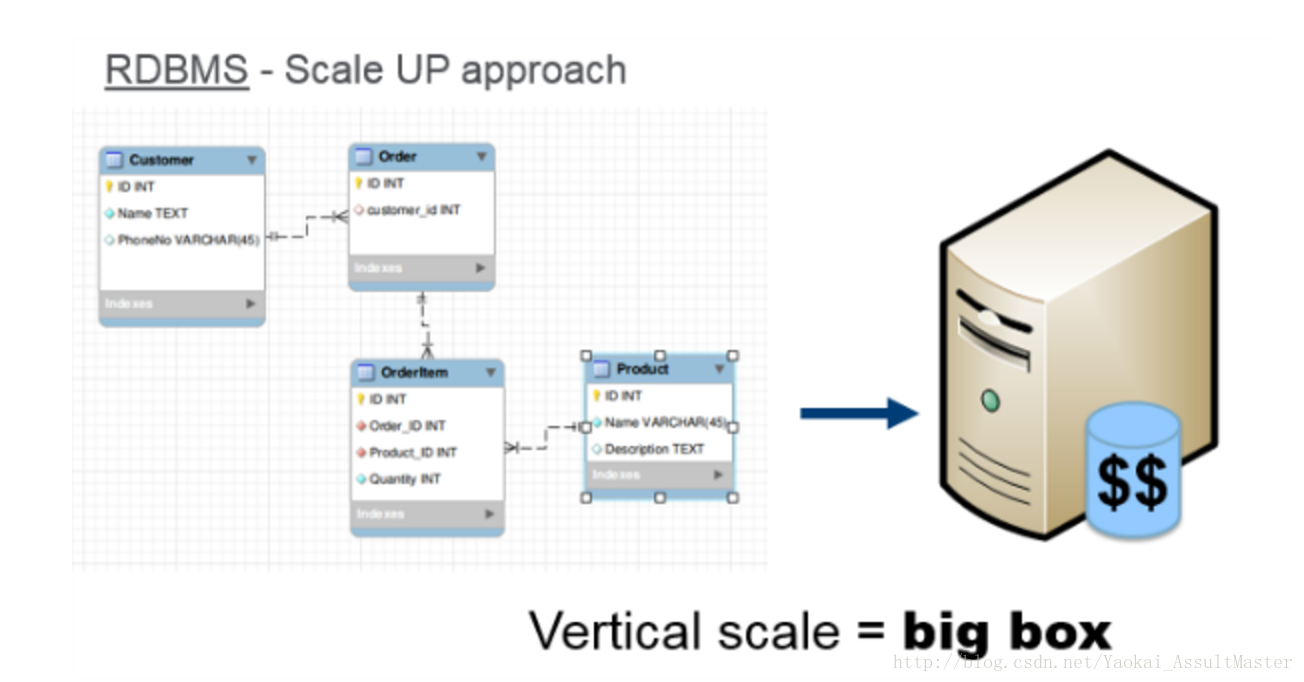
关系型数据库的局限性
除垂直扩展之外,我们也可以采用水平扩展的方法。也就是用服务器集群来满足要求。用来集群的服务器可以是性能普通的服务器。这样就可以大大降低运营成本。如果我们要采用水平扩展的方法来扩展关系型数据库,关系型数据库中的数据势必要根据row key分布存储,也就意味着某些row key对应的行存储在某一台服务器上,另一些row key对应的行存储在另一台服务器上。然而,要分割一个关系型数据库是非常复杂的,并且关系型数据库不具备自动分布式存储的功能。不仅如此,分布存储关系型数据库,我们将失去总体上的数据库查询功能及事务(transaction)的一致性。总而言之,关系型数据库是为在单台服务器上运行而设计的。
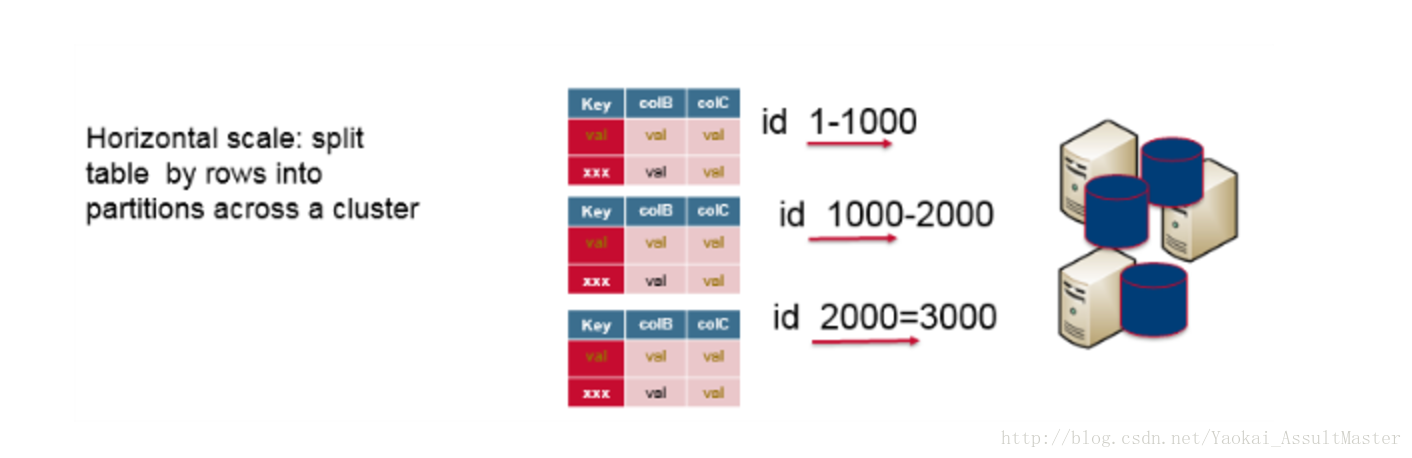
除此之外,关系型数据库中数据库规范化(database normalization)的理念消除了数据的重复存储,使得数据存储更高效。在查询时为了将数据重新组织起来,就需要需要Join操作。这也进一步使得关系型数据库的分布式存储更为困难。
HBase的高效,分布式,可扩展性的设计理念
由于HBase在设计上不支持关系和Join这样的概念,需要一起查询的数据就被存在一起。因此也就避免了关系型数据库的一些局限性。下图表现了HBase和关系型数据库在数据存储模型上的不同。
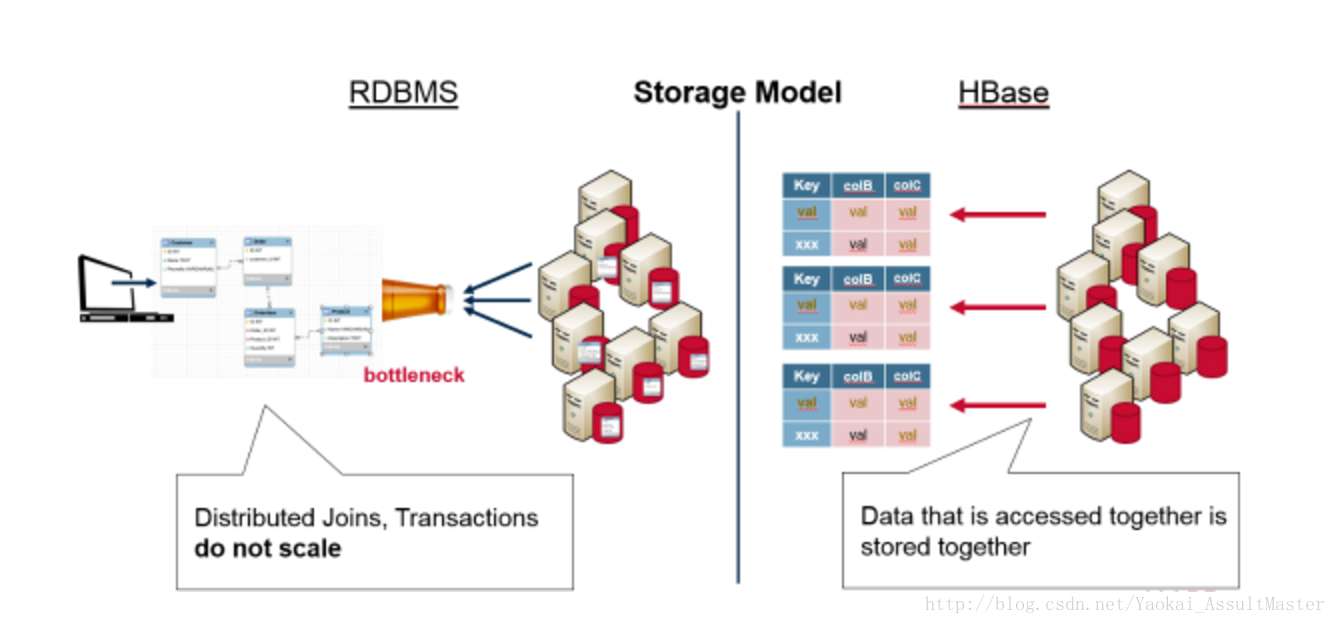
由于HBase将所有需要一起查询到数据存储在一起这一特性,HBase集群就自然能够根据key来组织数据。在水平分割的时候,key值的范围就可以被用来分割数据。每一个服务器存储全部数据的一个子集。同时分布式的数据还可以被同时访问。这大大增强了HBase的可扩展性。HBase实际上是Google Big Table的一个实现。Big Table是Google提出的一个用来存储大规模数据的一个分布式系统。
HBase是基于Column family data store的理念设计的:每一行根据一个row key索引。也就是我们用来查询的主键。同时每一行中有若干column family。每一个column family中有若干相关的column。如下图所示。
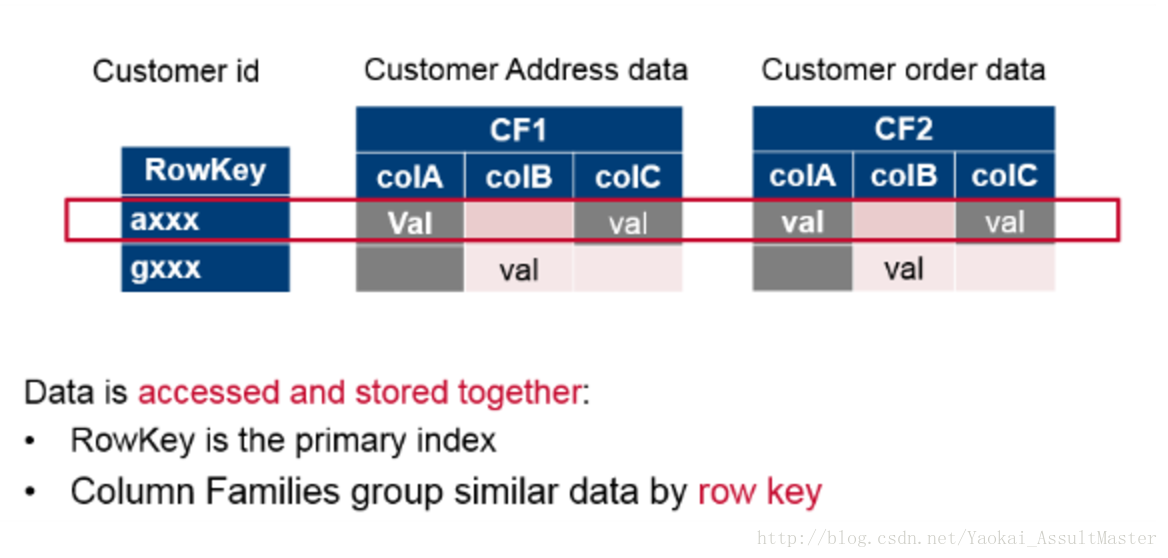
HBase中的row key也是HBase分布式存储数据的主要根据。在分布存储数据的时候,根据row key值的范围,每一台服务器存储全部数据的一个子集。HBase提供基于行的原子性操作保证。也就是每一个row key对应的行为一个原子操作的单元。
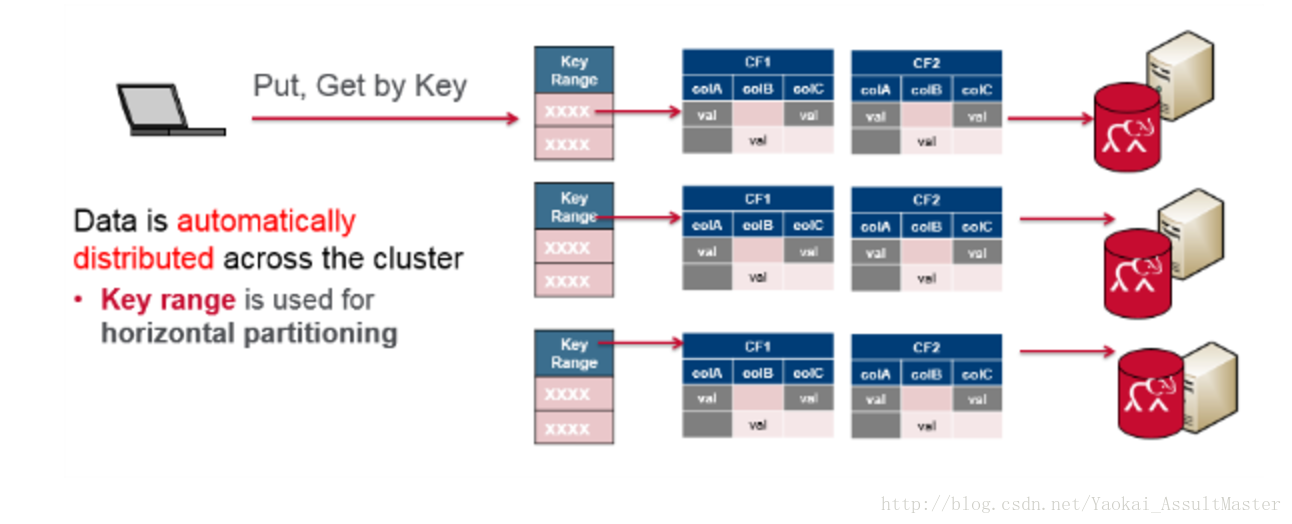
HBase的数据模型
HBase中的数据根据row key分布。row key类似于关系型数据库中的主键(primary key)。HBase中的数据记录根据row key的值排序。这是HBase数据存储的一个重要原则,也是HBase设计架构的一个重要部分。
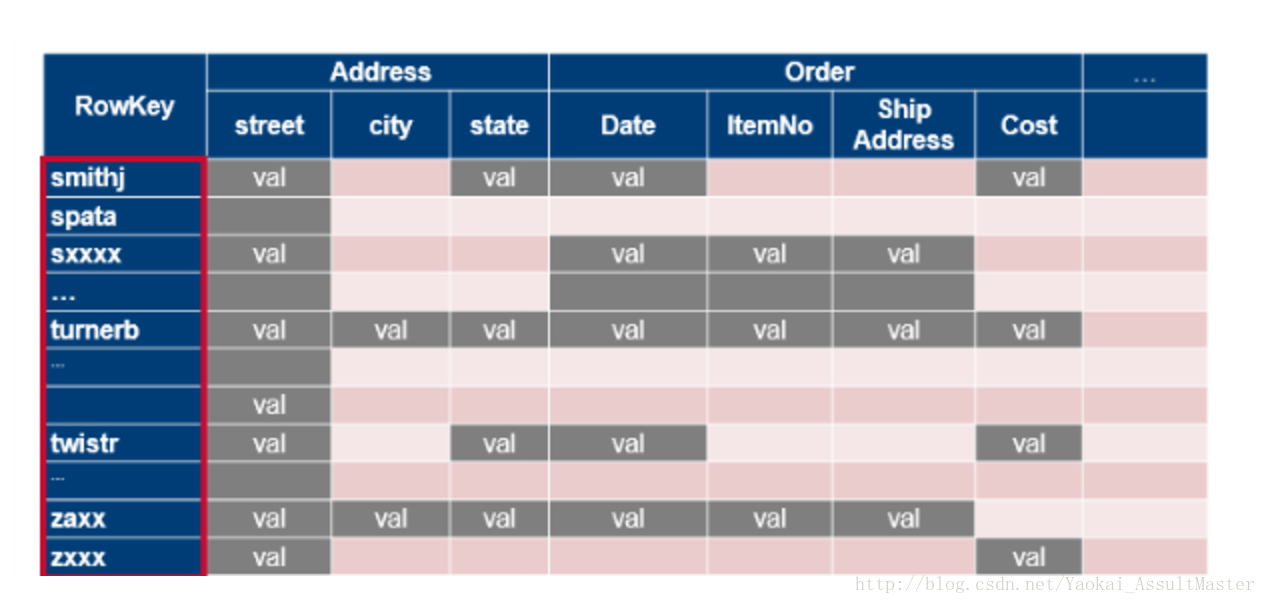
HBase中数据表根据row key的值分割为不同的区域,每个区域包含一部分连续的行。这些区域被分配给集群中不同的称为区域服务器的数据结点。可扩展性就是通过将区域分配给集群中的不同服务器实现的。这一操作是自动进行的。也就是HBase如何根据水平扩展设计的。
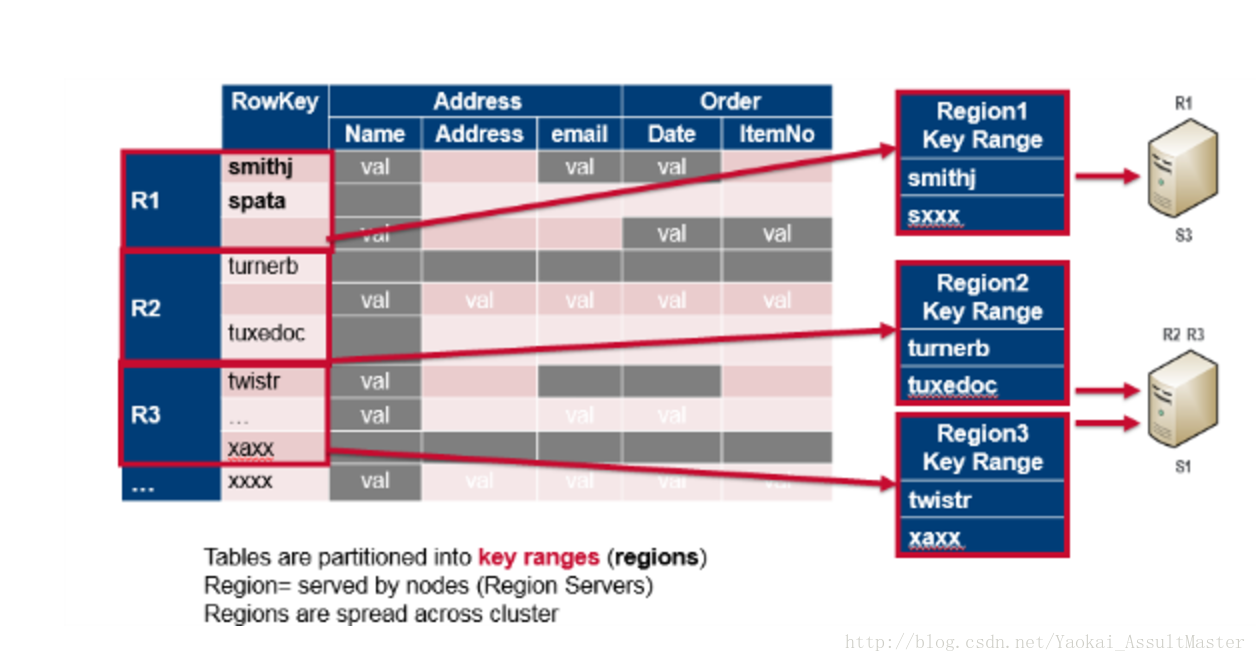
下图表示了column family是如何映射到存储文件的。不同的Column family被存储在不同的文件中。这些文件可以被分别访问。
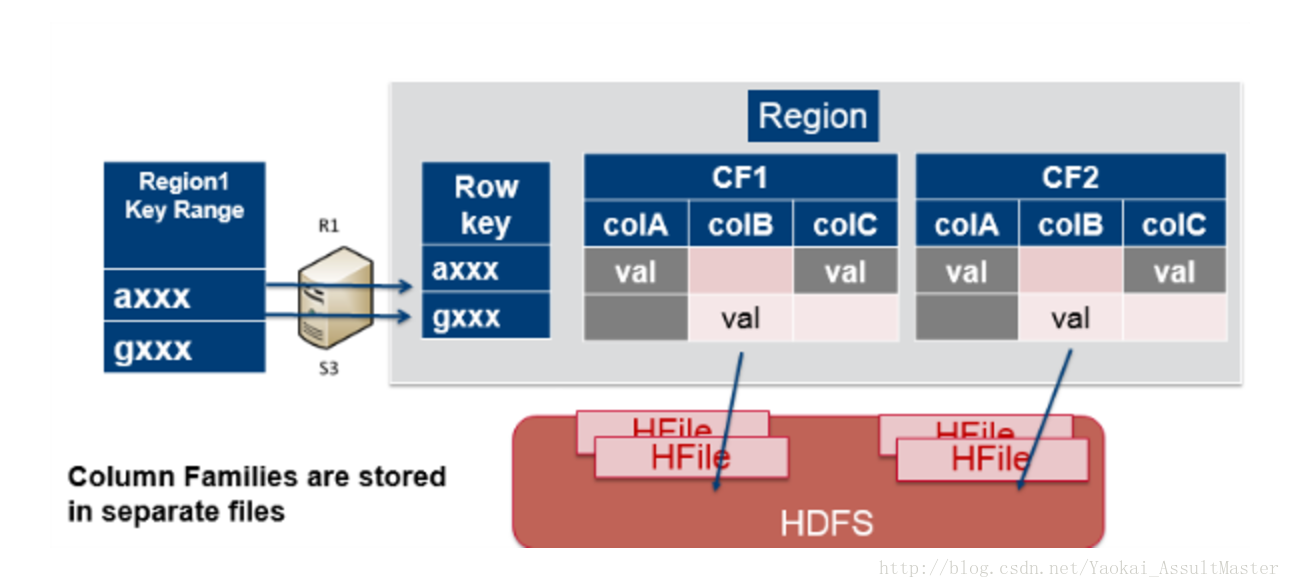
数据存储在HBase表格的cell中。cell中包含key和value以及一些其他的信息(如version, type等)。其中key部分包括row key,column family,column qualifier, timestamp。并且对于每一个值,key部分都会与其一同被存储。如下图所示。
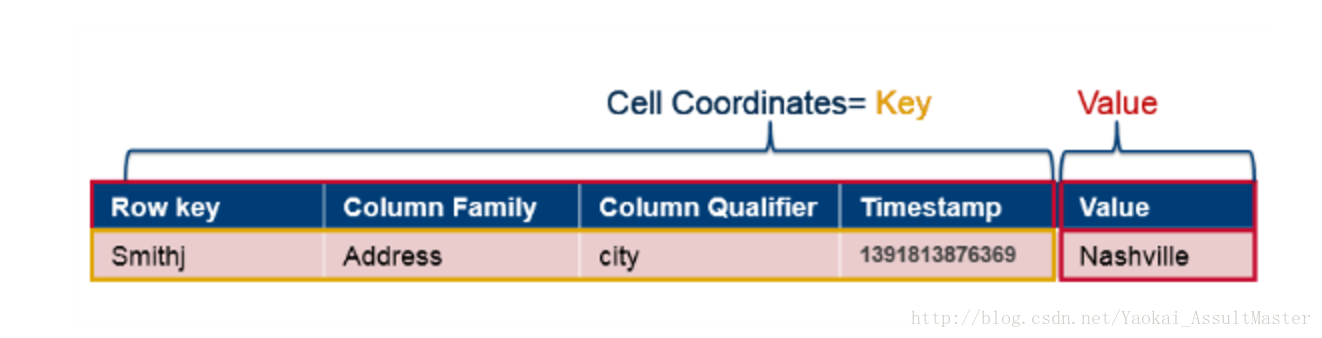
从逻辑上来看,row似乎是以表格的形式存储的。但事实上,row是以一些cell的集合的形式存储的。其所对应的每一个cell都存储了其所对应的上述所有key信息。
下图中上半部分是HBase的数据的逻辑布局,下半部分是文件的物理布局。Column family被分别存储于不同的文件中。我们每设置一个值,其对应的cell就会存储所有的key信息(row key, column family, column qualifier, timestamp)。
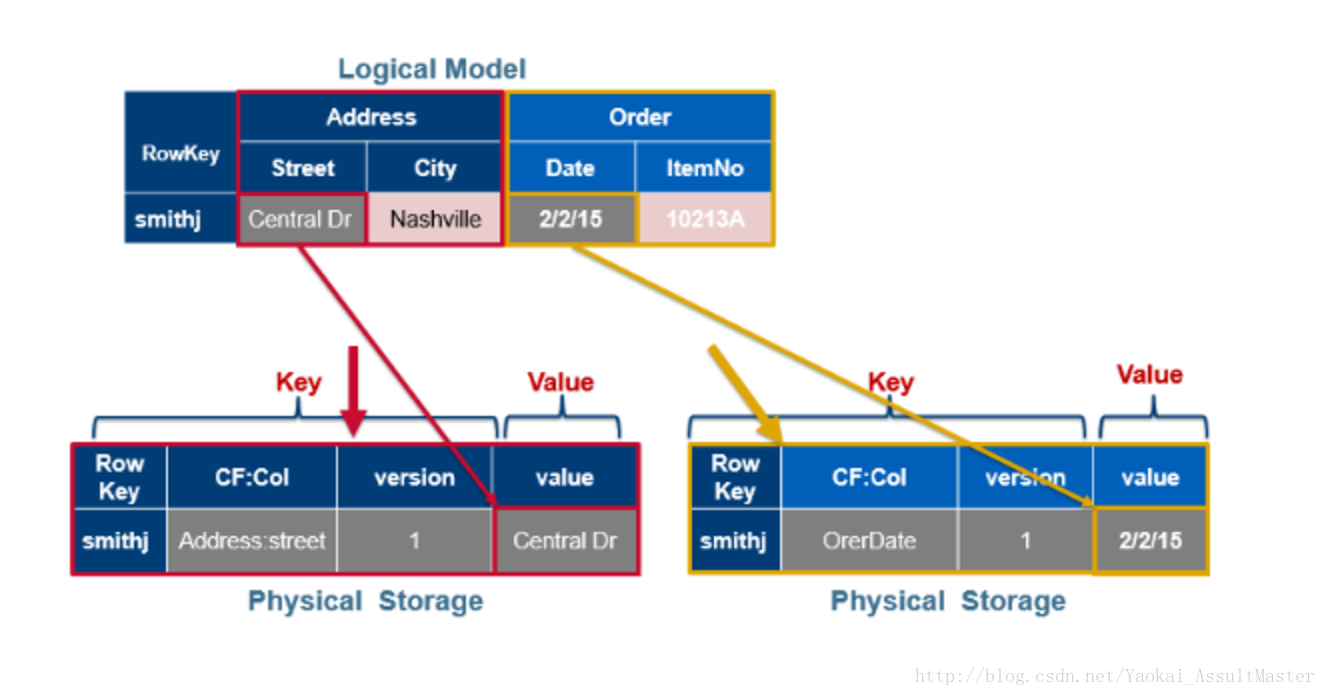
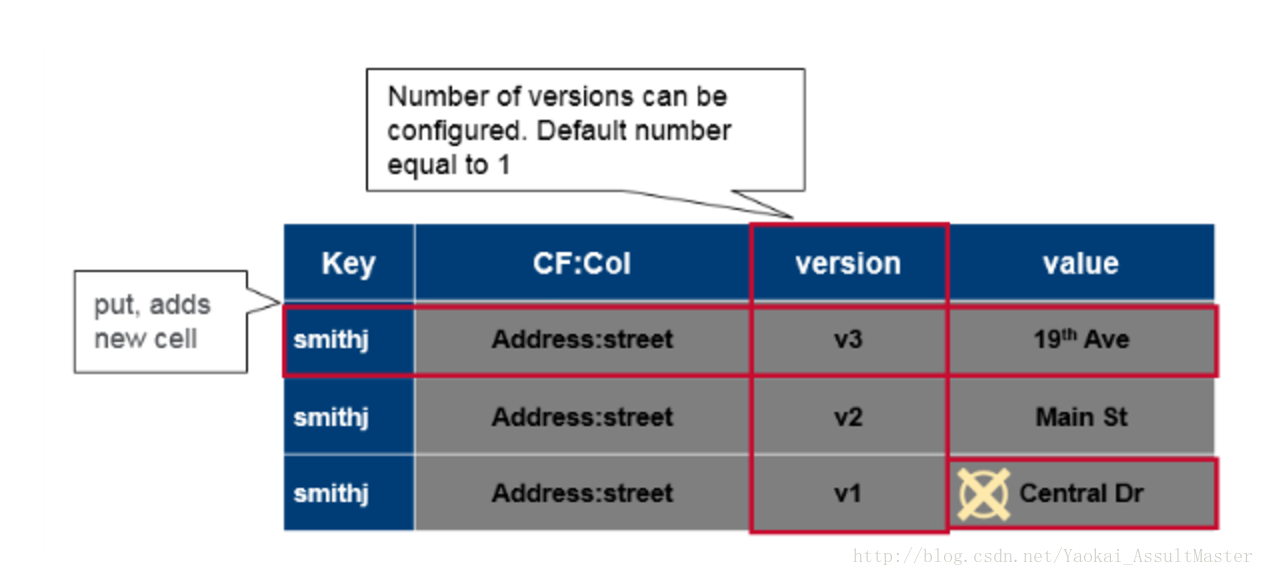
综上所述,对于HBase中每一个cell的值,其完整的索引应当是Table::Row::Column family::Column::Timestamp –> Value。Hbase的表是稀疏的。如果某一列没有数据,则其不会被存储。表中的cell有其对应的连续改变的version。version默认参考timestamp,但我们也可以自己定制。对于每一个Table::Row::Column family::Column –> Value,数据库中可能存储了多个不同version的值。
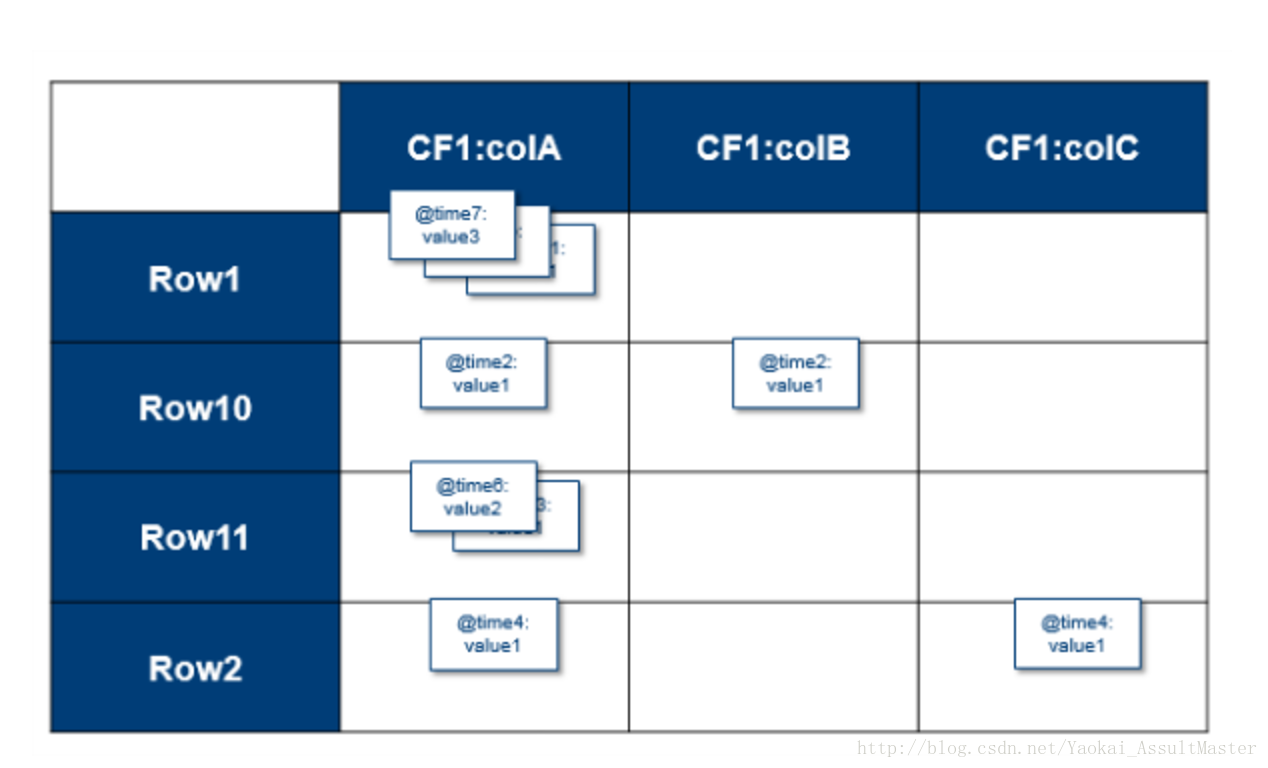
Version系统是HBase自动采用的。从CRUD的角度来说,一个put操作既是插入(insert/create),也是更新(Update)操作,每一个数据都会带有其相应的version。Delete操作并不会立即在物理上删除数据,而是会给数据加一个删除标签。这个标签会保证数据不会在查询时被返回。Get操作根据给定的参数返回特定version的数据。默认情况下最新版本的数据将会被返回。保存在HBase中的同一个数据的不同version的数量也可以配置。这个数量是针对同一个column family而言的。默认情况下,HBase会保存3个不同version的数据。当数据不同的version数目超过这个数字时,最早version的数据将会被删除。
原文链接:HBase and MapR-DB: Designed for Distribution, Scale, and Speed
All rights reserved to the original author of the article















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









