







上一步通过GIZA++进行词语对齐,我们得到了对应的中英文词对,在此基础上我们就可以进行第三个重要过程了,即抽取短语。短语抽取是短语翻译表构造的第一步,而短语翻译表是翻译系统解码器的要使用到的最重要组件之一,所以抽取短语这一步意义非常大。
示例:
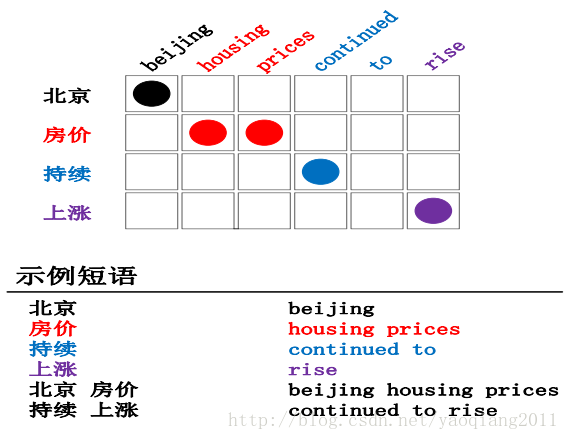
上图展示了从含有词对齐信息的双语平行句对(上方图所示)中抽取的短语对(中下方的“示例短语”所示)。从图中可以看出,理想情况下我们从平行对齐句对中,抽取出的是与词对齐保持一致的短语对。
在介绍抽取短语算法之前,先介绍一个重要的概念:一致性短语

对比前面举例的图片,可以看到其示例短语对和词对齐是保持一致的。
下面介绍一下抽取短语算法:
这里涉及到两个算法,算法1和算法2,其中算法1有一步调用算法2处理的结果。
算法1:
算法1的核心思想是:长度从1到I遍历目标语端词串并且在源语端找到与之匹配的最小词串。如果目标语端词串中所有词汇在词对齐中对应的项都在与之匹配的源语词串范围内,并且源语端词串中所有词汇在词对齐中所对应的项都在目标语词串范围内时,同时源语、目标语词串不能只包含对空词汇,此时找到的源语端、目标语端词串便与词对齐保持一致,称双语端词串对为短语对。
其过程如下图所示:

详细说来:
1)算法第1行与第2行在目标语端进行二重循环,目的是遍历目标语端所有可能出现的短语;算法第2行设臵当前目标语端词串的起始位置。
2)算法第3行设臵当前目标语端词串的结束位置。
3)算法第4行设置当前源语端词串的起始位置与结束位置。起始位置设置为源语句子长度的最大值,结束位置设置为0。该设置可快速判断是否可找到与词对齐保持一致的短语。
4)算法第5-10行确保目标语端词串中的所有词汇在词对齐中对应的词汇在源语端词串范围内。
5)算法第11行使用算法2的extract(j1, j2, i1, i2)函数对找到的可能短语对进行验证和扩展,确保找到短语对与词对齐保持一致。
算法2:
算法2的extract函数是算法1中第11行使用的对找到的短语进行验证和扩展的函数。在与词对齐保持一致的短语对的扩展过程中,主要是短语对中源语端与目标语端边缘对空词汇的扩展。根据一致性的定义,边缘对空词汇不会影响短语一致性的性质,同时,抽取更多边缘对空扩展对空短语可获得更多上下文信息、可适当缓解词对齐不精确带来的问题。
算法2的过程如下所示:

详细说来:
1)算法第1-3行保证找到的源语端词串中至少有一个词汇在词对齐中对应的项在目标语词串内。
2)算法第4-8行确保源语端词串中的所有词汇在词对齐中对应的词汇在目标语端词串范围内,即找到与词对齐一致的短语对。
3)算法第9行初始化短语对集合为空。
4)算法第10-18行扩展与词对齐保持一致的短语对,如果找到的短语对的源语端或目标语端的边界词汇对空,则扩展该短语对,将新短语对加入到短语对集合E中。
5)算法第19行返回短语对集合E。
下图为抽取短语流程实例图,其中蓝色点为异常点:

上图展示应用短语抽取算法1、2抽取短语对的基本流程。其中“从目标语长度n开始循环”为算法1的第1行;每组三个图如“(a),(b)和(c)”为算法1中第2行至第12行。图(2)中(a)图展示抽取的一个与词对齐保持一致的短语对“北京,beijing”;(b)图展示一个非法的短语对“房价,housing”,其中目标语端词汇“prices”为异常点。
根据上文“一致性”定义及“算法1、2”从示例含有词对齐信息的双语平行句对中抽取的所有与词对齐保持一致的短语对如下图所示:


















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









