









栈
比如我们在放盘子的时候都是从下往上一个个放,拿的时候是从上往下一个个的那,不能从中间抽,这种其实就是一个典型的栈型数据结构。后进先出即Last In First Out (LIFO)。
栈如何实现
- 它是一个限定仅在表尾进行插入和删除操作的线性表。
这一端被称为栈顶,相对地,把另一端称为栈底。 - 向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;
- 从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
- 因为是线性表、所以可以使用数组或者链表实现,所以栈是特殊的链表和数组;
- 既然栈也是一个线性表,那么我们肯定会想到数组和链表,而且栈还有这么多限制,那为什么我们还要使用这个数据结构呢?不如直接使用数组和链表来的更直接么?数组和链表暴露太多的接口,实现上更灵活了,有些技术理解不到位的人员就可能出错。所以在某些特定场景下最好是选择栈这个数据结构。
栈的分类
-
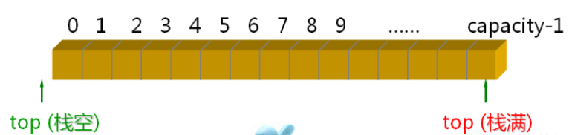
基于数组的栈——以数组为底层数据结构时,通常以数组头为栈底,数组头到数组尾为栈顶的生长方向
-
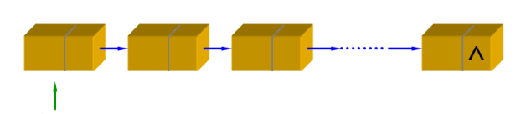
基于单链表的栈——以链表为底层的数据结构时,以链表头为栈顶,便于节点的插入与删除,压栈产生的新节点将一直出现在链表的头部
两者的区别在于数组和链表的本质区别,链表可以动态扩容,而数组则是固定容量,有栈溢出的可能;
栈的基本操作
基于数组实现的栈:
package com.DataConstruct.stack;
public class MyStack {
private Object[] table;
private int top;
private int defaultCapacity=10;
private int capacity;
public MyStack() {
table=new Object[defaultCapacity];
capacity=defaultCapacity;
top=0;
}
public MyStack(int capacity) {
this.capacity = capacity;
table=new Object[capacity];
top=0;
}
public void push(Object val){
if(val==null)return;
if(top+1<capacity){
table[top]=val;
top++;
}else {
//扩容操作...数组扩容为原来的1.5呗。
}
}
public Object pop(){
if (top<0)return -1;
return table[top--];
}
public Object peek(){
if (top<0)return -1;
return table[top];
}
public int size(){
return top;
}
public void print(){
for (int i=0;i<top;i++){
System.out.println(table[i].toString());
}
}
public static void main(String[] args) {
MyStack stack=new MyStack();
stack.push("1");
stack.push("2");
stack.push("3");
stack.push("4");
stack.print();
stack.pop();
stack.print();
System.out.println("-----");
stack.push("ss");
stack.push("dd");
stack.push("aa");
stack.print();
}
}
JDK自带的数组栈ArrayStack继承了ArrayList,底层就是数组;
package org.yaml.snakeyaml.util;
import java.util.ArrayList;
public class ArrayStack<T> {
private ArrayList<T> stack;
public ArrayStack(int initSize) {
stack = new ArrayList<T>(initSize);
}
public void push(T obj) {
stack.add(obj);
}
public T pop() {
return stack.remove(stack.size() - 1);
}
public boolean isEmpty() {
return stack.isEmpty();
}
public void clear() {
stack.clear();
}
}
基于链表实现栈:
package com.DataConstruct.stack;
import com.DataConstruct.list.MyStack;
public class MyLinkedStack implements MyStack {
private Node head;
private Node tailParent;
private Node tail;
private int top;
public MyLinkedStack() {
top=0;
}
@Override
public void push(Object val) {
Node newNode=new Node(val);
if(head==null){
head=newNode;
tail=newNode;
top++;
}else {
tailParent=tail;
tail.next=newNode;
newNode.pre=tail;
tail=newNode;
top++;
}
}
@Override
public Object pop() {
Node result=tail;
//将尾结点和尾结点前一个结点的指针断掉;避免内存泄露
tailParent.next=null;
tail.pre=null;
//将尾结点和尾结点前一个结点往前面移动一个位置;;
tail=tailParent;
tailParent=tailParent.pre;
//元素个数-1;
top--;
//如果元素个数为0,需要把head与下一个结点的指针断掉。
if(top==0){
head=null;
}
return result.data;
}
@Override
public Object peek() {
if(tail!=null){
return tail.data;
}
return -1;
}
@Override
public int size() {
return top;
}
public void print(){
Node cur=head;
while (cur!=null){
System.out.println(cur.data);
cur=cur.next;
}
}
public static void main(String[] args) {
MyLinkedStack stack=new MyLinkedStack();
stack.push("11");
stack.push("12");
stack.push("13");
stack.push("14");
stack.print();
System.out.println(stack.pop());
System.out.println(stack.pop());
stack.print();
System.out.println(stack.peek());
}
}
class Node {
int index;
Object data;
Node next;
Node pre;
public Node(Object data) {
this.data = data;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
}
通过数组和链表的实现方式,我们也可以还知道栈入栈和出栈的时间复杂度是O(1),效率较好。
栈的应用场景
我们JVM虚拟机的内存结构中,有一部分为虚拟机栈;是每个线程私有的,因为出栈和入栈,所有的基本数据类型和栈上分配变量都会被回收,减少JVM垃圾回收的压力。















 33万+
33万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









