







算法复杂度——dsa第一章
Hailstone序列的定义如下:
- 从任意一个正整数n开始。
- 如果n是偶数,那么下一个数是n除以2(即n/2)。
- 如果n是奇数,那么下一个数是n乘以3然后加1(即3n+1)。
- 重复这个过程,直到序列中的数达到1。
理想硬币
1. rand() 是一个理想的随机整数生成器,生成奇数和偶数的 概率都是50%。
2. 考虑以下算法程序:
void dice() {
while ( rand() & 1 );
}
这个程序中的循环会一直执行,直到 rand() 生成一个奇数。因为奇数的二进制表示的最低位是1,所以 rand() & 1 会一直为0(即偶数)直到生成一个奇数。
3. 循环的迭代次数是一个随机变量,记为 s。
4. 循环迭代 k 步的概率 𝑃𝑟(𝑠=𝑘)是前 𝑘−1 次生成偶数,第 𝑘 次生成奇数的概率,即:
𝑃𝑟(𝑠=𝑘)=(12)𝑘−1⋅(1−12)=2−𝑘
5. 循环迭代次数的期望值 𝐸(𝑠)E(s) 是:
𝐸(𝑠)=∑𝑘=1∞𝑘⋅2−𝑘=11−12=2
这意味着平均来说,循环会迭代2次。
6. 尽管在理论上,循环可能迭代任意多次,但期望值是有限的,为2。
图灵机(TM)模型
1. Tape(带子):图灵机的带子被均匀地划分为单元格,每个单元格存储一个字符,初始时通常为’#'。
2. Head(读写头):图灵机的读写头总是对准带子上的某个单元格,可以读取或改写该单元格中的字符。每经过一个时间单位,读写头可以向左或向右移动到相邻的单元格。
3. Alphabet(字母表):图灵机的字母表定义了带子上可能出现的字符种类,这些字符是有限的。
4. State(状态):图灵机在执行过程中会处于有限种状态中的一种。每经过一个时间单位,根据当前状态和读写头读取的字符,图灵机可以按照转换函数的规则转向另一种状态。
5. Transition Function(转换函数):转换函数定义了图灵机在给定当前状态和字符时,如何进行状态转换、字符改写以及读写头的移动。
6. Halt State(停机状态):一旦图灵机转入特定的停机状态(通常用’h’表示),它将停止运行。
7. Cost Measurement(成本度量):图灵机从启动到停机所经历的时间单位数目可以用来度量计算的成本,这通常等于读写头累计的移动次数。
举例:increase
这个实例展示了如何设计一个图灵机来实现二进制非负整数加一的功能。具体步骤如下:
- 将带子上表示二进制数的全’1’后缀翻转为全’0’。
- 将原最低位的’0’或’#‘翻转为’1’。
(<, 1; 0, L, <):当图灵机的读写头向左移动(<)并且读取到字符1时,它将执行以下操作:
- 将1替换为0(1; 0),
- 然后继续向左移动(L),
- 并且保持在当前状态(<)。
(<, 0; 1, R, >):当图灵机的读写头向左移动并且读取到字符0时,它将执行以下操作:
- 将0替换为1(0; 1),
- 然后向右移动(R),
- 并且转换到新的状态(>)。
(<, #; 1, R, >):当图灵机的读写头向左移动并且读取到空白符号#时,它将执行以下操作:
- 将#替换为1(#; 1),
- 然后向右移动(R),
- 并且转换到新的状态(>)。
- 这里的注释“可否省略?”可能是指在某些情况下,这个转换规则可能不是必需的,因为图灵机可能在完成加一操作后不会遇到#字符。
(>, 0; 0, R, >):当图灵机的读写头向右移动并且读取到字符0时,它将执行以下操作:
- 保持0不变(0; 0),
- 然后继续向右移动(R),
- 并且保持在当前状态(>)。
(>, #; #, L, h/<):当图灵机的读写头向右移动并且读取到空白符号#时,它将执行以下操作:
- 保持#不变(#; #),
- 然后向左移动(L),
- 并且转换到停机状态(h)或者回到初始状态(<),这取决于图灵机的设计。
随机访问机(Random Access Machine,RAM)模型
这是计算机科学中用于分析算法效率的一个理论模型。RAM模型抽象了实际计算机的主要特征,以便于研究算法的时间复杂度。以下是RAM模型的一些关键特点:
1. 寄存器(Registers):RAM模型中有一系列顺序编号的寄存器(R[0], R[1], R[2], R[3], …),寄存器的数量没有限制,可以通过编号直接访问任意寄存器。
2. 指令寄存器(Instruction Register, IR):IR寄存器用于指示当前正在执行哪条指令。
3. 基本操作:在RAM模型中,每一基本操作都假设可以在常数时间内完成。这些操作包括:
- 赋值操作:R[i] <- c,将常数c赋值给寄存器R[i]。
- 寄存器间赋值:R[i] <- R[j],将寄存器R[j]的值赋给寄存器R[i]。
- 间接访问:R[i] <- R[R[j]],通过寄存器R[j]的值作为索引来访问寄存器,并将其值赋给R[i]。
- 算术操作:R[i] <- R[j] + R[k],将寄存器R[j]和R[k]的值相加,结果赋给R[i];以及 R[i] <- R[j] - R[k],将寄存器R[j]和R[k]的值相减,结果赋给R[i]。
4. 条件跳转:IF R[i] = 0 GOTO #,如果寄存器R[i]的值为0,则跳转到标签#处执行指令;IF R[i] > 0 GOTO #,如果寄存器R[i]的值大于0,则跳转到标签#处执行指令。
5. 无条件跳转:GOTO #,无条件跳转到标签#处执行指令。
6. 停止指令:STOP,结束程序执行。
7. 语言特性:RAM模型支持直接通过寄存器编号访问寄存器(call-by-rank),并且所有基本操作都假设在常数时间内完成。
算法的运行时间(T(n))与算法需要执行的基本操作次数成正比。
T(n)表示解决规模为n的问题所需的基本操作次数。
TM和RAM等模型中衡量算法效率时,空间复杂度的影响较小
举例:天花板除法(Ceiling Division)
- 天花板除法的定义:对于任意正整数 𝑐 和正整数 𝑑,天花板除法 ⌈𝑐/𝑑⌉ 定义为满足 𝑐≤𝑑⋅𝑥 的最小整数 𝑥,或者等价地,满足 𝑐−1<𝑑⋅𝑥的最小整数 𝑥。
- 算法思路:在RAM模型中实现天花板除法的算法思路是反复从寄存器R[0]中存储的被除数 𝑐中减去除数 𝑑(存储在R[1]),直到结果小于除数 𝑑。在这个过程中,统计减法操作的次数 𝑥,这个次数就是天花板除法的结果。
- 算法步骤:算法的步骤可能包括初始化寄存器、执行减法操作、更新计数器、检查终止条件等。
- 时间复杂度:天花板除法的时间复杂度与减法操作的次数 𝑥成正比,即与 ⌈𝑐/𝑑⌉ 成正比。
算法步骤:
- R[3] <- 1:将常数1赋值给R[3],用于计数。
- GOTO 4:如果R[0](被除数c)为0,则跳转到步骤4。
- R[2] <- R[2] + R[3]:将R[3]的值加到R[2]上,用于统计减法的次数x。
- R[0] <- R[0] - R[1]:从R[0]中减去R[1](除数d)。
- IF R[0] > 0 GOTO 2:如果R[0]大于0,跳转回步骤2继续执行。
- R[0] <- R[2]:将R[2]的值(即x)赋给R[0]。
- STOP:结束程序,R[0]现在存储的是天花板除法的结果。
算法的时间成本是各条指令执行次数的总和
符号
大O符号(Big-O notation)
T(n) =O(f(n)):大O符号允许我们忽略低阶项和常数因子,只关注最高阶项。
例如,𝑂(𝑛2+𝑛) 可以简化为 O(n2),因为 n2 的增长速度比 𝑛快。
大Ω符号(Big-Omega Notation):
- 定义:如果存在一个正常数 𝑐 和一个 n0,使得对于所有 𝑛≥𝑛0,都有 𝑇(𝑛)≥𝑐⋅𝑓(𝑛),则称 𝑇(𝑛) 是 Ω(𝑓(𝑛))。
- 意义:大Ω符号描述了算法时间复杂度的下界。它表明算法的运行时间至少与 𝑓(𝑛)成正比。
大Θ符号(Big-Theta Notation):
- 定义:如果存在正常数 𝑐1,𝑐2 和一个 n0,使得对于所有n≥n0,都有 𝑐1⋅𝑓(𝑛)≤𝑇(𝑛)≤𝑐2⋅𝑓(𝑛),则称 𝑇(𝑛) 是 Θ(𝑓(𝑛))。
- 意义:大Θ符号描述了算法时间复杂度的精确界。它表明算法的运行时间与 𝑓(𝑛)相差不大,既不会少于 𝑐1⋅𝑓(𝑛),也不会多于 c2⋅f(n)。
时间复杂度
O(1):constant 常数时间复杂度
这里的“O”是大O符号,用于描述算法性能的上界,即算法运行时间或空间需求的增长率的上界。
- 可能含循环
for (i = 0; i < n; i += n/2024 + 1);
这个循环的迭代次数是常数,因此它的时间复杂度是O(1)
for (i = 1; i < n; i = 1 << i);这个循环的迭代次数是对数级别的,即log(n),但因为每次迭代的步长是指数增长的,所以总的迭代次数实际上是常数,时间复杂度也是O(1)。
在C语言中,<<是左移位运算符,它将数字1的二进制表示向左移动i位。例如,如果i是2,那么1 << 2等于4。
- 可能含分支转向
if ((n + m) * (n + m) < 4 * n * m)
goto UNREACHABLE;这个条件判断不会导致循环,也不会导致递归调用,因此它的时间复杂度是O(1)。 - 可能含有递归调用
if (2 == (n * n) % 5) O1op(n);这里的O1op(n)是一个假设的操作,如果它的时间复杂度是O(1),那么整个条件语句的时间复杂度也是O(1)。
代码段是否具有常数时间复杂度需要具体分析,不能仅仅根据是否包含循环、分支转向或递归调用来判断。关键在于代码的执行次数是否与输入规模无关。
对数(poly-log)时间复杂度
对数时间复杂度(O(log n)):
- 表示算法的运行时间与输入规模的对数成正比。这种复杂度的算法非常有效,因为它们增长得非常慢。
- 对数的底数:
- 在讨论对数时间复杂度时,通常不特别注明底数。这是因为对数的换底公式允许我们转换对数的底数,而不改变其渐近行为。例如, log100n 和log2024n 都可以转换为以2或e为底的对数,它们是等价的Θ(logn))。
- 常底数和常数次幂的对数:
- 对于任何大于1的底数a和b, logan 可以转换为logbn 的常数倍,即 Θ(logbn)。
- 对于任何正常数c, lognc 等于 c⋅logn,这也是Θ(logn)。
- 对数多项式:
- 对数多项式是指对数的高次幂,即使对数被提升到很高的次幂,整个表达式仍然可以被Θ(logxn) 所界定。
- 对数与多项式的关系:
- 对数时间复杂度的算法非常有效,因为对数函数的增长速度远慢于任何多项式函数。对于任何正常数c, logn 的增长速度都慢于nc,即logn=O(nc)。
多项式(polynomial)时间复杂度
• 一个多项式可以表示为
ak⋅nk+ak−1⋅nk−1+⋯+a2⋅n2+a1⋅n+a0
其中 ak>0,并且这个多项式的时间复杂度是 O(nk)。
• P难度:指多项式时间复杂度的算法可以解决的问题属于P类问题,即可以在多项式时间内解决的问题
指数时间复杂度
- 指数时间复杂度(O(2^n)):
表示算法的运行时间随着输入规模的增加而呈指数级增长。这种复杂度的算法在处理大规模问题时非常低效。
• 指数函数的定义:
指数函数可以表示为
T(n)=O(an),其中 a>1。
• 指数与多项式的比较:通过数学归纳,对于任何 c>1,nc 的增长速度最终会被 2n 所超过,即 nc=O(2n)。
• 有效算法与无效算法的分水岭:从 O(nc) 到 O(2n) 是从有效算法到无效算法的分水岭。这意味着多项式时间复杂度的算法通常被认为是有效的,而指数时间复杂度的算法则通常被认为是无效的。
举例:子集和问题(SubsetSum Problem)
给定一个正整数集合S={a1,a2,…,an} 和一个正整数 t,问题在于判断是否存在 S 的一个子集 T,使得 T 中元素的和恰好等于 t。
-
数学表述:
对于所有S⊂Z+(正整数集合),如果0≤t≤s=∑ak,是否存在T⊆S 使得∑a∈Ta=t。 -
实际应用:
曹冲称象的故事:从一堆石头中挑选出与大象重量相等的石头。 -
子集和问题的直观解法:
- 通过枚举集合 S 的所有子集,并计算它们的总和来检查是否存在一个子集的和等于给定的值 t。
算法实现
- 递归函数 sSum(S, t) 用于解决子集和问题。
- 如果 t==0,返回 true,表示找到了一个子集和为 t。
- 如果 n==0,返回 false,表示在当前子集中没有找到和为 t 的子集。
- 通过分类(classification)去掉最后一个元素 an,然后递归调用 sSum(S, t) 或 sSum(S, t - a_n)。
- 时间复杂度:
- 在最坏的情况下,需要检查 S 的每一个子集。
- 集合 S 的子集总数为 2∣S∣=2n,其中 ∣S∣ 是集合 S 的元素数量。
很遗憾,对于SubsetSum问题,我们目前没有比直观算法更优的解决方案。SubsetSum问题被归类为NP完全问题(SubsetSum is NP-complete)。这意味着在当前的计算模型下,不存在已知的多项式时间算法能够解决所有SubsetSum问题的实例。
层级划分
“先胖不算胖 路遥知马力”
• 指数函数 2n 的增长速度远远超过其他函数,尤其是在 𝑛 较大时。
• 多项式函数 𝑛3 和 𝑛2 也增长得很快,但不如指数函数。
• 线性函数 n、nlogn、平方根 n1/2 和对数 logn 的增长速度相对较慢,其中 logn 的增长速度最慢。
• 在渐近分析中,高级语言的指令和RAM的基本指令在效率上大体相当。
• 分支转向:使用 goto 语句,这是算法中用于控制流的基本结构,尽管在结构化编程中通常被隐藏。
• 迭代循环:for()、while() 等循环结构本质上是“if + goto”的组合。
• 调用和递归:函数调用和递归(自我调用)在本质上也是 goto 语句的使用。
级数
收敛级数
• 算术级数: 与末项平方同阶,例如 T(n)=1+2+…+n 时间复杂度为 𝑂(𝑛2)。
• 幂方级数: 比幂次高出一阶,例如 T(n)=12+22+…+n2 的和为6n(n+1)(2n+1),时间复杂度为O(n3)。
• 几何级数: 与末项同阶,如Ta(n)=a+a2+…+an 时间复杂度为 O(an)。
发散级数
• 调和级数: h(n)=1+1/2+…+1/n,其增长趋势为 Θ(logn)。
• 对数级数: ln1+ln2+…+lnn=ln12…n,其增长趋势为Θ(n⋅logn)。
• 对数+线性+指数: 1log1+2log2+…+nlogn=O(n2logn)
1×2+2×22+…+n2n=O(n*2n)
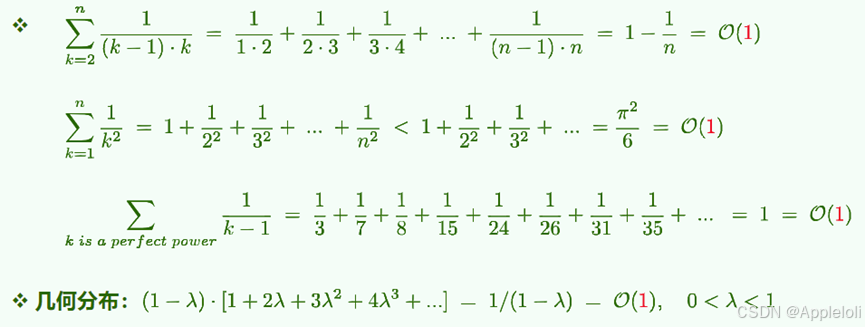
迭代
迭代+算数级数
O(n2):
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
print(const i, const j);
for (int i = 0; i < n; i++)
for (int j = 0; j < i; j++)
print(i, j);
for (int i = 0; i < n; i++)
for (int j = 0; j < i; j += 2024)
print(i, j);
O(n):
for (int i = 1; i < n; i <<= 1)
for (int j = 0; j < i; j++)
print(i, j);
O(nlogn):
for (int i = 0; i <= n; i++)
for (int j = 1; j < i; j += j)
print(i, j);
T(n)=log21+log22+…+log2n=O(nlogn)
封底估算
n=109, Bubblesort: 时间复杂度为O(n2)
Mergesort: 时间复杂度为 O(nlogn)
| 设备 | boublesort | mergesort |
|---|---|---|
| 普通PC(1GHz, 109109 flops) | 109 秒,即30年 | 30秒 |
| 天河1A(千万亿次,10151015 flops) | 103秒,即20分钟 | 0.03毫秒 |
减治法
原问题(规模为 𝑛)被分解为两个子问题:一个是规模缩减的子问题(规模为 𝑛−1),另一个是平凡子问题(规模为 1)。
- 首先解决平凡子问题(规模为 1),这通常很容易解决。
- 然后解决规模缩减的子问题(规模为 𝑛−1n−1)。
- 通过合并两个子问题的解来得到原问题的解。
空间复杂度主要取决于递归调用栈的深度,即递归调用的最大深度
举例:Reverse
O(n):
void reverse(int *A, int n) {
if (n < 2) return;
swap(A[0], A[n - 1]);
reverse(A + 1, n - 2);
}
分治法
- 将原问题划分为若干个子问题,通常这些子问题规模相当,且易于处理。
- 分别求解这些子问题。每个子问题都是原问题的一个更小的实例。
- 将子问题的解合并,形成原问题的解。这一步涉及到将子问题的解决方案整合起来,以构建原始问题的完整解决方案。
**T(n)=1+2+4+…+2log~2~n=2×2logn-1=O(n)**
从递推的角度来看,为了求解 sum(A, lo, hi),需要递归地求解两个子问题 sum(A, lo, mi) 和 sum(A, mi, hi),其中 mi 是 lo 和 hi 的中点。
- 递归步骤:
- 递归求解规模为 n/2 的问题,即 2 * T(n/2)。
- 将子问题的解累加,这是一个常数时间操作,记为 O(1)。
- 递推方程:
- 递推方程表示为 T(n) = 2 * T(n/2) + O(1)。
- 基础情况(base case)为 T(1) = O(1),即当问题规模为1时,操作的时间复杂度为常数。
- 求解递推方程:
- 通过递推方程展开,可以得出 T(n) = 4 * T(n/4) + O(3) = 8 * T(n/8) + O(7) = 16 * T(n/16) + O(15) = …。
- 这可以进一步简化为 T(n) = n * T(1) + O(n - 1)。
- 由于 T(1) 是常数,所以 T(n) = O(2n - 1),最终得出 T(n) = O(n)。
主定理
分治策略对应的递推式通常形式为 T(n)=a×T(n/b)+O(g(n)),其中 𝑎 是子问题的数量,𝑏是每个子问题的规模,g(n) 是合并子问题解的时间
• 情况分析:
- 如果 g(n)=Ω(nlogba+ϵ),则T(n)=Θ(g(n))。这意味着如果合并步骤的时间复杂度占主导,则总的时间复杂度由合并步骤决定。
- 如果 g(n)=O(nlogba−ϵ),则T(n)=Θ(nlogba)。这意味着如果子问题的解时间复杂度占主导,则总的时间复杂度由递归步骤决定。
- 如果g(n)=Θ(nlogba⋅logkn) 且 0≤k,则 T(n)=Θ(g(n)⋅logn)=Θ(nlogba⋅logk+1n)
应用实例:
- 快速选择(QuickSelect, 平均情况): 𝑇(𝑛)=1⋅𝑇(𝑛/2)+𝑂(𝑛)=𝑂(𝑛)T(n)=1⋅T(n/2)+O(n)=O(n)。这是一个典型的分治算法,其中 𝑎=1和 𝑏=2,合并步骤是线性的。
𝑔(𝑛)=𝑂(𝑛) 的原因如下:
划分步骤:快速选择算法首先将数组划分为两部分,一部分包含所有小于基准的元素,另一部分包含所有大于基准的元素。这个过程涉及到与数组中的每个元素进行比较,以确定它们与基准的关系。这一步的时间复杂度是线性的,即 𝑂(𝑛)。
- 递归求和(Recursive Sum): 𝑇(𝑛)=2⋅𝑇(𝑛/2)+𝑂(1)=𝑂(𝑛)T(n)=2⋅T(n/2)+O(1)=O(n)。这里,每个子问题被进一步分解为两个更小的子问题。
3.k-d 搜索(k-d Search): 𝑇(𝑛)=2⋅𝑇(𝑛/4)+𝑂(1)=𝑂(𝑛1/2) - 大整数乘法(Large Integer Multiplication): T(n)=3×T(n/2)+O(n)=O(nlog23)。这是一个分治乘法,其中问题被分解为三个子问题。
考虑两个长度为 𝑛 的大整数相乘的问题。分治算法(Divide and Conquer, DAC):将两个大整数 𝐴𝐵和 𝐶𝐷分别分成两部分,每部分长度为 𝑛/2。通过分治法,将原问题分解为更小的子问题。递归关系:递归关系式T(n)=4⋅T(n/2)+O(n) 描述了算法的时间复杂度。这里,𝑇(𝑛) 表示解决规模为 𝑛 的问题所需的时间。AC⋅102n+(AD+BC)⋅10n+BD
优化的大整数乘法,将两个大整数 𝐴𝐵 和 𝐶𝐷 分别分成两部分,每部分长度为 𝑛/2。通过分治法,将原问题分解为更小的乘法问题:𝐴𝐶,BD,及 (A−B)×(D−C)。最终乘法公式:利用公式 B×C+A×D=A⋅C+B⋅D+(A−B)×(D−C) 来计算最终结果。
- 二分搜索(Binary Search): 𝑇(𝑛)=1⋅𝑇(𝑛/2)+𝑂(1)=𝑂(log𝑛)T(n)=1⋅T(n/2)+O(1)=O(logn)
- 归并排序(Merge Sort): 𝑇(𝑛)=2⋅𝑇(𝑛/2)+𝑂(𝑛)=𝑂(𝑛⋅log𝑛)T(n)=2⋅T(n/2)+O(n)=O(n⋅logn)。
- STL 归并排序(STL Merge Sort): 𝑇(𝑛)=2⋅𝑇(𝑛/2)+𝑂(𝑛⋅log𝑛)=𝑂(𝑛⋅log2𝑛)T(n)=2⋅T(n/2)+O(n⋅logn)=O(n⋅log2n)。
Akra-Bazzi 定理
• Akra-Bazzi 定理的递推式:
𝑇(𝑛)=∑𝑖=1𝑘𝑎𝑖⋅𝑇(𝑏𝑖⋅𝑛+ℎ𝑖(𝑛))+𝑂(𝑔(𝑛))T(n)=∑i=1kai⋅T(bi⋅n+hi(n))+O(g(n))
其中,𝑘组子任务,每组包含 𝑎i 个规模为 𝑏𝑖𝑛+ℎ𝑖(𝑛)bin+hi(n) 的子任务。
• 参数条件:
- 0<𝑎𝑖0<ai,0<𝑏𝑖<10<bi<1,∣ℎ𝑖(𝑛)∣=𝑂(𝑛/log2𝑛)∣hi(n)∣=O(n/log2n)
- 0≤𝑔(𝑛)0≤g(n) 且存在正的常数 𝑑d 使得 ∣𝑔′(𝑛)∣=𝑂(𝑛𝑑)∣g′(n)∣=O(nd),表示 𝑔(𝑛)g(n) 是多项式增长。
• 时间复杂度的确定:
- 如果选择 𝑝p 使得 ∑𝑖=1𝑘𝑎𝑖⋅𝑏𝑖𝑝=1∑i=1kai⋅bip=1,则时间复杂度为: 𝑇(𝑛)=Θ(𝑛𝑝⋅(1+∫1𝑛𝑔(𝑢)𝑢𝑝+1𝑑𝑢))T(n)=Θ(np⋅(1+∫1nup+1g(u)du)) 这与 ℎ𝑖(𝑛)hi(n) 无关。
• linearSelect 算法的例子:
- 坏选择:𝑇(𝑛)=1⋅𝑇(34⋅𝑛)+1⋅𝑇(14⋅𝑛)+𝑂(𝑛)=𝑂(𝑛log𝑛)T(n)=1⋅T(43⋅n)+1⋅T(41⋅n)+O(n)=O(nlogn),此时 𝑝=1p=1。
o 好选择:𝑇(𝑛)=1⋅𝑇(34⋅𝑛)+1⋅𝑇(15⋅𝑛)+𝑂(𝑛)=𝑂(𝑛)T(n)=1⋅T(43⋅n)+1⋅T(51⋅n)+O(n)=O(n),此时 𝑝<1p<1。
这个定理提供了一种方法来分析那些不符合主定理(Master Theorem)形式的分治递归关系,允许更灵活地处理子问题的规模和合并操作的成本。
总和最大区段
在给定的整数数组中找到一个连续子数组,使得这个子数组的元素总和最大。如果有多个这样的子数组,算法会优先选择较短的或者在数组中靠后的子数组。A[19]= {1, -2, 7, 2, 6, -9, 5, 6, -12, -8, 13, 0, -3, 1, -2, 8, 0, -5, 3}
-
蛮力算法
- 定义一个函数 gs_BF,它接受一个整数数组 A 和数组的长度 n 作为参数。这个函数的目的是使用蛮力策略找出最大子数组和,其时间复杂度为 O(n3)。
- 初始化变量 gs 为数组的第一个元素 A[0],这个变量用于存储当前已知的最大子数组和。
- 使用两个嵌套的 for 循环来枚举数组中所有可能的子数组。外层循环变量 lo 从 0 到 n-1,内层循环变量 hi 从 lo 到 n-1。
- 对于每一对 lo 和 hi,调用 sum 函数计算子数组 A[lo…hi] 的和。这里 sum(A, lo, ++hi) 表示计算从 lo 到 hi 的元素和,++hi 意味着在计算和之前先将 hi 增加 1。
- 如果计算出的子数组和 s 大于当前的 gs,则更新 gs。
- 最后,返回 gs 作为最大子数组和。
int gs_BF(int A[], int n) {
int gs = A[0]; // 当前已知的最大和
for (int lo = 0; lo < n; lo++) { // 枚举所有的
for (int hi = lo; hi < n; hi++) { // O(n^2)个区段!
int s = sum(A, lo, hi); // 用O(n)时间求和
if (gs < s) gs = s; // 择优、更新
}
}
return gs;
}
O(n3):两层循环来确定子数组的边界,以及一层循环来计算子数组的和。
- 蛮力算法进阶
- 初始化变量 gs 为数组的第一个元素 A[0],用于存储当前已知的最大子数组和。
- 外层循环遍历数组的每个元素,将每个元素作为子数组的起始点 lo。
- 对于每个起始点 lo,内层循环从 lo 开始,尝试扩展子数组直到数组末尾,即 hi < n。
- 在内层循环中,初始化变量 s 为 0,然后从 lo 开始递增地计算子数组的和。每次循环,将 A[hi] 加到 s 上,并将 hi 增加 1。
- 如果在内层循环中计算得到的子数组和 s 大于当前的 gs,则更新 gs。
- 外层循环结束后,返回 gs 作为最大子数组和。
int gs_IC(int A[], int n) { // 递增策略: O(n^2)
int gs = A[0]; // 当前已知的最大和
for (int lo = 0; lo < n; lo++) { // 枚举所有起始于lo
for (int s = 0, hi = lo; hi < n; hi++) { // 终止于hi的区间
s += A[hi]; // 递增地得到其总和: O(1)
if (gs < s) gs = s; // 择优、更新
}
}
return gs;
}
O(n2):省去了求sum的时间复杂度
- 分而治之策略
- 分而治之策略:将数组分为两个子数组 P 和 S,其中 P 是从 lo 到 mi 的子数组,S 是从 mi 到 hi 的子数组。这里 mi 是 lo 和 hi 之间的中点。
- 递归求解:通过递归分别求解子数组 P 和 S 内的最大子数组和(GS)。
- 跨越切分线的区段:考虑那些跨越中点 mi 的子数组。这些子数组可以被分割为两个非空的前缀和后缀,分别位于 P 和 S 中。
- 前缀和后缀的和:对于跨越中点的子数组,其和可以表示为 A[i, j) = A[i, mi) + A[mi, j),其中 i < mi < j。
- 独立计算:前缀和后缀的最大子数组和可以独立计算。对于每个子数组,找到最大的前缀和后缀,然后计算它们的和。
- 时间复杂度:由于前缀和后缀的计算可以独立进行,且每个子数组的计算时间复杂度为 O(n),因此整个算法的时间复杂度为 O(n * log n)。
- 递归:对两个子数组分别递归地应用相同的分而治之策略。如果数组长度为 𝑛,那么递归的深度将是 log𝑛,因为每次递归数组长度大约减半。
- 合并:考虑跨越中点 𝑚i的子数组。这涉及到计算两个子数组的前缀和后缀的最大子数组和。对于每个子数组,我们需要线性地扫描以找到最大前缀和后缀,这需要 O(n) 时间。(对于 A[lo,mi),从 i 到 mi 线性扫描,记录每个位置的最大后缀和。对于 A[mi,hi),从 mi 到 j 线性扫描,记录每个位置的最大前缀和。)
- 优化:这种方法通过减少不必要的计算(例如,不需要检查所有可能的子数组组合)来优化算法。
- 数学表达:图片中还展示了如何使用数学表达式来描述前缀和后缀的最大子数组和的计算,例如 S[i, mi) = max{S[k, mi) | lo ≤ k < mi} 和 S[mi, j) = max{S[mi, k) | mi ≤ k < hi}。
int gs_DC(int A[], int lo, int hi) { // Divide-And-Conquer: O(n*logn)
if (hi - lo < 2) return A[lo]; // 递归基
int mi = (lo + hi) / 2; // 在中点切分
int gsl = A[mi-1], sl = 0, i = mi; // 枚举
while (lo < i--) { // 所有[i, mi)类区段
if (gsl < (sl += A[i])) gsl = sl; // 更新
}
int gsr = A[mi], sr = 0, j = mi-1; // 枚举
while (++j < hi) { // 所有[mi, j)类区段
if (gsr < (sr += A[j])) gsr = sr; // 更新
}
return max(gsl + gsr, max(gs_DC(A, lo, mi), gs_DC(A, mi, hi))); // 递归
}
O(nlogn)
- 减而治之策略
- 定义后缀:
suffix(k) = A[k, hi),其中 k 是满足条件 sum[i, hi) ≤ 0 的最大 i 值,这里的 sum[i, hi) 表示从索引 i 到 hi 的子数组的和。 - 最大子数组的位置:
GS(lo, hi) = A[i, j),这个子数组要么是后缀 A[k, hi) 的真后缀(即 k ≤ i < j = hi),要么与之无交(即 j ≤ k)。 - 反证法证明:
假设 GS(lo, hi) = A[i, j) 与后缀 A[k, hi) 有非空的公共部分,即存在 i ≤ k < j < hi。 - 根据 GS(lo, hi) 的最大和最短性质,如果 sum[k, j) > 0,则 sum[j, hi) < 0,这与后缀 A[k, hi) 的定义矛盾,因为后缀的总和应该非正。
int gs_LS(int A[], int n) { // Linear Scan: O(n)
int gs = A[0], s = 0, i = n;
while (0 < i--) { // 在当前区间内
s += A[i]; // 递增地累计总和
if (gs < s) gs = s; // 并择优、更新
if (s <= 0) s = 0; // 剪除非正和后缀
}
return gs;
}
O(n)
动态规划
动态规划:记忆法
举例:斐波那契数列
-
斐波那契数列的定义:fib(n) = fib(n-1) + fib(n-2),这是一个递归定义。
-
递归实现:在 n 小于或等于 2 时直接返回 n,否则递归调用 fib(n-1) 和 fib(n-2) 并求和。
-
复杂度分析:
- T(0) = T(1) = 1,表示计算第 0 项和第 1 项的时间复杂度为 1。
- 对于 n > 1,T(n) = T(n-1) + T(n-2) + 1,这里的 +1 表示除了递归调用之外的额外操作(如加法)。
- 引入 S(n) = [T(n) + 1] / 2,可以发现 S(n) = S(n-1) + S(n-2),这与斐波那契数列的递推关系相似,且 S(n) =fib(n+1)。
- 时间复杂度:T(n) = 2 * S(n) - 1 = 2 * fib(n+1) - 1,由于 fib(n+1) 与 φn 成正比(其中 φ = (1+√5)/2,约等于 1.618),所以 T(n) = O(φn)。
"由于 fib(n+1) 与 φn 成正比(其中 φ = (1+√5)/2,约等于 1.618)"如果 T(n) = O(αn),那么 T(n-1) = O(α(n-1)) 和 T(n-2) = O(α(n-2))。将这些代入递归关系式,我们得到 O(αn) = O(α(n-1)) + O(α(n-2))。特征方程:代入T(2)这个方程可以转化为 α2= α1 + α0,这是一个二次方程,我们可以通过求解这个方程来找到 α 的值。解方程:解这个二次方程,我们得到 α = (1 + √5) / 2,这个值被称为黄金分割比,用希腊字母 Φ (phi) 表示。
- 指数级增长:斐波那契数列的递归实现之所以慢,是因为每个递归调用都会产生两个新的递归调用,导致调用次数呈指数级增长。这在图中通过斐波那契数列的数值增长(1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…)直观地展示出来。
递归的低效根源:存在大量重复的递归实例
φ的相关封底运算
𝜙36≈225
𝜙43=243×25/36=21075/36≈21080/36=230≈109 flops=1 sec
𝜙5≈101
𝜙67≈1014 flops=105 sec≈1 day
𝜙92≈1019 flops=1010 sec≈105 days≈3 centuries
记忆化技术
-
函数定义:定义了一个递归函数 f(n),它在 n < 1 时返回一个基本情形的值(trivial(n))。
-
记忆化数组:使用一个数组 M[N] 来存储已经计算过的结果。数组初始化为 UNDEFINED,表示这些位置尚未计算过。
-
递归调用:在递归函数中,f(n) 调用 f(n-X)、f(n-Y) 和 f(n-Z) 来计算结果。这里的 X、Y 和 Z 是问题特定的参数。
-
检查缓存:在递归调用之前,函数检查 M[n] 是否已经被定义。如果 M[n] 是 UNDEFINED,表示这个结果还没有被计算过。
-
计算并存储结果:如果 M[n] 是 UNDEFINED,则计算 f(n-X) + f(n-Y) * f(n-Z) 并将结果存储在 M[n] 中。
-
返回结果:函数返回 M[n],即存储在缓存中的结果。
通过这种方式,记忆化确保了每个递归实例只被计算一次,后续的调用可以直接从缓存中获取结果,从而避免了重复计算。这种方法显著提高了递归算法的效率,特别是对于那些具有大量重复子问题的大型问题。
// 定义一个数组 M,大小为 N,初始化为 UNDEFINED
T M[N];
// 定义函数 f(n)
def f(n) {
if (n < 1) return trivial(n);
// 仅在必要时递归,并总是写下结果
if (M[n] == UNDEFINED) {
M[n] = f(n-X) + f(n-Y) * f(n-Z);
}
return M[n];
}
O(n)
进一步优化空间复杂度
颠倒计算方向,即从自顶向下的递归改为自底向上的迭代。
-
动态规划的颠倒计算方向:它从底部开始,逐步向上构建解决方案。
-
斐波那契数列的迭代实现:这个算法使用两个变量 f 和 g 来存储连续的斐波那契数值,其中 f 代表 fib(n-1),g 代表 fib(n)。
-
算法步骤:
- 初始化 f = 1 和 g = 0,这对应于斐波那契数列的前两个值 fib(-1) = 1 和 fib(0) = 0。
- 使用 while 循环从 n 递减到 0,在每次迭代中:更新 g 为 g + f,这实际上是计算 fib(n)。
然后更新 f 为 g - f,这使得 f 现在存储的是下一个斐波那契数 fib(n+1)。 - 循环结束后,g 将包含 fib(n) 的值。
// 动态规划:颠倒计算方向
// 由自顶而下递归,改为自底而上迭代
int f = 1; int g = 0; // fib(-1), fib(0)
while (0 < n--) {
g = g + f;
f = g - f;
}
return g;
时间复杂度是 O(n),因为算法需要迭代 n 次。空间复杂度是 O(1),因为算法只需要常数级别的额外空间来存储 f 和 g。
动态规划:最强公共子序列
定义
-
子序列(Subsequence):子序列是由一个序列中的若干字符组成的,这些字符保持了它们在原序列中的相对次序。
-
最长公共子序列(LCS):LCS 是指两个序列中公共子序列中最长的一个。如 “educational” 和 “didactical” 作为示例,它们之间的最长公共子序列是"data"。
减治递归+分治递归策略
一种通过减少问题规模来逐步解决原始问题的方法。在 LCS 问题中,通过比较两个序列的最后一个字符,逐步减少序列的长度,直到达到基本情况。
序列表示:图片中使用 A[0,n-1) 和 B[0,m-1) 来表示序列 A 和 B 的子序列,其中 n 和 m 分别是序列 A 和 B 的长度。
递归的情况:
- 如果序列 A 或 B 的长度为 0(即 n=0 或 m=0),则 LCS 为一个空序列,长度为零。这是递归的基本情况,因为任何序列与空序列的最长公共子序列都是空序列。
- 递归过程:在递归过程中,通过比较两个序列的最后一个字符,如果它们相同,则将这个字符添加到 LCS 中,并递归地求解剩余序列的 LCS。(减治)如果不同,则需要递归地考虑去掉其中一个序列的最后一个字符后的情况。(分治)
- 递归基:递归基是递归过程的终止条件,即当序列长度为 0 时,LCS 为一个空序列。
unsigned int lcs(char const * A, int n, char const * B, int m) {
if (n < 1 || m < 1) // trivial cases
return 0;
if (A[n-1] == B[m-1]) // decrease & conquer
return 1 + lcs(A, n-1, B, m-1);
else // divide & conquer
return max(lcs(A, n-1, B, m), lcs(A, n, B, m-1));
}
最好情况O(n+m)
最坏情况O(2n):每次递归调用都可能产生两个新的递归调用,且递归深度为 n
这是因为在递归过程中,如果两个序列的最后一个字符不相同,算法需要分别递归地处理去掉一个字符后的两个序列,这会导致很多重复的子问题。
记忆化版
unsigned int lcsMemo(char const* A, int n, char const* B, int m) {
unsigned int* lcs = new unsigned int[n * m];
memset(lcs, 0xFF, sizeof(unsigned int) * n * m);
unsigned int solu = lcsM(A, n, B, m, lcs, m);
delete[] lcs;
return solu;
}
unsigned int lcsM(char const* A, int n, char const* B, int m, unsigned int* const lcs, int const M) {
if (n < 1 || m < 1) return 0; // trivial cases
if (UINT_MAX != lcs[(n - 1) * M + m - 1]) return lcs[(n - 1) * M + m - 1]; // recursion stops
return lcs[(n - 1) * M + m - 1] =
(A[n - 1] == B[m - 1]) ?
1 + lcsM(A, n - 1, B, m - 1, lcs, M) :
max(lcsM(A, n - 1, B, m, lcs, M), lcsM(A, n, B, m - 1, lcs, M));
}
通过记忆化,这个算法的时间复杂度从指数级降低到多项式级,通常是 O(n×m)
动态规划
- 如果 A[i-1] == B[j-1],则 LCS(i, j) = LCS(i-1, j-1) + 1,表示当前字符是公共子序列的一部分。
- 如果 A[i-1] != B[j-1],则 LCS(i, j) = max(LCS(i-1, j), LCS(i, j-1)),表示当前字符不是公共子序列的一部分,需要取去掉当前字符后的两个序列的LCS长度的最大值。
unsigned int lcs(char const* A, int n, char const* B, int m) {
if (n < m) {
swap(A, B);
swap(n, m); // 确保 m <= n
}
unsigned int* lcs1 = new unsigned int[m + 1]; // 当前两行
unsigned int* lcs2 = new unsigned int[m + 1]; // 交替缓冲
memset(lcs1, 0x00, sizeof(unsigned int) * (m + 1)); // 初始化为0
lcs2[0] = 0; // 哨兵值
for (int i = 0; i < n; swap(lcs1, lcs2), i++) {
for (int j = 0; j < m; j++) {
lcs2[j + 1] = (A[i] == B[j]) ? 1 + lcs1[j] : max(lcs2[j], lcs1[j + 1]);
}
}
unsigned int solu = lcs1[m]; // 结果存储在lcs1[m]
delete[] lcs1;
delete[] lcs2;
return solu;
}
时间复杂度O(mn) 空间复杂度O(mn)
Reference
- 本文全部代码与知识框架来源老师课堂讲义+授课内容+笔者自我理解
- 对应课程:https://www.xuetangx.com/course/THU08091000384/21556795
- 不当之处欢迎指正


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









