






转自:
概念:
Reactor这个词译成汉语还真没有什么合适的,很多地方叫反应器模式,但更多好像就直接叫reactor模式了,其实我觉着叫应答者模式更好理解一些。通过了解,这个模式更像一个侍卫,一直在等待你的召唤,或者叫召唤兽。
并发系统常使用reactor模式,代替常用的多线程的处理方式,节省系统的资源,提高系统的吞吐量。
先用比较直观的方式来介绍一下这种方式的优点,通过和常用的多线程方式比较一下,可能更好理解。
以一个餐饮为例,每一个人来就餐就是一个事件,他会先看一下菜单,然后点餐。就像一个网站会有很多的请求,要求服务器做一些事情。处理这些就餐事件的就需要我们的服务人员了。
在多线程处理的方式会是这样的:
一个人来就餐,一个服务员去服务,然后客人会看菜单,点菜。 服务员将菜单给后厨。
二个人来就餐,二个服务员去服务……
五个人来就餐,五个服务员去服务……
这个就是多线程的处理方式,一个事件到来,就会有一个线程服务。很显然这种方式在人少的情况下会有很好的用户体验,每个客人都感觉自己是VIP,专人服务的。如果餐厅一直这样同一时间最多来5个客人,这家餐厅是可以很好的服务下去的。
来了一个好消息,因为这家店的服务好,吃饭的人多了起来。同一时间会来10个客人,老板很开心,但是只有5个服务员,这样就不能一对一服务了,有些客人就要没有人管了。老板就又请了5个服务员,现在好了,又能每个人都受VIP待遇了。
越来越多的人对这家餐厅满意,客源又多了,同时来吃饭的人到了20人,老板高兴不起来了,再请服务员吧,占地方不说,还要开工钱,再请人就攒不到钱了。怎么办呢?老板想了想,10个服务员对付20个客人也是能对付过来的,服务员勤快点就好了,伺候完一个客人马上伺候另外一个,还是来得及的。综合考虑了一下,老板决定就使用10个服务人员的线程池啦~~~
但是这样有一个比较严重的缺点就是,如果正在接受服务员服务的客人点菜很慢,其他的客人可能就要等好长时间了。有些火爆脾气的客人可能就等不了走人了。
Reactor如何处理这个问题呢:
老板后来发现,客人点菜比较慢,大部服务员都在等着客人点菜,其实干的活不是太多。老板能当老板当然有点不一样的地方,终于发现了一个新的方法,那就是:当客人点菜的时候,服务员就可以去招呼其他客人了,等客人点好了菜,直接招呼一声“服务员”,马上就有个服务员过去服务。嘿嘿,然后在老板有了这个新的方法之后,就进行了一次裁员,只留了一个服务员!这就是用单个线程来做多线程的事。
实际的餐馆都是用的Reactor模式在服务。一些设计的模型其实都是从生活中来的。
Reactor模式主要是提高系统的吞吐量,在有限的资源下处理更多的事情。
在单核的机上,多线程并不能提高系统的性能,除非在有一些阻塞的情况发生。否则线程切换的开销会使处理的速度变慢。就像你一个人做两件事情,1、削一个苹果。2、切一个西瓜。那你可以一件一件的做,我想你也会一件一件的做。如果这个时候你使用多线程,一会儿削苹果,一会切西瓜,可以相像究竟是哪个速度快。这也就是说为什么在单核机上多线程来处理可能会更慢。
但当有阻碍操作发生时,多线程的优势才会显示出来,现在你有另外两件事情去做,1、削一个苹果。2、烧一壶开水。我想没有人会去做完一件再做另一件,你肯定会一边烧水,一边就把苹果削了。
理论的东西就不多讲了,请大家参考一下附件《reactor-siemens.pdf》。图比较多,E文不好也可以看懂的。
讲解:
Proactor和Reactor都是并发编程中的设计模式。在我看来,他们都是用于派发/分离IO操作事件的。这里所谓的
IO事件也就是诸如read/write的IO操作。"派发/分离"就是将单独的IO事件通知到上层模块。两个模式不同的地方
在于,Proactor用于异步IO,而Reactor用于同步IO。
摘抄一些关键的东西:
"
Two patterns that involve event demultiplexors are called Reactor and Proactor [1]. The Reactor patterns
involve synchronous I/O, whereas the Proactor pattern involves asynchronous I/O.
"
关于两个模式的大致模型,从以下文字基本可以明白:
"
An example will help you understand the difference between Reactor and Proactor. We will focus on the read
operation here, as the write implementation is similar. Here's a read in Reactor:
* An event handler declares interest in I/O events that indicate readiness for read on a particular socket ;
* The event demultiplexor waits for events ;
* An event comes in and wakes-up the demultiplexor, and the demultiplexor calls the appropriate handler;
* The event handler performs the actual read operation, handles the data read, declares renewed interest in
I/O events, and returns control to the dispatcher .
By comparison, here is a read operation in Proactor (true async):
* A handler initiates an asynchronous read operation (note: the OS must support asynchronous I/O). In this
case, the handler does not care about I/O readiness events, but is instead registers interest in receiving
completion events;
* The event demultiplexor waits until the operation is completed ;
* While the event demultiplexor waits, the OS executes the read operation in a parallel kernel thread, puts
data into a user-defined buffer, and notifies the event demultiplexor that the read is complete ;
* The event demultiplexor calls the appropriate handler;
* The event handler handles the data from user defined buffer, starts a new asynchronous operation, and returns
control to the event demultiplexor.
"
可以看出,两个模式的相同点,都是对某个IO事件的事件通知(即告诉某个模块,这个IO操作可以进行或已经完成)。在结构
上,两者也有相同点:demultiplexor负责提交IO操作(异步)、查询设备是否可操作(同步),然后当条件满足时,就回调handler。
不同点在于,异步情况下(Proactor),当回调handler时,表示IO操作已经完成;同步情况下(Reactor),回调handler时,表示
IO设备可以进行某个操作(can read or can write),handler这个时候开始提交操作。
用select模型写个简单的reactor,大致为:
 ///
///
 class handler
{
class handler
{ public: virtual void onRead() = 0; virtual void onWrite() = 0; virtual void onAccept() = 0;
public: virtual void onRead() = 0; virtual void onWrite() = 0; virtual void onAccept() = 0; };
class dispatch
{public: void poll()
};
class dispatch
{public: void poll() { // add fd in the set. //
{ // add fd in the set. // // poll every fd int c = select( 0, &read_fd, &write_fd, 0, 0 ); if( c > 0 ) { for each fd in the read_fd_set { if fd can read _handler->onRead(); if fd can accept _handler->onAccept();
// poll every fd int c = select( 0, &read_fd, &write_fd, 0, 0 ); if( c > 0 ) { for each fd in the read_fd_set { if fd can read _handler->onRead(); if fd can accept _handler->onAccept(); } for each fd in the write_fd_set { if fd can write _handler->onWrite(); } } } void setHandler( handler *_h ) { _handler = _h; } private: handler *_handler;};
/// application
class MyHandler :
public handler
{public: void onRead() { } void onWrite() { } void onAccept() { }};
} for each fd in the write_fd_set { if fd can write _handler->onWrite(); } } } void setHandler( handler *_h ) { _handler = _h; } private: handler *_handler;};
/// application
class MyHandler :
public handler
{public: void onRead() { } void onWrite() { } void onAccept() { }};
在网上找了份Proactor模式比较正式的文档,其给出了一个总体的UML类图,比较全面:
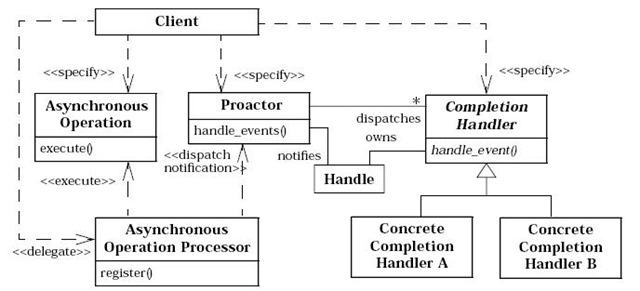
根据这份图我随便写了个例子代码:
class AsyIOProcessor
{public: void do_read() { //send read operation to OS // read io finished.and dispatch notification _proactor->dispatch_read(); } private: Proactor *_proactor;};
class Proactor
{public: void dispatch_read() { _handlerMgr->onRead(); } private: HandlerManager *_handlerMgr;};
class HandlerManager
{public: typedef std::list<Handler*> HandlerList; public: void onRead() { // notify all the handlers. std::for_each( _handlers.begin(), _handlers.end(), onRead ); } private: HandlerList *_handlers;};
class Handler
{public: virtual void onRead() = 0;};
//
application level handler.
class MyHandler :
public Handler
{public: void onRead() { // }};
Reactor通过某种变形,可以将其改装为Proactor,在某些不支持异步IO的系统上,也可以隐藏底层的实现,利于编写跨平台
代码。我们只需要在dispatch(也就是demultiplexor)中封装同步IO操作的代码,在上层,用户提交自己的缓冲区到这一层,
这一层检查到设备可操作时,不像原来立即回调handler,而是开始IO操作,然后将操作结果放到用户缓冲区(读),然后再
回调handler。这样,对于上层handler而言,就像是proactor一样。详细技法参见这篇文章。
其实就设计模式而言,我个人觉得某个模式其实是没有完全固定的结构的。不能说某个模式里就肯定会有某个类,类之间的
关系就肯定是这样。在实际写程序过程中也很少去特别地实现某个模式,只能说模式会给你更多更好的架构方案。
最近在看spserver的代码,看到别人提各种并发系统中的模式,有点眼红,于是才来扫扫盲。知道什么是leader follower模式,
reactor, proactor,multiplexing,对于心中的那个网络库也越来越清晰。
最近还干了些离谱的事,写了传说中的字节流编码,用模板的方式实现,不但保持了扩展性,还少写很多代码;处于效率考虑,
写了个static array容器(其实就是template <typename _Tp, std::size_t size> class static_array { _Tp _con[size]),
加了iterator,遵循STL标准,可以结合进STL的各个generic algorithm用,自我感觉不错。基础模块搭建完毕,解析了公司
服务器网络模块的消息,我是不是真的打算用自己的网络模块重写我的验证服务器?在另一个给公司写的工具里,因为实在厌恶
越来越多的重复代码,索性写了几个宏,还真的做到了代码的自动生成:D。
对优雅代码的追求真的成了种癖好. = =|















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









