









一、串的定义
串(string)是由零个或多个字符组成的有限序列,又名叫字符串。
一般记作: s="a1a2a3...an";
字符串的基本操作方法:

二、串的存储结构
1.串的顺序存储结构:串的顺序存储结构是用一组地址连续的存储单元来存储串中的字符序列的。
2.串的链式存储结构:总的来说不如顺序存储灵活,性能也不如顺序存储结构好。
三、朴素的模式匹配算法
子串的定位操作通常称作串的模式匹配,是串中最重要的操作之一。
算法如下:
/*操作Index的实现算法*/
//T为非空串。若主串S中第pos个字符之后存在与T相等的子串,则返回第一个这样的子串,则返回第一个这样的子串在S中的位置,否则返回0
int Index(String S,String T,int pos)
{
int n,m,i;
String sub;
if (pos > 0)
{
n = StrLength(S);
m = StrLength(T);
i = pos;
while (i <= n-m+1)
{
SubString (sub,S,i,m); //取主串第i个位置,长度与T相等子串给sub
if (StrCompare(sub,T) != 0) //如果不相等
++i;
else
return i;
}
}
return 0;
}
四、KMP模式匹配算法
我们可以忍受朴素模式匹配算法的低效吗?也许不可以,也许无所谓。但在很多年前我们的科学家们,觉得像这种有多个0和1重复字符的字符串,却需要挨个遍历的算法是非常糟糕的事情。于是有三位前辈,发表一个模式匹配算法,可以大大避免重复遍历的情况,我们把它称为KMP算法。
kmp算法完成的任务是:给定两个字符串O和f,长度分别为n和m,判断f是否在O中出现,如果出现则返回出现的位置。常规方法是遍历a的每一个位置,然后从该位置开始和b进行匹配,但是这种方法的复杂度是O(nm)。kmp算法通过一个O(m)的预处理,使匹配的复杂度降为O(n+m)。
kmp算法思想
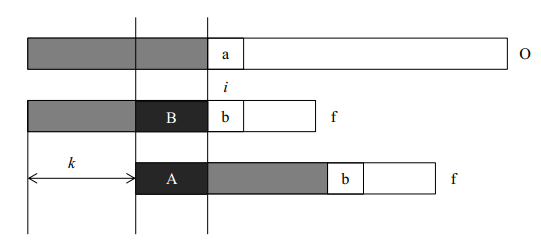
我们首先用一个图来描述kmp算法的思想。在字符串O中寻找f,当匹配到位置i时两个字符串不相等,这时我们需要将字符串f向前移动。常规方法是每次向前移动一位,但是它没有考虑前i-1位已经比较过这个事实,所以效率不高。事实上,如果我们提前计算某些信息,就有可能一次前移多位。假设我们根据已经获得的信息知道可以前移k位,我们分析移位前后的f有什么特点。我们可以得到如下的结论:
- A段字符串是f的一个前缀。
- B段字符串是f的一个后缀。
- A段字符串和B段字符串相等。
所以前移k位之后,可以继续比较位置i的前提是f的前i-1个位置满足:长度为i-k-1的前缀A和后缀B相同。只有这样,我们才可以前移k位后从新的位置继续比较。
所以kmp算法的核心即是计算字符串f每一个位置之前的字符串的前缀和后缀公共部分的最大长度(不包括字符串本身,否则最大长度始终是字符串本身)。获得f每一个位置的最大公共长度之后,就可以利用该最大公共长度快速和字符串O比较。当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串f向前移动(已匹配长度-最大公共长度)位,接着继续比较下一个位置。事实上,字符串f的前移只是概念上的前移,只要我们在比较的时候从最大公共长度之后比较f和O即可达到字符串f前移的目的。
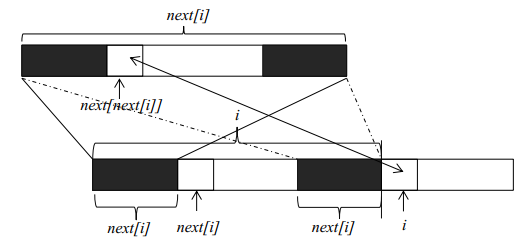
next数组计算
理解了kmp算法的基本原理,下一步就是要获得字符串f每一个位置的最大公共长度。这个最大公共长度在算法导论里面被记为next数组。在这里要注意一点,next数组表示的是长度,下标从1开始;但是在遍历原字符串时,下标还是从0开始。假设我们现在已经求得next[1]、next[2]、……next[i],分别表示长度为1到i的字符串的前缀和后缀最大公共长度,现在要求next[i+1]。由上图我们可以看到,如果位置i和位置next[i]处的两个字符相同(下标从零开始),则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为next[next[i]]的字符串,直到字符串长度为0为止。由此我们可以写出求next数组的代码(java版):
上述代码需要注意的问题是,我们求取的next数组表示长度为1到m的字符串f前缀的最大公共长度,所以需要多分配一个空间。而在遍历字符串f的时候,还是从下标0开始(位置0和1的next值为0,所以放在循环外面),到m-1为止。代码的结构和上面的讲解一致,都是利用前面的next值去求下一个next值。
字符串匹配
计算完成next数组之后,我们就可以利用next数组在字符串O中寻找字符串f的出现位置。匹配的代码和求next数组的代码非常相似,因为匹配的过程和求next数组的过程其实是一样的。假设现在字符串f的前i个位置都和从某个位置开始的字符串O匹配,现在比较第i+1个位置。如果第i+1个位置相同,接着比较第i+2个位置;如果第i+1个位置不同,则出现不匹配,我们依旧要将长度为i的字符串分割,获得其最大公共长度next[i],然后从next[i]继续比较两个字符串。这个过程和求next数组一致,所以可以匹配代码如下(java版):
public void search(String original, String find, int next[]) {
int j = 0;
for (int i = 0; i < original.length(); i++) {
while (j > 0 && original.charAt(i) != find.charAt(j))
j = next[j];
if (original.charAt(i) == find.charAt(j))
j++;
if (j == find.length()) {
System.out.println("find at position " + (i - j));
System.out.println(original.subSequence(i - j + 1, i + 1));
j = next[j];
}
}
}上述代码需要注意的一点是,每次我们得到一个匹配之后都要对j重新赋值。
复杂度
kmp算法的复杂度是O(n+m),可以采用均摊分析来解答,具体可参考算法导论。















 2197
2197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









