







 本文介绍了使用flume、kafka、spark stream和hbase构建的大数据日志收集系统。flume作为数据收集工具,支持多种数据源,通过kafka进行消息传递,spark stream作为消费者处理数据,最终将数据存储到hbase。配置过程中涉及flume的source、channel和sink,kafka的配置,以及spark stream读取kafka并写入hbase的步骤。此外,文章还讨论了为何选择这套组合以及hbase在存储方面的优势。
本文介绍了使用flume、kafka、spark stream和hbase构建的大数据日志收集系统。flume作为数据收集工具,支持多种数据源,通过kafka进行消息传递,spark stream作为消费者处理数据,最终将数据存储到hbase。配置过程中涉及flume的source、channel和sink,kafka的配置,以及spark stream读取kafka并写入hbase的步骤。此外,文章还讨论了为何选择这套组合以及hbase在存储方面的优势。
前言
flume+kafka+spark stream 是目前比较常用的一套大数据消息日志收集管理框架,至于最后是入到Hive或者者Hbase需看不同业务场景,下面以HBase为场景简述下整个配置与搭建流程以及这些框架如此搭配的优点。
1. flume 配置
1.1 flume 简介
从官网文档 https://flume.apache.org 可以知道Flume的定位是很清晰的,它提供了一个分布式的,高可用的桥梁链接,可以收集、聚合和移动大量的日志数据,从许多不同的数据源到集中式数据存储,大概的结构如下图,流程大致为 从源端(source)接收数据,经过管道(channel)的缓存等等,发送到目标(sink)端。:
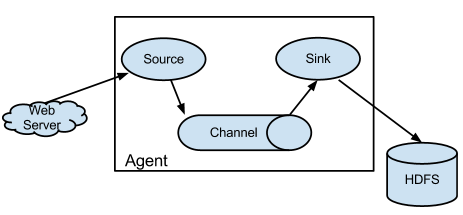
其中source的定义flume提供了很多方式,常用的有以下几种:
Http source,这种方式可以通过监听接口方式来收集log;Exec source,这种方式可以通过执行一些shell命令来收集log,例如通过tail -f 文件来监听文件追加的日志;Spooling source,这种方式可以监听某个目录的log,当有新的log产生时即会被发送出去;- 还有很多其他的方式,例如可以以
kafka作为source,这样flume就充当了kafka的消费者,当然还有很多如Avro source,Thrift source,TCP类的等等,具体参考官网文档更加相应场景配置即可。
channel同样flume提供了很多方式,memory channel这种方式已经不太建议了,原因也很明显,不够安全,当出现任何机器问题时数据就会丢失,file channel和kafka channel是比较推荐的做法,特别是当需要比较高的并发时,kafka channel是一个不错的选择。
sink同样flume提供了很多方式,常用的有以下几种:
HDFS/Hive/Hbase/ElasticSearch sink,直接写入hdfs/Hive/Hbase/ElasticSearch,这种方式适合那些比较无需做ETL的场景。kafka sink,直接充当kafka的生产者,可以看到kafka可以在整个flume生命周期里可以自由穿插。Http sink,直接通过post方法将数据发送到目标api。- 其他的一些详细见官网文档即可。
1.2 flume 配置
下面以Spooling Directory Source -> file channel -> kafka sink为例:
一份样例配置参数:
# Name the components on this agent
agent.sources = dir-src
agent.sinks = kafka-sink
agent.channels = file-channel
# Describe/configure the source
agent.sources.dir-src.type = spooldir
agent.sources.dir-src.spoolDir = #监听目录
agent.sources.dir-src.fileHeader = true
agent.sources.dir-src.deserializer.maxLineLength=1000000
# Describe the sink
agent.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kafka-sink.kafka.topic = test
agent.sinks.kafka-sink.kafka.bootstrap.servers = #kafka boostrapServer
# Use a channel which buffers events in file
agent.channels.file-channel.type = file
agent.channels.file-channel.checkpointDir = # checkpoint目录
agent.channels.file-channel.dataDirs = # 缓存的数据目录
# Bind the source and sink to the channel
agent.sources.dir-src.channels = file-channel
agent.sinks.kafka-sink.channel = file-channel配置详解:
- 首先每个flume配置表可以存在多个agent,多个source,多个channel,多个sink,所以可以根据相应业务场景进行组合。
- 对于每个agent,必须配置相应的
source/channel/sink,通过agent.source = ???,agent.channel = ???,agent.sink = ???来指定。 - 对于具体的
source/channel/sink,通过agent.{source/channel/sink}.???.属性 = ...来具体配置source/channel/sink的属性。 - 配置完
source/channel/sink相应的属性后,需把相应的组件串联一起,如:agent.sources.dir-src.channels = file-channel其中dir-src这个source指定了其channel为我们定义好的file-channel.
一些Tips:
- flume在收集log的时候经常会出现
Line length exceeds max (2048), truncating line!,这个一般情况对于一些log的存储没影响,但是遇到需要解析log的情况就有问题了,有时一个json或者其他格式的log被截断了,解析也会出问题,所以在source的属性配置里可以通过参数deserializer.maxLineLength调高默认的2048。 - flume在监听相应的目录时,如果有重名的文件,或者直接在监听目录下修改相应正在读取的文件时,都会报错,而且flume-ng目前没有这种容错机制,报错只能重启了,还有一个比较大的问题,flume-ng没有提供相应的kill脚本,只能通过shell直接
ps -aux | grep flume找到相应的PID,然后手动kill。 - flume在监听相应目录时,如果目录下的文件是通过HTTP或者scp传输过来的,小文件的话没问题,但是当文件大小超过网络传输速率,就会造成flume读取文件时报错直接显示文件大小正在变化,这点也是比较麻烦的,所以建议是现有个临时目录先存放文件,等文件传输完成后再通过shell的
mv命令直接发送到监听目录。 - 有时候我们的log文件是以压缩的方式传输过来,但是如果我们想解析后才发送出去的话,可以将当前的
Spooling Directory Source的改为Exec Source,可以指定改source的command参数里写shell解析命令。
flume的启动:
flume-ng agnet --conf "配置文件文件目录" --conf-file  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









