






本文借鉴了网络上多位牛人的搭建经验,结合自身的环境,多次尝试与错误修正下,整理了“ubuntu搭建hadoop伪分布式环境:jdk1.8.0+hadoop2.8.0+eclipse-jee-neon-3”的详细步骤及相关注意事项。首先,说明下基本流程:1、环境了解与基本配置;2、相关资源的准备;3、JDK配置;4、hadoop安装与实例测试;5、伪分布式配置与实例测试;6、eclipse的使用与配置;7、相关问题;8、参考文献
1、环境了解与基本配置
本文使用的是vmware10虚拟机安装unbuntu16.04(64位)环境,机器名为hadoop。
2、相关资源的准备
- hadoop-2.7.3.tar.gz :https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.3/
- eclipse-java-neon-3-linux-gtk-x86_64.tar.gz : http://www.eclipse.org/downloads/download.php?file=/technology/epp/downloads/release/neon/3/eclipse-java-neon-3-linux-gtk-x86_64.tar.gz
- openjdk-8-jdk: sudo apt-get install openjdk-8-jdk
- 也可访问我的百度云获取相关的资源:链接:http://pan.baidu.com/s/1skIOVFn 密码:3lp3
- 基本配置:
用户配置:
1)修改本机机器名,查看本机机器名
如果不是,请修改为hadoop(为了方便使用):hostname hadoop
永久修改请在/etc/hostname文件中修改:sudo vim etc/hostname,把“HOSTNAME=localhost.localdomain”改成“HOSTNAME=hadoop”保存退出即可,最后,重reboot 设置DNS解析,编辑/etc/hosts文件:sudo vim /etc/hosts
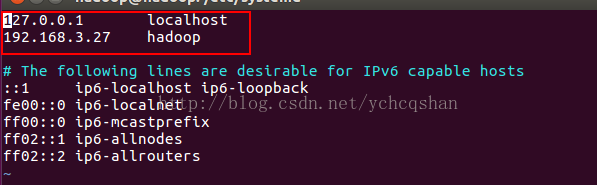
然后,看看是否成功:ping hadoop
2)新建hadoop用户,也可以新建一个hadoop用户
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
- 安装vim:{CSDN:CODE:sudo apt-get install vim}
3、JDK配置
- 安装openjdk:
{CSDN:CODE:sudo apt-get isntall openjdk-8-jdk}
- 查看安装路径:dpkg -L openjdk-8-jdk 我的路径为:/usr/lib/jvm/java-8-openjdk-amd64
- 配置环境变量:sudo vim /etc/profile 添加以下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=$JAVA_HOME/jre export CLASSHOME=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib -
使配置生效: source /etc/profile
-
查看是否配置成功: java -version
4、hadoop安装与实例测试
配置ssh无密码登录
ssh hadoop
然后,退出,进行免密登录配置
cd ~/.ssh/
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys //生成授权文件 安装hadoop
sudo tar -zxvf ~/software/hadoop-2.7.3.tar.gz -C /usr/local/
cd /usr/local
sudo mv ./hadoop-2.7.3 hadoop
chown -R hadoop ./hadoop
cd bin
./hadoop version
修改配置文件
修改hadoop-env.sh
sudo vim ./etc/hadoop/hadoop-env.sh
修改以下内容# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
export HADOOP_HOME=/usr/local/hadoop
sudo vim /etc/profile
添加 HADOOP_HOMEexport HADOOP_HOME=/usr/local/hadoop
使配置生效source /etc/profile
单机模式实例
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input //将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* //查看结果
注意,Hadoop 默认不会覆盖结果文件,若存在./output文件,则需删除 : rm -r ./output
5、伪分布式配置与实例测试
环境变量配置
sudo vim /etc/profile
修改以下内容
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=$JAVA_HOME/jre export CLASSHOME=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export HADOOP_HOME=/usr/local/hadoop export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH |
sudo vim core-site.xml
添加以下内容
| <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:9000</value> </property> </configuration> |
sudo vim hdfs-site.xml
添加以下内容
| <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration> |
sudo vim yarn-site.xml
添加以下内容
| <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
将创建mapred-site.xml文件
添加以下内容
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>hadoop:9001</value> </property> </configuration> |
./sbin/start-all.sh
jps // 查看所有启动的进程
./sbin/stop-all.sh
rm -r ./tmp // 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
./bin/hdfs namenode -format //重新格式化 NameNode
./sbin/start-all.sh // 重启
./bin/hdfs dfs -mkdir -p /user/hadoop //创建用户目录
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input //将文件复制到hdfs中的input文件夹中
./bin/hdfs dfs -ls input //查看文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+' //运行示例
./bin/hdfs dfs -cat output/* //查看结果
./bin/hdfs dfs -get output ./output // 将 HDFS 上的 output 文件夹拷贝到本机,注意本地保证没有./output目录,已经存在的话,先删除 rm -r ./output
cat ./output/* //查看结果
6、eclipse的使用与配置
sudo tar -zxvf eclipse-jee-neon-3-linux-gtk-x86_64.tar.gz -C /usr/local/
cd /usr/local
sudo mv eclipse-jee-neon-3-linux-gtk-x86_64 eclipse
cd eclipse
运行eclipse
./eclipse
sudo mv hadoop-eclipse-plugin-2.7.3.jar /usr/local/eclipse/plugins/
./eclispe //启动eclipse
修改配置文件 ./etc/hadoop/目录下
sudo mv mapred-site.xml.template mapred-site.xml
sudo vim mapred-site.xml
添加以下内容
hadoop的初始化与启动
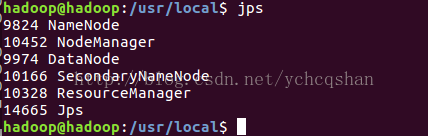
注意,如果DataNode没有启动,可以删除HDFS中的所有数据,然后重新格式化namenode
伪分布式实例
单机模式中,读取的是本地数据,伪分布式则是在Hdfs中的数据
安装eclipse
新开一个终端,
连接hadoop
关闭eclipse程序
将hadoop-eclipse-plugin-2.7.3.jar复制到eclipse下
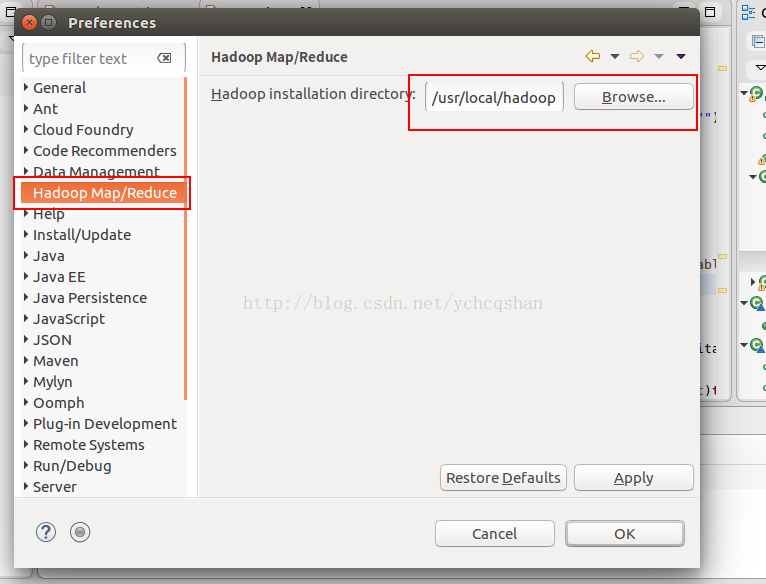
进行插件配置 : windows--preferences 选择 Hadoop Map/Reduce配置,添加hadoop的安装路径:/usr/local/hadoop
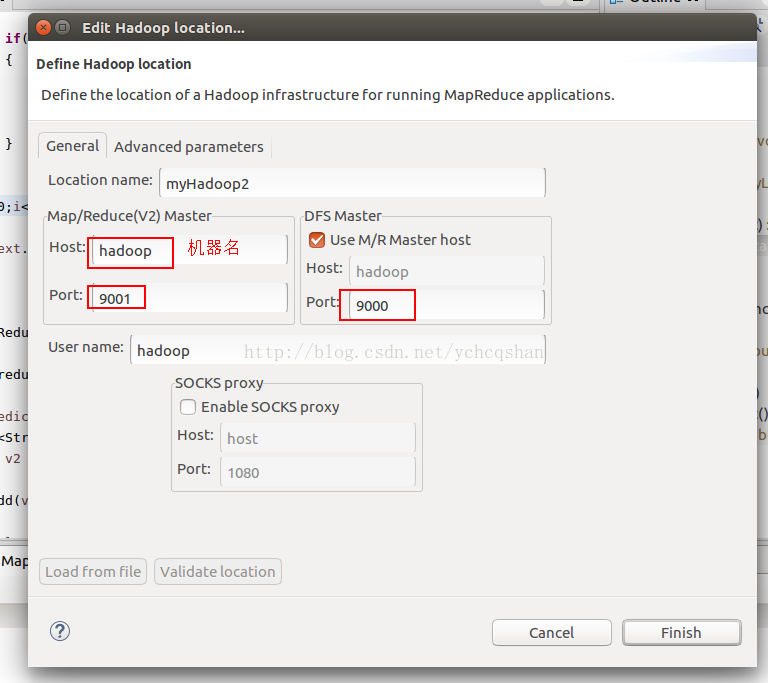
选择Map/Reduce Locations 视图: windows--perspective--open perspective--other--Map/Reduce
然后进行配置,如图

实例
新建Map/Reduce Project 程序
代码如下:
import java.io.IOException;
public class WordCount {
public static class TokenizerMapper
extends Mapper
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable
values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount
"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
7、相关问题
后续补充,请认真进行环境变量的配置
8、参考文献
Hadoop安装教程_单机/伪分布式配置_Hadoop2.8.0/Ubuntu16
Hadoop 安装教程 单机/伪分布式配置
hadoop环境搭建(伪分布式)
hadoop实战之eclipse开发环境搭建














 1963
1963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









