







背景
kafka是我项目用的最多的消息中间件,目前项目使用kafka存在些许问题,如重复消费、带宽瓶颈、部分分区消费不下来的异常场景。 其中重复消费问题有些让人头疼(reblance导致offset提交失败),这里会持续更新(基于官网+视频),研究kafka部分底层知识点,希望对我们代码设计和代码编写能力上有一定的提升。
后续会补上我们项目如何解决kafka遇到的一些常见问题。
概念
消息队列
我们都知道栈,先进后出,也知道队列,先进先出。老师在教学中两者都有一个容器做存储,数据结构书里记得该容器是一个数组(大家印象应该比较深刻)。 常用的消息队列我们都知道有ActiveMQ、RabbitMQ、RocketMQ乃至java自带的阻塞队列BlockingQueue,其中java自带的BlockingQueue是典型的数组做容器。
功能
消息队列是一个实时性很强的先进先出存储消息的容器,作为容器,容器有的功能它都有。 消息生产到容器,消费者根据本身消费能力取出消费…于是就有了以下功能
- 削峰
- 应用解耦
- 异步
消息的传递模式
-
点对点传递模式
生产者生产消息,消费者消费,两者互不影响,消费者消费成功后,删除消息队列的消息~
特点:每个消息只能被消费一次

-
发布-订阅模式
生产者生产消息到topic,0个或多个消费组订阅该topic,一个消息被消费多次(kafka基于不通的消费组)
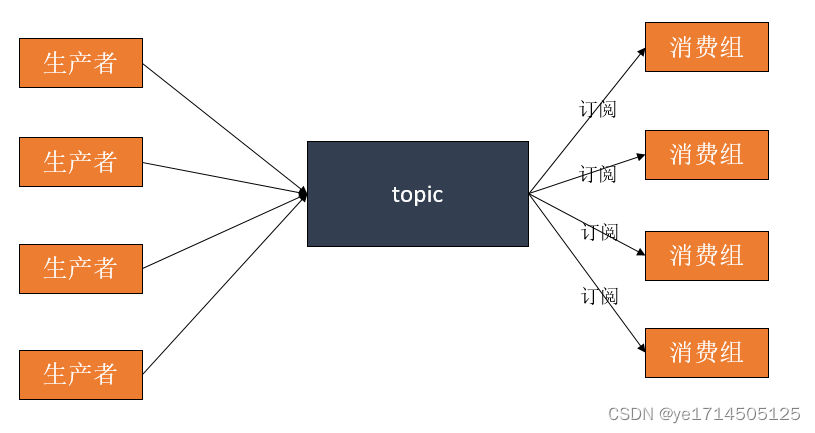
kafka概念理解
kafka是典型的发布订阅模式,这里举个例子帮我们了解kafka的基本概念。
例:我们网站是卖鞋子的
- 我想将用户搜索鞋子的尺码、品牌信息+客户信息保存下来,方便下次精准推送相关产品,如果每次搜索都落库,是不是很慢,好,我直接发送到kafka,微服务X定义消费组X-consumer订阅该topic消费(异步+削峰)。
- 客户跟客服聊天的内容,我这边要校验你们是否存在刷单的词汇,或其它敏感词汇,针对业务跟客户聊天的内容每次做检验时会影响交互时间的,此时,内容我发送到kafka,微服务Y定义消费组Y-consumer订阅该topic 消费(解耦)
以上1点和2点很明显,两个不大相关的功能,kafka分别建相应的topic(topic说白了就是区分业务的)。 假设1功能使用 A(topic),2使用使用 B(topic),X订阅A消费,Y订阅B消费,X和Y微服务都是消费者。 假设X微服务主机性能利用率不高,Y微服务主机性能超载,那X是不是可以再订阅B,添加Y的处理逻辑,帮忙分担消费的压力,此时X用Y的消费组就行(B的部分分区在X微服务消费了)。
假设Y微服务主机老是丢数据,可能内部逻辑处理有问题。此时我需要将Y消费的消息同步消费下来(拷贝一份,直接埋点日志)做对比,此时使用新的消费组Z去消费B 就行了。
主题(topic)
上面的例子,topic理解起来就很简单了,这里不再赘述
分区(partition)
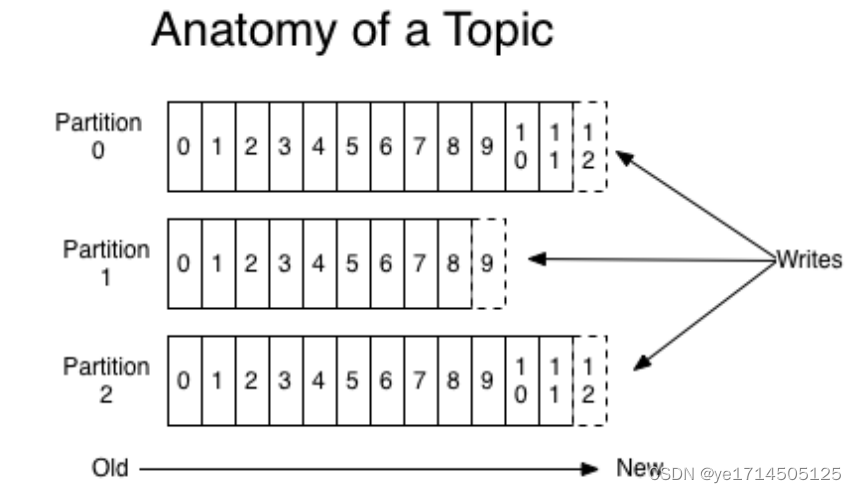
topic区分业务,partition区分数据存储的管道,两者结合决定了消息的存储的位置。分区是kafka非常重要的一个的一个概念,一个topic可以有多个分区,消息根据不同的策略发送到这些分区存储(轮询,hash,指定分区)。
- 问:消息如何保证被顺序消费呢?
多个分区下kafka是无法保证的,如果消息一定要严格按照顺序消费,topic定义一个分区即可,kafka可以保证同一个分区内的数据是顺序的。 - 问:kafka为什么有分区的概念?
提高并发处理,一个池子多个线程抢着消费,还不如多个池子分配给多个线程消费。
这里补充一点一个分区只能被一个消费线程消费,如果消费线程定义过多,会有部分线程是空跑状态,这里大家可以先想原因
提示:3多个线程消费同一个分区,会有一个并发问题,提交已消费的offset偏移量,大家自己品。 - 问:是不是分区越多越好?
分区定义最好是broker(kafka节点的整数倍),每个broker有相对均衡的分区,减少broker性能上的偏差。定义的大小根据消费组的消费线程来决定。 分区不是越多越好,下游消费能力不够,上游消费再多分区也是枉然的。
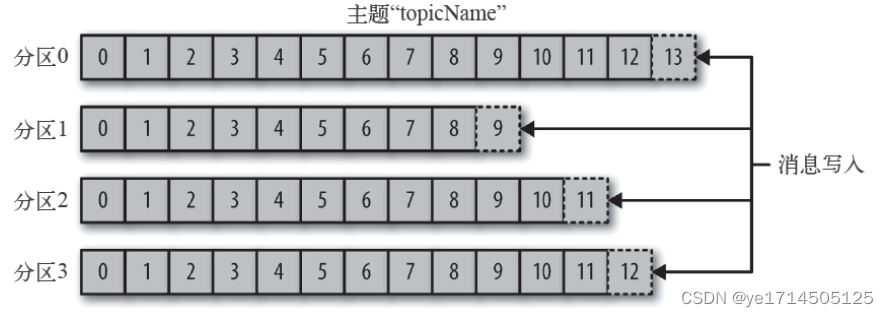
消费者
谈到消费者,这里必须谈到消费组,一个topic可以被多个消费组订阅,每个消费组可以有多个消费线程,一般来说消费线程和分区数尽量保持一致。
重要:一个分区只能被一个消费线程消费,一个消费线程可以消费多个分区,如果消费线程比分区多,导致部分线程属于空置状态。如消费线程比分区少,会导致一个线程消费多个分区的情况,因此尽量保证消费线程数和分区数一致。
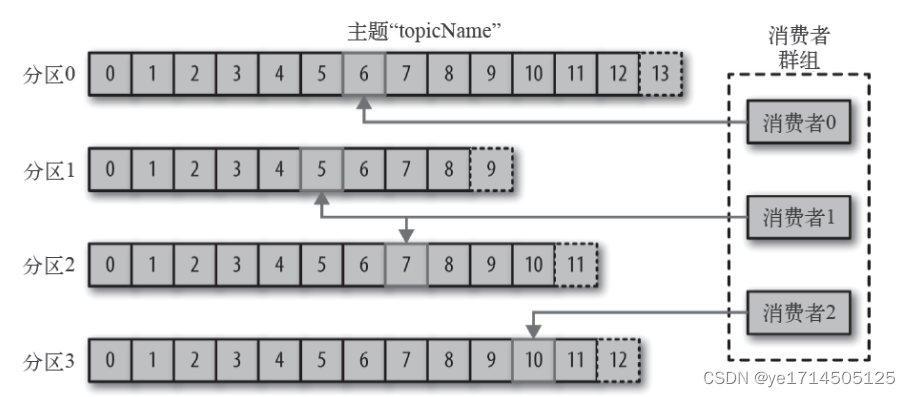
生产者
生产者创建消息,发送到kafka,一般情况下都是发送到一个特定topic,发送到的分区逻辑如下
- 默认情况下,消息数量count递增,并根据分区的大小数值取模,计算得出partition(轮询)。
- 业务指定往哪个分区发
- 业务可以埋点key,通过该key的hash,计算出partition,保证该key发送到的partition唯一。
例:收集某个主机的日志,主机IP作为key,那么该主机的日志只会往这个partition发送。
broker与partition之间的关系
一个独立的kafka服务器节点称为一个broker,broker接收生产者的消息,为它设置偏移量。一个kafka集群都有一个broker集群控制器,监控其他broker,并为broker分配分区。
分区也有首领,分区首领处理该分区的消息存储和消费逻辑,并同步该分区数据到其他broker,一旦该分区首领出现宕机情况,会选举其他broker节点的partition作为分区首领。
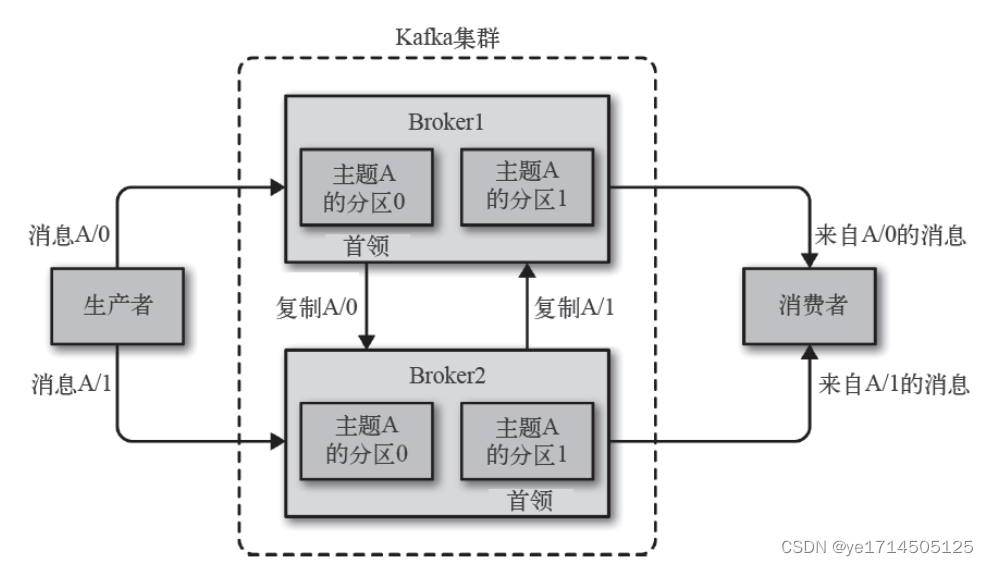
副本
kafka为保证一台乃至多台broker宕机情况下能正常提供服务,特此有了副本的概念,即数据备份。 但kafka的副本有些不同,分为首领副本和跟随者副本,为了保证⼀致性,所有⽣产者请求和消费者请求都会经过这个首领副本。 ⾸领以外的副本都是跟随者副本。跟随者副本不处理来⾃客户端的请求,它们唯⼀的任务就是从⾸领那⾥复制消息,保持与⾸领⼀致的状态。如果⾸领发⽣崩溃,其中的⼀个跟随者会被提升为新⾸领。
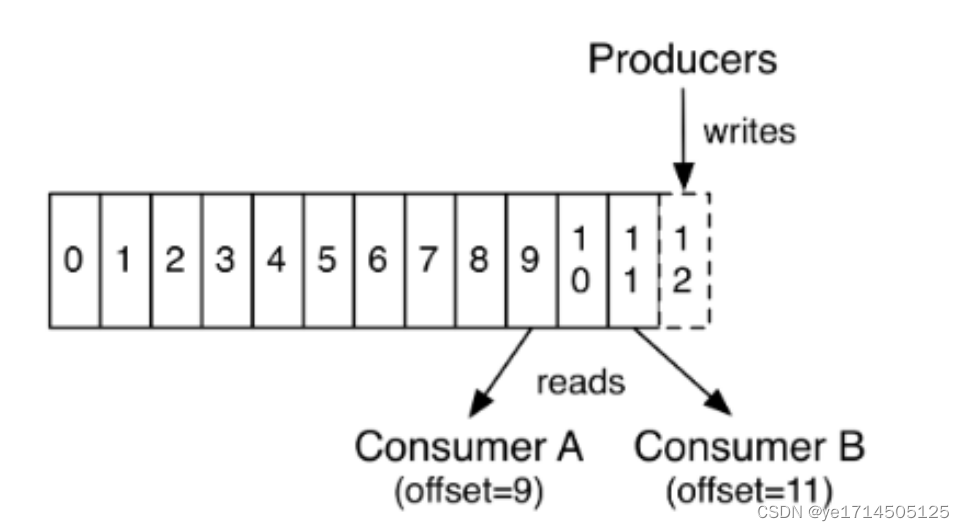
offset
偏移量,每个消息有自己唯一的偏移量,生产者创建消息,partition会给消息设置生产偏移量,也是该分区的最大偏移量。 消费者消费消息时,kafka会记录消费组已消费的offset,即消费偏移量。















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









