







 文章介绍了一种新的迁移学习方法GPPT,通过链路预测预训练GNN,利用提示函数将节点分类转化为链接预测,有效解决了GNN监督训练中目标差距问题,实验证明在多个基准数据集和应用中表现出色。
文章介绍了一种新的迁移学习方法GPPT,通过链路预测预训练GNN,利用提示函数将节点分类转化为链接预测,有效解决了GNN监督训练中目标差距问题,实验证明在多个基准数据集和应用中表现出色。
1 Introduction
尽管图神经网络(GNNs)的表示学习很有前途,但GNNs的监督训练需要从每个应用程序中获得大量的标记数据。一个有效的解决方案是在图中应用迁移学习:使用易于获取的信息来预训练GNN,并用少量标签对其进行微调以优化下游任务。虽然有很多工作正在从事这方面的研究,但还是没解决预训练模型与下游任务之间的缺口。这种显著的差距通常需要进行代价高昂的微调,以使预先训练的模型适应下游问题,这阻碍了对预训练中知识的有效启发,导致了糟糕的结果。
为了弥补这个问题,这篇文章提出了一种新的迁移学习范式来推广GNN,即Graph Pre-Training and Prompt Tuning (GPPT)。文章采用最简单的链路预测任务进行预训练,并提出提示函数,将独立节点转化为标记对,并重新制定与边缘预测相同的下游任务:节点分类。
2 Contribution
- 为了解决图神经网络在监督训练中的训练目标差距问题,作者引入了GPPT ( Graph Pre-training and Prompt Tuning) 范式,提高了图神经网络的性能和效率。
- 作者提出了一种 prompting function,将独立的节点转化为令牌对,通过任务令牌和结构令牌的组合重新将下游节点分类转化成了链接预测问题。这个设计有助于缩小预训练和下游任务之间的训练目标差距。
- 通过在八个基准数据集和两个下游应用上进行广泛的实验,文章得出了结论,表明GPPT在各种训练策略中表现最佳,包括监督学习、联合训练和传统的迁移学习。在少样本图分析问题中,GPPT平均提高了4.29%的性能,并将微调时间成本节省了4.32倍。
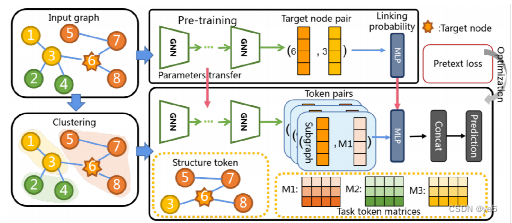
3 PRELIMINARY
本节介绍了图神经网络的原理、和预训练、微调的迁移学习方案的基本原理。
3.1 Graph Neural Networks

3.2 Pre-train and Fine-tune GNNs
有几项工作被提议构建自监督的预训练任务来预训练GNN。为了对内在结构知识进行编码,masked edge prediction 和contrastive learning是文献中最有效和最流行的预训练任务。
masked edge prediction计算节点对生成边缘的链接概率时, contrastive learning比较图实例对的相似性得分。
对于masked edge prediction,实现流程如下:
- 首先随机掩盖边,并且训练GNN去重构它们; G p r e = ( X , A p r e ) G^{pre} = (X, A^{pre}) Gpre=(X,Apre),随机采样一些边 ( i , j ) (i,j) (i,j),令 A i , j p r e = 0 A^{pre}_{i,j} = 0 Ai,jpre=0, 因此每个节点 v i v_{i} vi可以表示为 h i = f Θ ( G p r e , v i ) h_{i} = f_{\Theta}(G^{pre}, v_{i}) hi=fΘ(Gpre,vi)
- 预训练的任务是判断节点对之间是否连通;
- 预训练的任务是最小化以下函数

- 图数据领域的下游任务一般是局部节点分类任务。用于分类节点标签属性,且这些节点的ground truth 很难获得。在传统的“预训练、微调”迁移学习框架下,GNN被微调以优化以下损失:

4 GRAPH PROMPTING FRAMEWORK
首先,我们注意到GNN的参数𝜃优化为生成连接节点对的嵌入,而不是同一类的节点。如果断未连通的节点对属于同一类,则需要用许多epochs来调整预训练的模型以适应新问题。这种耗时的微调使得无法有效地使用预先训练的模型。在长期的训练过程中,预先培训的知识也将逐渐被过滤掉。
第二,考虑到新的projection head的参数𝜑,它们很难在初始阶段与预先训练的GNN相结合。从而无法达到预期的效果。
在这篇文章中,文章使用提示函数来弥补这两种任务的训练目标的差距,将下游任务重新表述,使其看起来就像预训练任务
Pre-train, Prompt, Fine-tune
文章中关于提示函数给出了以下定义:

节点分类下游任务
T
t
a
s
k
(
y
)
T_{task}(y)
Ttask(y)任务(𝑦)可以由等待分类的节点标签给定,而结构标记
T
s
r
t
(
y
)
T_{srt}(y)
Tsrt(y)可以由目标节点周围的子图以提供更多结构信息。给定token pair
[
T
t
a
s
k
(
y
)
,
T
s
r
t
(
y
)
]
[T_{task}(y),T_{srt}(y)]
[Ttask(y),Tsrt(y)],可以将这两者嵌入连续张量中,GNN的“预训练、提示、微调”的新学习范式由三个部分组成

4.2 Graph Prompting Function Design
Task Token Generation
任务令牌则是用于分类的标签,本文通过可扩展的聚类模块对输入的图数据进行聚类运算,从而获得每个类别对应的任务令牌。任务令牌可以被理解为添加到原始图中的类原型节点,其中通过查询每个类原型节点来执行节点分类任务。

Structure Token Generation
结构令牌可以被理解成通过注意力模块对每个节点的邻域信息进行聚合后,获得的该节点的表示。
据社交影响理论,靠近的节点往往具有相似的特征属性和类别模式。因此,
结构tokem
T
s
t
r
(
v
i
)
T_{str}(v_{i})
Tstr(vi)表示以节点
v
i
v_{i}
vi为中心的子图。在这里,我们利用一阶相邻节点,即最简单的子图,来表示
T
s
t
r
(
v
i
)
T_{str}(v_{i})
Tstr(vi),具体如何形成目标向量如下所示:

通过查询每个类原型节点生成令牌对,然后进行令牌对的相似度计算,便能够将图节点分类任务转化为图链接预测任务,从而弥合了前提任务和下游任务的差距。
5 EVALUATION
5.1 Experimental Setup

5.2 Performance Analysis
Q1:Compared with supervised training, joint optimization and pretraining baselines, how effective is GPPT to boost the node classification?
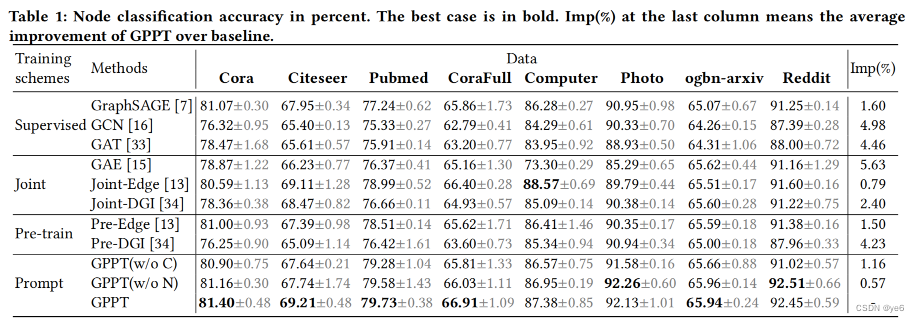
通过以上结果可以发现:
基于提示的学习方法通常在基准测试上获得最好的性能。
图的聚类和邻域结构是信息提示性令牌设计的关键。
GPPT即使在没有微调的情况下性能也比较好

GPPT的收敛速度最快
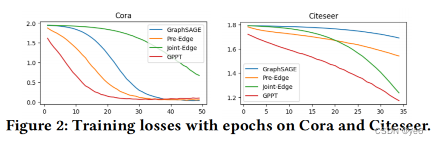
与传统的训练前方法相比,基于提示的学习范式甚至可以使预先训练后的GNN在不进行任何调整的情况下被转移
Conclusions
文章提出了GPPT,第一个针对GNN进行“预训练、提示、微调”的迁移学习范式。开发了提示函数来重新构建下游任务使其与预训练任务相似,旨在减少他们的训练目标差距。此外还设计了任务和结构token生成方法。提出了平均提示初始化和正交正则化方法来提高提示调优性能。大量的实验表明,GPPT的性能始终优于 在基准图上的传统训练范式,伴随着更好的调优效率和对下游任务的更好的适应性。在未来的工作中,将探索更具挑战性的知识图中进行提示函数的设计,并尝试元学习改进基于提示的调优。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









