







其实这个题目本身都还有点问题。汉语数字的表达方式何止一两种,而且还有很多不规范的称呼。所以,转换起来也是比较麻烦的。并且由于每个人的叫法不同,因此也不容易判定用户的输入是否合符常理和规范。这就只能靠大家去正确对待了。
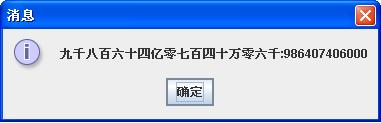
我的基本思路是这样的,比如说:九千八百六十四万三千二百一十一(98643211),首先,必须提取出该字符串中量级最大的字,在该字符串里,“万”是量级最大的,所以,每次都把量级从高到低提取出来。按照:“亿”,“万”,“千”,“百”,“十”的顺序,每次将字符串与对其对比。
因为是循环,所以,每次取到最大量级后就跳出该次循环,如上例:第一次,取到“万”字,跳出循环,然后以“万”字为分割字符,将字符串分割成两段(九千八百六十,三千二百一十一)。并且记住该次分割的量级,然后再把前半部分传递到另一个递归调用函数进行处理(先不讲这个函数),然后把后面一部分再次传递给该函数进行递归调用,而这次取量级将从该次量级以后的开始取。依次重复,直到程序结束。
那么,前半部分的字符串将如何处理?首先,我们照样进行量级查找,由于分割后的字符串要短得多,每次从最高量级找,找到后,分割字符串,并将量级前的数字返回。这里与上面函数不同的就是需要返回量级前的数字。而前一个函数返回的是整个字符串。一直递归到取出所有量级前的数字。每次将其值乘以量级后相加。最后再返回到第一个函数,再与上一次分割字符串的量级相乘。依次完成所有步骤:
所以,依上例,有:
每一次:九千八百六十四万三千二百一十一 分割成:九千八百六十四和三千二百一十一
下一步:将九千八百六十四传递给第二个递归函数,然后每次分割为:九千、八百、六十、四。每次分割完成后,都取得量级前的数字。即为:九、八、六、四
然后每次返回该数字与量级的乘积与上一次递归的和,最后递归完成时返回整个字符串(九千八百六十四)的值。
第一段字符串处理完成以后,接下来按照同样的方法(也就是第一个递归函数)处理剩下的字符串,依次类推,直到处理完所有字符串。
但这只是理论上的东西,实际运用中还有许多小的细节需要注意。比如说:输入:十九,十、一万零一等。只要大家多想一些,就能够处理大部分遇到的问题。当然,这种东西输入的时候也没有一个固定的语法可以检查。如果真要写个语法,估计也不是那么容易。测试的时候也只能按照我们常规的习惯去输入字符串,随便乱输入肯定会报错。并且还要在一定的范围内使用。
下面,我把自己写的一点代码帖上来,没有处理异常,也没有写检查用户输入的语法,但基本上可以实现十万亿以内的数值转换,只要用户不刻意地乱输入:
- public class work {
- //全局数组,存储单位量级
- String [] strCHup ={"亿",
- "万","千","百","十"};
- //通过两次递归调用实现分割.
- public long excuteCharge(String str,int start)
- {
- //存储量级单位
- long midNumber=0;
- //存储是否可以找到最高量级
- int bre=-1;
- //找到后根据索引实行字符串分割
- int split = 0;
- //通过循环查找最高量级
- for(int i=start;i<strCHup.length;i++)
- {
- bre = str.indexOf(strCHup[i]);
- if(bre!=-1)
- {
- split=i;
- switch(i)
- {
- case 0:
- midNumber=100000000;
- break;
- case 1:
- midNumber=10000;
- break;
- case 2:
- midNumber=1000;
- break;
- case 3:
- midNumber=100;
- break;
- case 4:
- midNumber=10;
- break;
- }
- //只需要找到最高量级,找到即刻跳出循环.
- break;
- }
- }
- //如果没有找到量级数.说明该数很小,直接调用add()返回该值.
- if(bre==-1)
- {
- return add(str);
- }
- //否则要根据量级进行字符串侵害和返回侵害前部分的值
- else
- {
- //如果大型整数,如:十万 等.因为后面不需要再分割
- if(str.length()==bre+1)
- {
- //对于单个量级的值,如:十、百、千、万等。不需要裁减字符串。直接返回量级即可
- if(str.length()==1)
- {
- return midNumber;
- }
- else
- {
- return add(str.substring(0, str.length()-1))*midNumber;
- }
- }
- //对于只有两位数的.如:十九.直接调用add()返回值即可.不能在此处递归.
- else if(str.length()==bre+2){
- return add(str);
- }
- //其他情况则取值和分割.然后再递归调用.
- else
- {
- String[] strPart = str.split(strCHup[split]);
- return (add(strPart[0])*midNumber)+excuteCharge(strPart[1],0);
- }
- }
- }
- public long add(String str)
- {
- //存储strCHup里具体汉字的数字值
- long mid=0;
- //存储strNumup里具体汉字的数字值
- int number=0;
- //存储传入字符串的最高级别单位在strCHup数组里的索引.
- int num=-1;
- for(int i=0;i<strCHup.length;i++)
- {
- //取得量级在字符串中的索引.
- num=str.indexOf(strCHup[i]);
- //定义char型变量,存储每个汉字.便于后面比较
- char ch=' ';
- if(num!=-1)
- {
- switch(i)
- {
- case 0:
- mid=100000000;
- break;
- case 1:
- mid=10000;
- break;
- case 2:
- mid=1000;
- break;
- case 3:
- mid=100;
- break;
- case 4:
- mid=10;
- break;
- }
- //如果以"十"开关的,直接定义number的值.因为在上面能够找到它的量级.
- if((str.toCharArray())[0]=='十')
- {
- number=1;
- }
- //否则,取得量级前的数字进行比较,再确定number的值
- else
- {
- ch = (str.toCharArray())[num-1];
- }
- //
- }
- //循环结束
- //
- //如果整个字符串就一个字,那么就应该取该值进行比较.而不是再取量级前的数字.
- if(str.length()==1){
- ch = (str.toCharArray())[0];
- }
- //防止几万零几这样的数.
- else if((str.length()==2)&&((str.toCharArray())[0]=='零'))
- {
- ch = (str.toCharArray())[1];
- }
- switch(ch)
- {
- case '零':
- number=0;
- break;
- case '一':
- number=1;
- break;
- case '二':
- number=2;
- break;
- case '三':
- number=3;
- break;
- case '四':
- number=4;
- break;
- case '五':
- number=5;
- break;
- case '六':
- number=6;
- break;
- case '七':
- number=7;
- break;
- case '八':
- number=8;
- break;
- case '九':
- number=9;
- break;
- }
- /
- if(num!=-1)
- {
- break;
- }
- }
- if(num==-1)
- {
- return number;
- }
- String strLeft = str.substring(num+1);
- return (number*mid)+add(strLeft);
- }
- }


















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









