









阅读目录(Content)
1 什么是检查点
数据修改操作 都是在 内存中的数据页进行修改,每次修改后并没有立即把这些页面写入磁盘,而是等到一定时期,数据库引擎对数据库发起 检查点命令,这时,该命令就会创建一个已知的正常点,把当前所有在内存中已修改的页面(脏页)即事务日志信息从内存中写入到磁盘,并且记录下有关事务日志的信息。之后如果数据库意外关闭或者崩溃,那么在恢复的过程中,数据库引擎就不需要恢复所有事务日志,而是从 该检查点 开始应用日志中所做的修改。
2 检查点类型
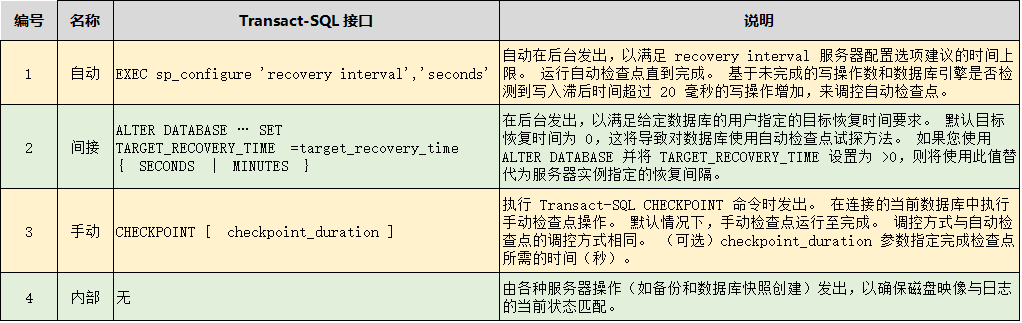
3 检查点的参数影响
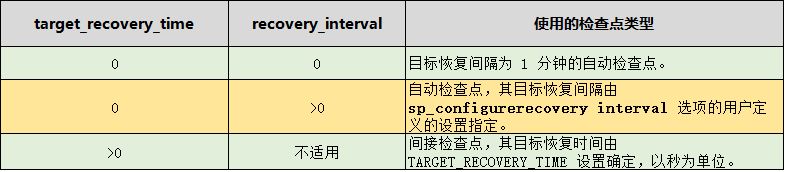
recovery interval 针对于整个数据库实例,默认为0,参数定义的时候,分为 0 跟 >0两种情况。
target_recovery_time 针对于某个数据库,默认为0,参数定义的时候,也分为0 跟 >0 两种情况。
3.1 自动检查点
3.1.1 什么是自动检查点
当 target_recovery_time 为0时,检查点类型为自动检查点。自动检查点的生成频率,取决于数据库 recovery_interval 配置值,可通过管理视图 sys.sysconfigures查看配置值。
recovery_interval的配置值 指定 服务器实例在系统启动期间 从最近一个检查点之后应用日志来恢复数据库 的最长时间,也就是当 目标恢复间隔为1分钟时,那么数据库就会检查,那么数据库就会估算,在 DB重启恢复期间,1分钟内能够处理的最大日志记录数,如果从最近一个检查点之后到当前的日志记录数达到了这个 值,那么数据库就会自动发起一个检查点命令。所以,自动检查点之间的 命令执行时间并非是固定的,在业务高峰期,可能比较密集,而在业务的低峰期,则相对较长时间才允许一次检查点命令。
这里需要注意三个地方:
- 并非说设置了 recovery_interval 后,数据库的恢复时间就一定是在 recovery_interval 时间内,这个值只是给数据库判断 检查点命令的执行时间使用,而非 明确为 数据库的恢复时间。因为在系统崩溃后,恢复数据库所需的时间,主要取决于重做崩溃时的脏页所需的 IO 量。
- 简单恢复模式下,在没有延迟日志截断的亲开沟下,自动检查点都会阶段日志中没有使用的部分。
- Also, under the simple recovery model, an automatic checkpoint is also queued if the log becomes 70 percent full. 这句话有歧义?是否是理解为,在简单模式下,如果数据库的日志填充不足70%,那么及时到了checkpoint的自动执行时间,也不会执行,而是等到 日志填充大于 70%才执行该指令?
3.1.2 recovery interval 设置
对于OLTP系统(少大事务跟少开始事务后迟迟没有提交事务的情况),recovery interval 是确定恢复时间的主要因素。 但是,recovery interval 选项不影响撤消长时间运行的事务所需的时间。比如,设置的recovery interval为0,则是默认为 1分钟的恢复间隔,但是修改数据执行了2个小时,那么,实际的恢复将长于 recovery interval。
通常情况下,默认值是最佳。但是,如果出现以下情况来,则可通过修改配置值来提高性能(建议逐渐增大该值来评估,而非突然修改较大值):
- 在长时间运行的大事务没有回滚时,数据库恢复所耗费的时间通常都超过了1分钟;
- 检查点过于频繁,内存数据页写入到磁盘影响了数据库的IO性能
修改recovery interval配置如下:
[ ](javascript:void(0); “复制代码”)
](javascript:void(0); “复制代码”)
1 #查看数据库 recovery interval配置值
2 select * from sys.sysconfigures where comment like’%recovery%interval%’
3
4 #开启高级选项
5 EXEC sp_configure ‘show advanced options’, 1;
6 GO
7 RECONFIGURE ; 8 GO
9
10 #配置 recovery interval 为两分钟 11 EXEC sp_configure ‘recovery interval’, 2 ; 12 GO
13 RECONFIGURE; 14 GO
15
16 #关闭高级选项 17 EXEC sp_configure ‘show advanced options’, 0; 18 GO
19 RECONFIGURE ; 20 GO
[](javascript:void(0); “复制代码”)
3.2 间接检查点
SQL SERVER 2012开始引入的,它区别与自动检查点,在于它们生效的范围,自动检查点是对整个数据库实例生效,而间接检查点只对指定的数据库生效。
它的优点:
-
间接检查点可以减少整体数据库恢复时间。
-
间接检查点使您可以通过控制 REDO 期间随机 I/O 的开销来可靠控制数据库恢复时间。 这使服务器实例不超过给定数据库的恢复时间上限(长时间运行的事务导致过多 UNDO 时间时除外)。
-
间接检查点通过在后台不断地将脏页写入磁盘来减小与检查点有关的 I/O 蜂值。
它的缺点:
- 对于OLTP系统,配置间接检查点后,会使用后台的写入线程,从而增加服务器实例的总写入负荷,可能造成性能下降
3.3 手动检查点
通常,我们很少需要手动执行checkpoint指令,checkpoint的语法为 :CHECKPOINT [ checkpoint_duration ],checkpoint_duration 为完成该checkppoint所需的秒数。
正常情况下,我们不会指定checkpoint_duration 该值,而是用数据库自动调整的检查点持续时间,以降低对数据库的性能影响。
因为数据库在执行checkpoint的时候,脏页数、修改数据的活动事务以及指定实际持续时间checkpoint_duration,都会影响资源的分配情况,假设指定了checkpoint_duration的值为50s,而正常情况下完成这个操作需要150s,那么这个时候,数据库为了满足指定的checkpoint_duration 50s,就会比正常情况下,分配更多的资源给该指令运行,那么就会影响到正常情况下的其他操作对资源的利用了。
3.4 内部检查点(摘自MSDN)
内部检查点由各种服务器组件生成,以确保磁盘映像与日志的当前状态匹配。 生成内部检查点以响应下列事件:
-
已经使用 ALTER DATABASE 添加或删除了数据库文件。
-
进行了数据库备份。
-
创建了数据库快照,不管 DBCC CHECK 是显式还是内部执行。
-
执行了需要关闭数据库的活动。 例如,AUTO_CLOSE 设置为 ON 并且关闭了数据库的最后一个用户连接,或者执行了需要重新启动数据库的数据库选项更改。
-
通过停止 SQL Server (MSSQLSERVER) 服务停止了 SQL Server 实例。 任一操作都会在 SQL Server 实例的每个数据库中生成一个检查点。
使 SQL Server 故障转移群集实例 (FCI) 脱机。















 1080
1080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









