







B-tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。按照翻译,B 通常认为是Balance的简称.这个数据结构一般用于数据库的索引,综合效率较高。
B-tree中,每个结点包含:
1、本结点所含关键字的个数;
2、指向父结点的指针;
3、关键字;
4、指向子结点的指针;
B-tree是一种多路搜索树(并不是二叉的),对于一棵M阶树:
1.定义任意非叶子结点最多只有M个孩子;且M>2;
2.根结点的孩子数为[2, M],除非根结点为叶子节点;
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.非叶子结点的关键字个数=指向儿子的指针个数-1;
5. 与3相应,每个非叶子结点存放至少M/2-1(取上整)和至多M-1个关键字;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
例如:(M=3)
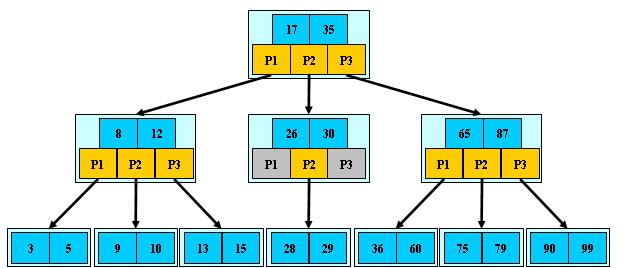
B-tree有以下特性:
1、关键字集合分布在整棵树中;
2、任何一个关键字出现且只出现在一个结点中;
3、搜索有可能在非叶子结点结束;
4、其搜索性能等价于在关键字全集内做一次二分查找;
5、自动层次控制;


由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最低搜索性能为:
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并。
鉴于B-tree具有良好的定位特性,其常被用于对检索时间要求苛刻的场合,例如:
1、B-tree索引是数据库中存取和查找文件(称为记录或键值)的一种方法。
2、硬盘中的结点也是B-tree结构的。与内存相比,硬盘必须花成倍的时间来存取一个数据元素,这是因为硬盘的机械部件读写数据的速度远远赶不上纯电子媒体的内存。与一个结点两个分支的二元树相比,B-tree利用多个分支(称为子树)的结点,减少获取记录时所经历的结点数,从而达到节省存取时间的目的。
在大多数系统中,B-树上的算法执行时间主要由读、写磁盘的次数来决定,每次读写尽可能多的信息可提高算法得执行速度。
B-树中的结点的规模一般是一个磁盘页,而结点中所包含的关键字及其孩子的数目取决于磁盘页的大小。
注意:
①对于磁盘上一棵较大的B-树,通常每个结点拥有的孩子数目(即结点的度数)m为50至2000不等
②一棵度为m的B-树称为m阶B-树。
③选取较大的结点度数可降低树的高度,以及减少查找任意关键字所需的磁盘访问次数。
下图给出了一棵高度为3的1001阶B-树。

说明:
①每个结点包含1000个关键字,故在第三层上有100多万个叶结点,这些叶节点可容纳10亿多个关键字。
②图中各结点内的数字表示关键字的数目。
③通常根结点可始终置于主存中,因此在这棵B-树中查找任一关键字至多只需二次访问外存。
B-树的存储结构
#define Max l000 //结点中关键字的最大数目:Max=m-1,m是B-树的阶
#define Min 500 //非根结点中关键字的最小数目:Min=┌m/2┐-1
typedef int KeyType; //KeyType应由用户定义
typedef struct node{ //结点定义中省略了指向关键字代表的记录的指针
int keynum; //结点中当前拥有的关键字的个数,keynum《Max
KeyType key[Max+1]; //关键字向量为key[1..keynum],key[0]不用。
struct node *parent; //指向双亲结点
struct node *son[Max+1];//孩子指针向量为son[0..keynum]
}BTreeNode;
typedef BTreeNode *BTree;
注意:
为简单起见,以上说明省略了辅助信息域。在实用中,与每个关键字存储在一起的不是相关的辅助信息域,而是一个指向另一磁盘页的指针。磁盘页中包含有该关键字所代表的记录,而相关的辅助信息正是存储在此记录中。
有的B-树(如第10章介绍的B+树)是将所有辅助信息都存于叶结点中,而内部结点(不妨将根亦看作是内部结点)中只存放关键字和指向孩子结点的指针,无须存储指向辅助信息的指针,这样使内部结点的度数尽可能最大化。
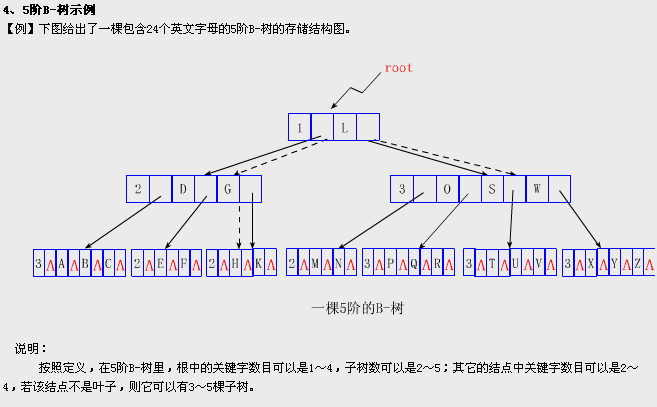
B-树上的基本运算
1、B-树的查找
(1)B-树的查找方法
在B-树中查找给定关键字的方法类似于二叉排序树上的查找。不同的是在每个结点上确定向下查找的路径不一定是二路而是keynum+1路的。
对结点内的存放有序关键字序列的向量key[l..keynum] 用顺序查找或折半查找方法查找。若在某结点内找到待查的关键字K,则返回该结点的地址及K在key[1..keynum]中的位置;否则,确定K在某个key[i]和key[i+1]之间结点后,从磁盘中读son[i]所指的结点继续查找……。直到在某结点中查找成功;或直至找到叶结点且叶结点中的查找仍不成功时,查找过程失败。
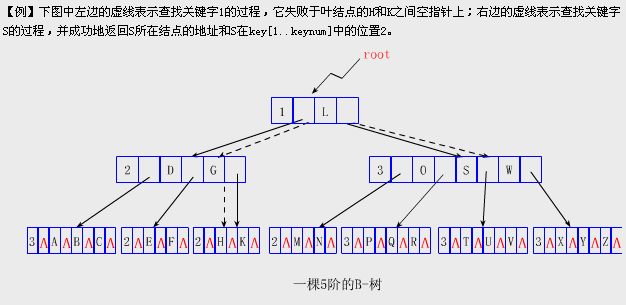
【例】下图中左边的虚线表示查找关键字1的过程,它失败于叶结点的H和K之间空指针上;右边的虚线表示查找关键字S的过程,并成功地返回S所在结点的地址和S在key[1..keynum]中的位置2。
(2)B-树的查找算法
BTreeNode *SearchBTree(BTree T,KeyType K,int *pos)
{ //在B-树T中查找关键字K,成功时返回找到的结点的地址及K在其中的位置*pos
//失败则返回NULL,且*pos无定义
int i;
T→key[0]=k; //设哨兵.下面用顺序查找key[1..keynum]
for(i=T->keynum;K<t->key[i];i--); //从后向前找第1个小于等于K的关键字
if(i>0 && T->key[i]==1){ //查找成功,返回T及i
*pos=i;
return T;
} //结点内查找失败,但T->key[i]<K<T->key[i+1],下一个查找的结点应为
//son[i]
if(!T->son[i]) //*T为叶子,在叶子中仍未找到K,则整个查找过程失败
return NULL;
//查找插入关键字的位置,则应令*pos=i,并返回T,见后面的插入操作
DiskRead(T->son[i]); //在磁盘上读人下一查找的树结点到内存中
return SearchBTree(T->Son[i],k,pos); //递归地继续查找于树T->son[i]
}
(3)查找操作的时间开销
B-树上的查找有两个基本步骤:
①在B-树中查找结点,该查找涉及读盘DiskRead操作,属外查找;
②在结点内查找,该查找属内查找。
查找操作的时间为:
①外查找的读盘次数不超过树高h,故其时间是O(h);
②内查找中,每个结点内的关键字数目keynum<m(m是B-树的阶数),故其时间为O(nh)。
注意:
①实际上外查找时间可能远远大于内查找时间。
②B-树作为数据库文件时,打开文件之后就必须将根结点读人内存,而直至文件关闭之前,此根一直驻留在内存中,故查找时可以不计读入根结点的时间。
B树的插入、删除操作
-
树中每个结点含有最多含有m个孩子,即m满足:ceil(m/2)<= m<=m。
-
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
-
若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
-
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
-
每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 除根结点之外的结点的关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1(叶子结点也必须满足此条关于关键字数的性质,根结点除外)。
ok,下面咱们以一棵5阶(m=5,即除根结点和叶子结点之外的内结点最多5个孩子,最少3个孩子)B树实例进行讲解(如下图所示):
备注:关键字数(2-4个)针对--非根结点(包括叶子结点在内),孩子数(3-5个)--针对根结点和叶子结点之外的内结点。当然,根结点是必须至少有2个孩子的,不然就成直线型搜索树了。
下图中关键字为大写字母,顺序为字母升序。
结点定义如下:
typedef struct{
int Count; // 当前节点中关键元素数目
ItemType Key[4]; // 存储关键字元素的数组
long Branch[5]; // 伪指针数组,(记录数目)方便判断合并和分裂的情况
} NodeType;
插入(insert)操作
插入一个元素时,首先在B树中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素,注意:如果叶子结点空间足够,这里需要向右移动该叶子结点中大于新插入关键字的元素,如果空间满了以致没有足够的空间去添加新的元素,则将该结点进行“分裂”,将一半数量的关键字元素分裂到新的其相邻右结点中,中间关键字元素上移到父结点中(当然,如果父结点空间满了,也同样需要“分裂”操作),而且当结点中关键元素向右移动了,相关的指针也需要向右移。如果在根结点插入新元素,空间满了,则进行分裂操作,这样原来的根结点中的中间关键字元素向上移动到新的根结点中,因此导致树的高度增加一层。
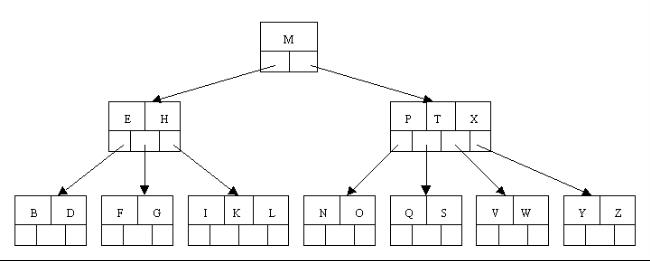
1、咱们通过一个实例来逐步讲解下。插入以下字符字母到一棵空的B 树中(非根结点关键字数小了(小于2个)就合并,大了(超过4个)就分裂):C N G A H E K Q M F W L T Z D P R X Y S,首先,结点空间足够,4个字母插入相同的结点中,如下图:
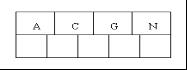
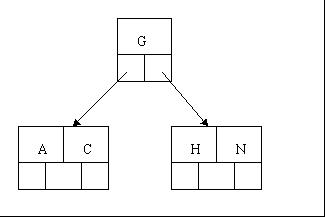
2、当咱们试着插入H时,结点发现空间不够,以致将其分裂成2个结点,移动中间元素G上移到新的根结点中,在实现过程中,咱们把A和C留在当前结点中,而H和N放置新的其右邻居结点中。如下图:
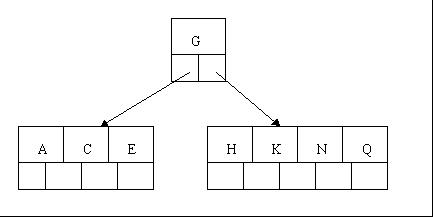
3、当咱们插入E,K,Q时,不需要任何分裂操作
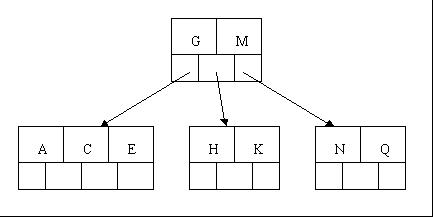
4、插入M需要一次分裂,注意M恰好是中间关键字元素,以致向上移到父节点中
5、插入F,W,L,T不需要任何分裂操作
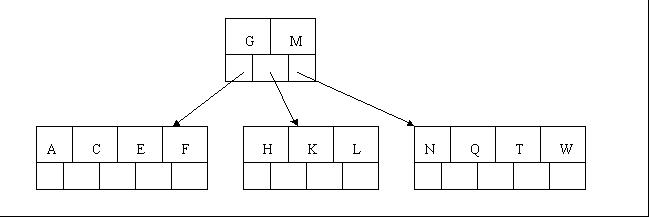
6、插入Z时,最右的叶子结点空间满了,需要进行分裂操作,中间元素T上移到父节点中,注意通过上移中间元素,树最终还是保持平衡,分裂结果的结点存在2个关键字元素。

7、插入D时,导致最左边的叶子结点被分裂,D恰好也是中间元素,上移到父节点中,然后字母P,R,X,Y陆续插入不需要任何分裂操作(别忘了,树中至多5个孩子)。
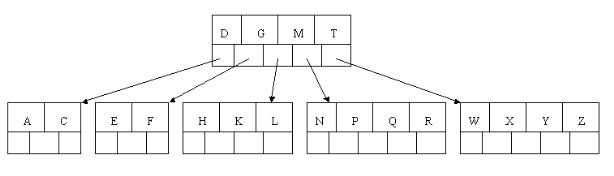
8、最后,当插入S时,含有N,P,Q,R的结点需要分裂,把中间元素Q上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间元素M上移到新形成的根结点中,注意以前在父节点中的第三个指针在修改后包括D和G节点中。这样具体插入操作的完成,下面介绍删除操作,删除操作相对于插入操作要考虑的情况多点。
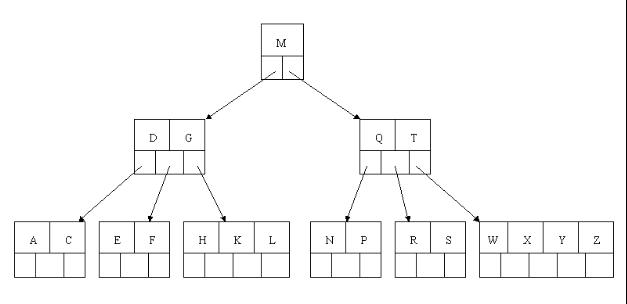
删除(delete)操作
首先查找B树中需删除的元素,如果该元素在B树中存在,则将该元素在其结点中进行删除,如果删除该元素后,首先判断该元素是否有左右孩子结点,如果有,则上移孩子结点中的某相近元素到父节点中,然后是移动之后的情况;如果没有,直接删除后,移动之后的情况。
删除元素,移动相应元素之后,如果某结点中元素数目(即关键字数)小于ceil(m/2)-1,则需要看其某相邻兄弟结点是否丰满(结点中元素个数大于ceil(m/2)-1)(还记得第一节中关于B树的第5个特性中的c点么?: c)除根结点之外的结点(包括叶子结点)的关键字的个数n必须满足: (ceil(m / 2)-1)<= n <= m-1。m表示最多含有m个孩子,n表示关键字数。在本小节中举的一颗B树的示例中,关键字数n满足:2<=n<=4),如果丰满,则向父节点借一个元素来满足条件;如果其相邻兄弟都刚脱贫,即借了之后其结点数目小于ceil(m/2)-1,则该结点与其相邻的某一兄弟结点进行“合并”成一个结点,以此来满足条件。那咱们通过下面实例来详细了解吧。
以上述插入操作构造的一棵5阶B树(树中最多含有m(m=5)个孩子,因此关键字数最小为ceil(m / 2)-1=2。还是这句话,关键字数小了(小于2个)就合并,大了(超过4个)就分裂)为例,依次删除H,T,R,E。
1、首先删除元素H,当然首先查找H,H在一个叶子结点中,且该叶子结点元素数目3大于最小元素数目ceil(m/2)-1=2,则操作很简单,咱们只需要移动K至原来H的位置,移动L至K的位置(也就是结点中删除元素后面的元素向前移动)
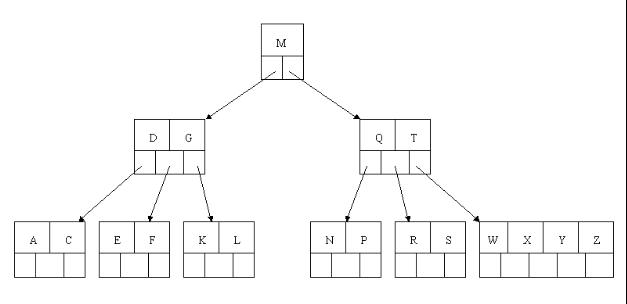
2、下一步,删除T,因为T没有在叶子结点中,而是在中间结点中找到,咱们发现他的继承者W(字母升序的下个元素),将W上移到T的位置,然后将原包含W的孩子结点中的W进行删除,这里恰好删除W后,该孩子结点中元素个数大于2,无需进行合并操作。
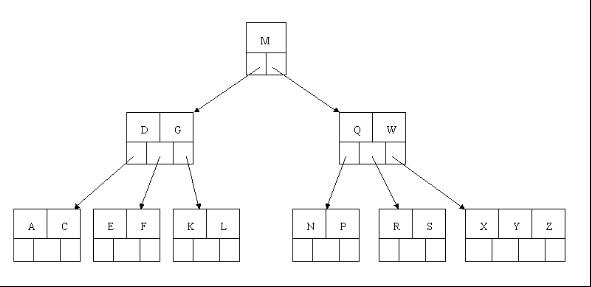
3、下一步删除R,R在叶子结点中,但是该结点中元素数目为2,删除导致只有1个元素,已经小于最小元素数目ceil(5/2)-1=2,而由前面我们已经知道:如果其某个相邻兄弟结点中比较丰满(元素个数大于ceil(5/2)-1=2),则可以向父结点借一个元素,然后将最丰满的相邻兄弟结点中上移最后或最前一个元素到父节点中(有没有看到红黑树中左旋操作的影子?),在这个实例中,右相邻兄弟结点中比较丰满(3个元素大于2),所以先向父节点借一个元素W下移到该叶子结点中,代替原来S的位置,S前移;然后X在相邻右兄弟结点中上移到父结点中,最后在相邻右兄弟结点中删除X,后面元素前移。

4、最后一步删除E, 删除后会导致很多问题,因为E所在的结点数目刚好达标,刚好满足最小元素个数(ceil(5/2)-1=2),而相邻的兄弟结点也是同样的情况,删除一个元素都不能满足条件,所以需要该节点与某相邻兄弟结点进行合并操作;首先移动父结点中的元素(该元素在两个需要合并的两个结点元素之间)下移到其子结点中,然后将这两个结点进行合并成一个结点。所以在该实例中,咱们首先将父节点中的元素D下移到已经删除E而只有F的结点中,然后将含有D和F的结点和含有A,C的相邻兄弟结点进行合并成一个结点。
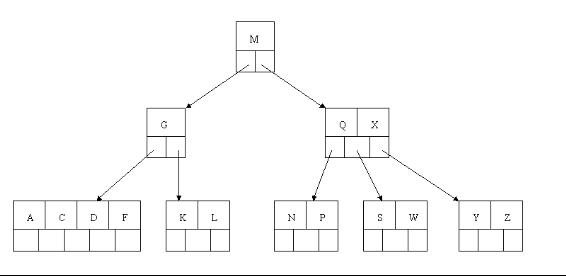
5、也许你认为这样删除操作已经结束了,其实不然,在看看上图,对于这种特殊情况,你立即会发现父节点只包含一个元素G,没达标(因为非根节点包括叶子结点的关键字数n必须满足于2=<n<=4,而此处的n=1),这是不能够接受的。如果这个问题结点的相邻兄弟比较丰满,则可以向父结点借一个元素。假设这时右兄弟结点(含有Q,X)有一个以上的元素(Q右边还有元素),然后咱们将M下移到元素很少的子结点中,将Q上移到M的位置,这时,Q的左子树将变成M的右子树,也就是含有N,P结点被依附在M的右指针上。所以在这个实例中,咱们没有办法去借一个元素,只能与兄弟结点进行合并成一个结点,而根结点中的唯一元素M下移到子结点,这样,树的高度减少一层。

为了进一步详细讨论删除的情况,再举另外一个实例:
这里是一棵不同的5序B树,那咱们试着删除C
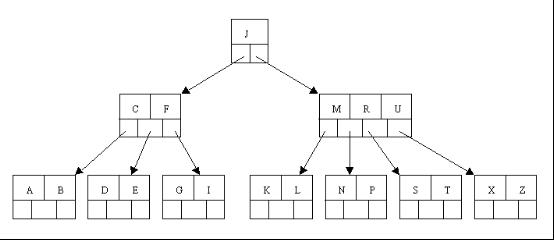
于是将删除元素C的右子结点中的D元素上移到C的位置,但是出现上移元素后,只有一个元素的结点的情况。
又因为含有E的结点,其相邻兄弟结点才刚脱贫(最少元素个数为2),不可能向父节点借元素,所以只能进行合并操作,于是这里将含有A,B的左兄弟结点和含有E的结点进行合并成一个结点。

这样又出现只含有一个元素F结点的情况,这时,其相邻的兄弟结点是丰满的(元素个数为3>最小元素个数2),这样就可以想父结点借元素了,把父结点中的J下移到该结点中,相应的如果结点中J后有元素则前移,然后相邻兄弟结点中的第一个元素(或者最后一个元素)上移到父节点中,后面的元素(或者前面的元素)前移(或者后移);注意含有K,L的结点以前依附在M的左边,现在变为依附在J的右边。这样每个结点都满足B树结构性质。
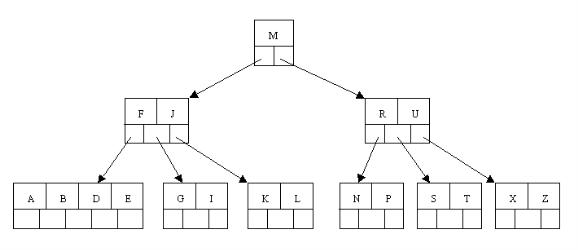
从以上操作可看出:除根结点之外的结点(包括叶子结点)的关键字的个数n满足:(ceil(m / 2)-1)<= n <= m-1,即2<=n<=4。这也佐证了咱们之前的观点。删除操作完。















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









