







刚开始接触scrapy,乍那么一看,这都是些什么鬼,感觉好难。。。。。。
学习历程大概是这样的:
1.先百度了scrapy的官方文档,scrapy官方文档,早就安装了scrapy,cmd->python->import scrapy的时候是很正常的,不过在pycharm中导入一直都有红杠杠的。。。。不得不又卸了重新装。在这里特别要注意scrapy的s的大小写。pip安装的时候是大写,导入模块的时候是小写。
2.然后就是创建工程。
scrapy crawl project-name# 制作爬虫(Spider):在spider文件夹中建立.py文件制作爬虫开始爬取网页
# 明确目标(Items):明确你想要抓取的目标
# 存储内容(Pipeline):设计管道存储爬取内容
3.先编写爬虫
首先,要爬取的网页是http://heart.39.net/zhlm/bljd/xzb/index.html
(一个灰常简单的网页,我怎么感觉不到,~~~~(>_<)~~~~)
爬取文章的标题和内容,而内容都在新的链接里。
4.items文件
import scrapy
from scrapy import Item,Field
class HeartdiseaseItem(scrapy.Item):
#网页标题
title=scrapy.Field()
#内容链接
url=scrapy.Field()
#内容描述
content=scrapy.Field()

开始写的时候在spider里面创建的是heartDisease.py。然后fromheartDisease.items import HeartdiseaseItem 的时候就会报错。因为会就近的搜索,然后就会找到heartDisease.py,但是里面没有items。我想导入的是文件夹heartDisease里面的items.py里的HeartdiseaseItem,改了名字后才导入成功。
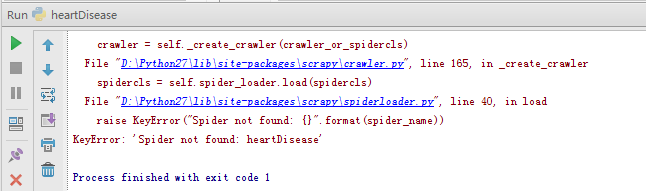
6.运行spider
开始写了简单的代码,只会在cmd中输入spider crawl heartDisease 。heartDisease是自己定义的名字,运行时要保持一致,name是必须的。
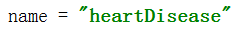
也可以编写一个main.py文件,在里面输入运行的命令。
#coding=utf-8 from scrapy import cmdline cmdline.execute("scrapy crawl heartDisease".split())
7.刚开始写的部分代码
这是获取初始网页内部链接里的内容。
xpath的用法:xpath简介。要注意“//”和“/”的用法,一开始小某还用错了呢。def parseContent(self,response): selector1=Selector(response) title=selector1.xpath('//title/text()').extract() item=heartDisease() item['title']=selector1.xpath('//title/text()').extract()[0] item['content'] = selector1.xpath('//div[@class="art_con"]/p/text()').extract() item['url'] = response.url yield item
8.将获取的数据存储到本地文件中。
官方文档中有写,不过没看懂。得亏旁边有大神。
在settings.py文件中配置内容
其中,“file///”是固定模式,在其后面加路径即可。BOT_NAME = 'heartDisease' USER_AGENT='Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36' FEED_URI=u'file///D:/Python test/heartDisease/DATA1.csv' FEED_FORMAT='CSV' SPIDER_MODULES = ['heartDisease.spiders'] NEWSPIDER_MODULE = 'heartDisease.spiders'
9.完整的代码
在写parse函数里的for循环时一直出错,要么是列表超出范围,要么就是item_1什么的丢失。不过最后还是改对了。# coding:utf-8 from scrapy.spiders import CrawlSpider from scrapy.http import Request from scrapy.selector import Selector from heartDisease.items import HeartdiseaseItem class heartSpider(CrawlSpider): name = "heartDisease" #开始的网址start_urls start_urls=['http://heart.39.net/zhlm/bljd/xzb/'] def __init__(self): self.item=HeartdiseaseItem() def parse(self, response): selector=Selector(response) #获取网页中的链接 urls=selector.xpath('//div[@class="newslist"]/ul/li/a/@href').extract() #遇到一个链接则调用一次parseContent函数 for url in urls: yield Request(url, callback=self.parseContent) #获取页数链接 page_links=selector.xpath('//div[@class="page"]//a').extract() #当a标签下的文本为“下一页”时,获取该a标签里的链接,便可以跳转到下一页 for link in page_links: if u'下一页' in link: next_link = selector.xpath('//div[@class="page"]//a/@href').extract()[-2] next_link='http://heart.39.net/zhlm/bljd/xzb/'+next_link yield Request(next_link, callback=self.parse) #获取各个链接里的内容,并传给item def parseContent(self,response): selector1=Selector(response) title=selector1.xpath('//title/text()').extract() self.item['title']=selector1.xpath('//title/text()').extract()[0] self.item['content'] = selector1.xpath('//div[@class="art_con"]/p/text()').extract() self.item['url'] = response.url yield self.item
当然,这个网页的爬取代码也可以不用for循环。毕竟一共只有三页,可以在start_urls中将网址全部放进去,如果页数太多就不建议这么写了。
分享一下:
http://www.cnblogs.com/Shirlies/p/4536880.html
http://www.tuicool.com/articles/eymema
http://www.cnblogs.com/jojolin/p/4642469.html
小某说:
嘿嘿嘿,好好学习,天天向上。我先去吃饭= ̄ω ̄=!!















 1982
1982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









