







“每一次辉煌的胜利,都源自无数精心策划的谋略。”
在探索战术和战略的艺术中,古代帝王和将军们深知,胜利不仅仅依赖于勇气和力量,更源自于对局势的精准计算和深思熟虑的布局。这种由数学原理支撑的战略思维,同样适用于现代技术领域的征战——尤其是在数据管理这片广袤的领域中。正如古代战争中胜利的关键往往隐藏在对敌我双方力量、地形地势以及兵力部署的精确计算之中,学好MySQL——这个关系型数据库的重要利器,也离不开对数学原理的深刻理解。
一、数学在关系型数据库设计中的角色是什么?

数学在关系型数据库设计中扮演着基础且关键的角色,提供了一种逻辑严密的框架和方法论,帮助设计高效、可靠的数据库系统。我们一起来看看吧!
结构的基础:集合论
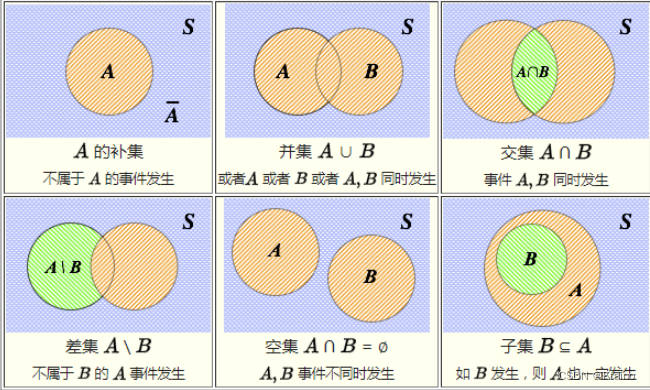
它是关系型数据库设计的数学基础。数据库中的表可以看作是元组的集合,而关系则可以理解为集合间的各种操作,如并集、交集和差集等。这种基于集合的模型为数据组织提供了一种高度抽象且灵活的方式。
SQL语句WHERE后面的条件:逻辑理论(谓词分支理论)
我们在中学的时候学到这样的数学陈述:“对任何自然数x,x大于0”,可以表示为“∀x ∈ 自然数, x > 0” 是否还记得?
它就是我们这里所说的谓词。现在我们切到SQL的视角来细细体会下
有一个数据库,其中包含两个表:Employees(员工)和Departments(部门),我们想要找出“在’IT’部门工作并且工资高于平均工资的所有员工的姓名和工资”。
假设Employees表包含Name(姓名)、Salary(工资)和DepartmentID(部门ID)列,而Departments表包含ID(部门ID)和DepartmentName(部门名称)列。
以下是SQL语句:
SELECT E.Name, E.Salary
FROM Employees E, Departments D
WHERE E.DepartmentID = D.ID
AND D.DepartmentName = 'IT'
AND E.Salary  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











