






最近有客户反馈:
客户有套rac集群 上面部署了zabbix监控 业务节点单独连接节点1的时候(单独连接节点2没有问题) 业务反馈会不定时出现 数据库更新缓慢问题 对awr分析 期间出现log sync file的等待事件 gc cr block busy及gcs log flush sync平均等待时间大于正常时间段的等待 zabbix有可能引起数据库的gc事件吗 有没有办法进一步确认
分析:
1、等待事件
正常时刻等待事件:log file sync 相对db cpu 正常 。
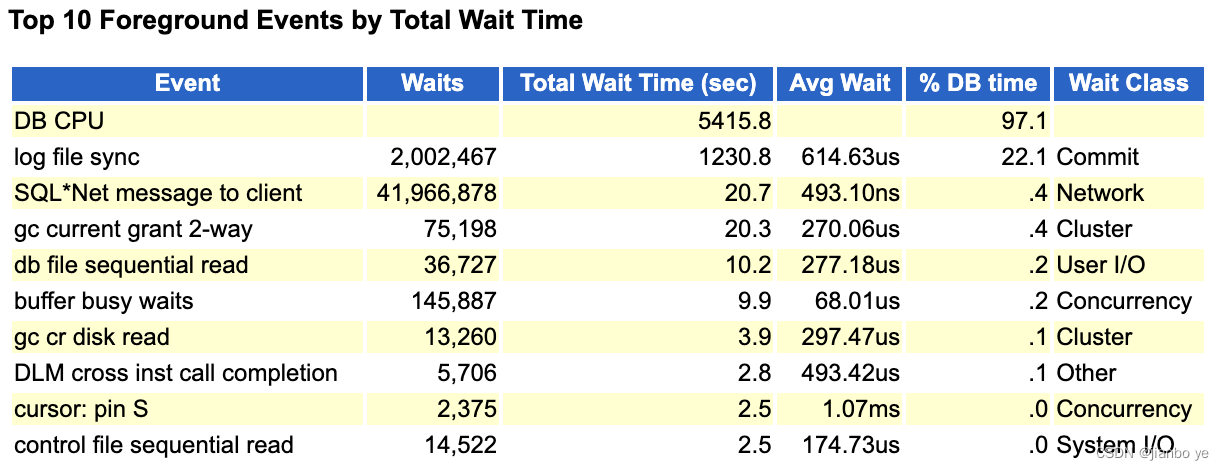
粗一看log file sync 也有22%,但是结合总体的db time来说还好。
问题时刻等待事件:log file sync 占比db time 非常高
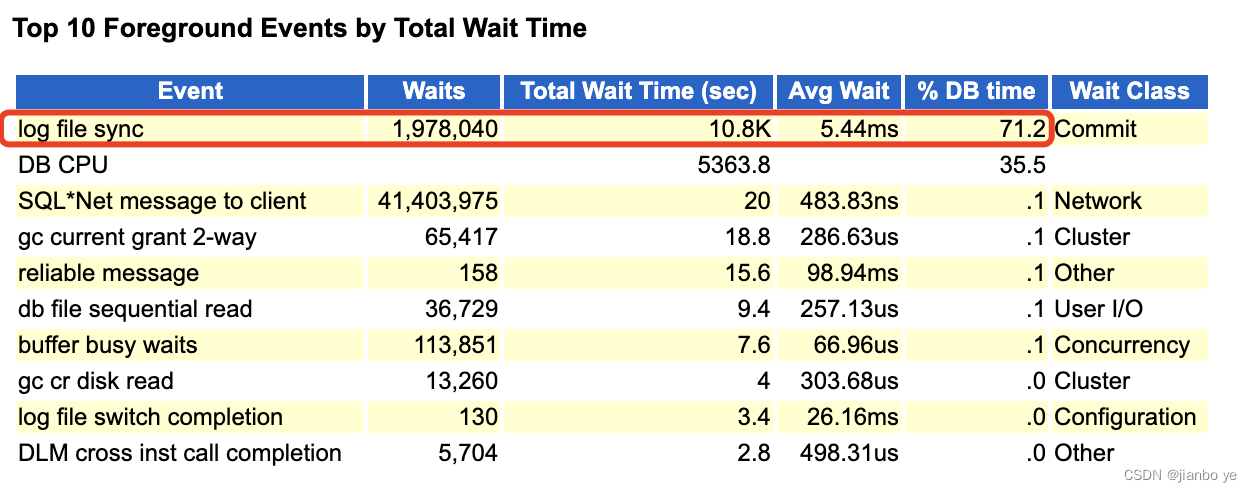

所以基本上可以锁定主要是log file sync 的问题。
回过头来,咋们理论分析下,导致log file sync的可能性
先看看LOG FILE SYNC的原理图
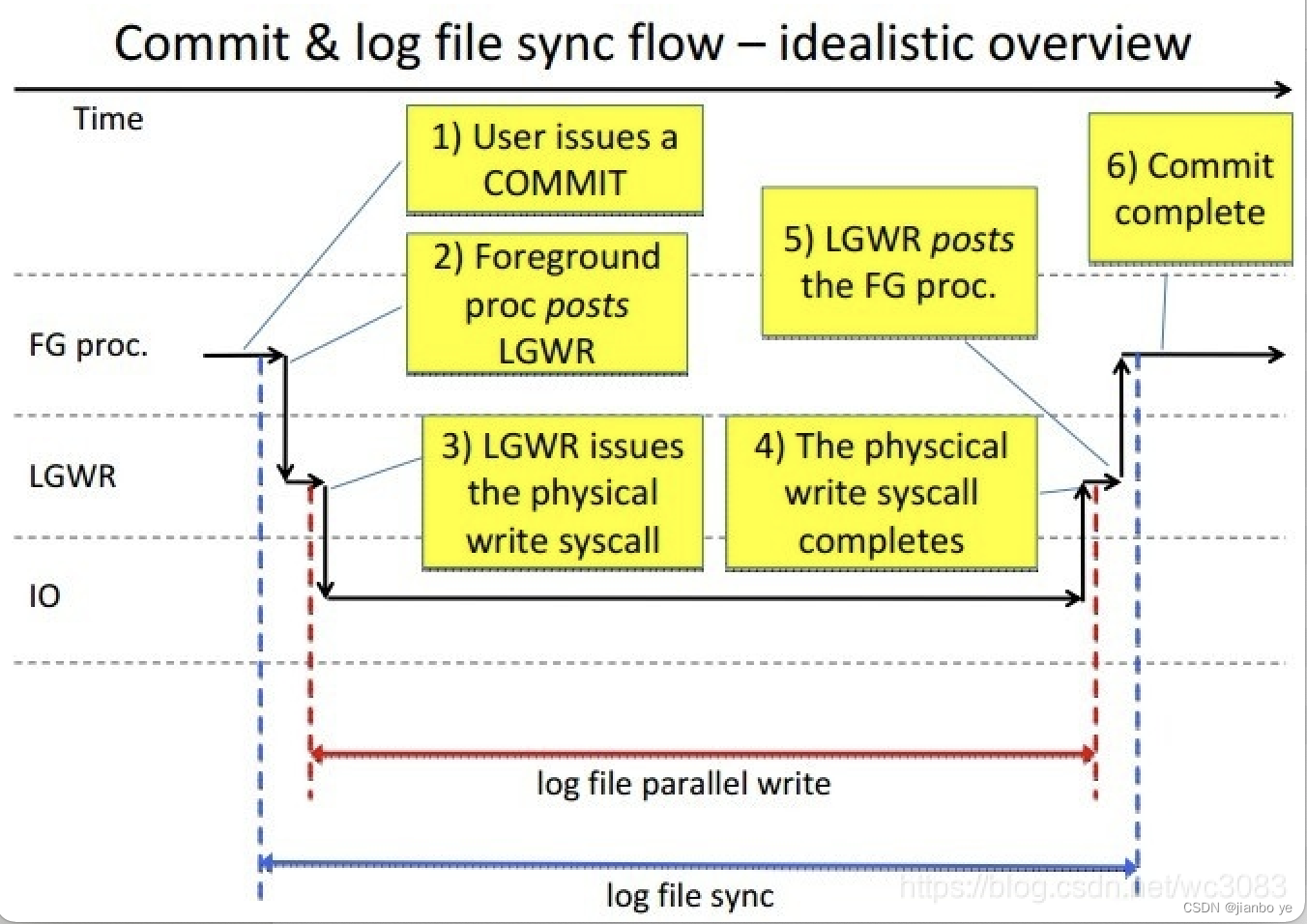
1、IO有问题(最常见的),从上图可以看出,如果和log file parallel write时间很接近解,那么大概率就是这个IO问题了
2、COMMT/ROLLBACK过多
3、段时间业务量太大,产生redo 过多,如批量DML
4、CPU资源紧张,lgwr进程获得不了响应的CPU时间片。
5、redo buffer太小
6、redo 日志文件太小或者组数不够
7、RAC节点之间SCN同步。
8、RAC节点之间CR块传递。
9、控制文件争用。
10、交易型(OLTP)数据库,参数_use_adaptive_log_file_sync建议修改为false,即固定使用post/wait机制,避免产生过多log file sync等待事件
篇幅有限,本次问题就是第一个问题,其他原因就不查了。
通过后台等待事件发现 log file parallel write等IO类等待占比也是非常明显。
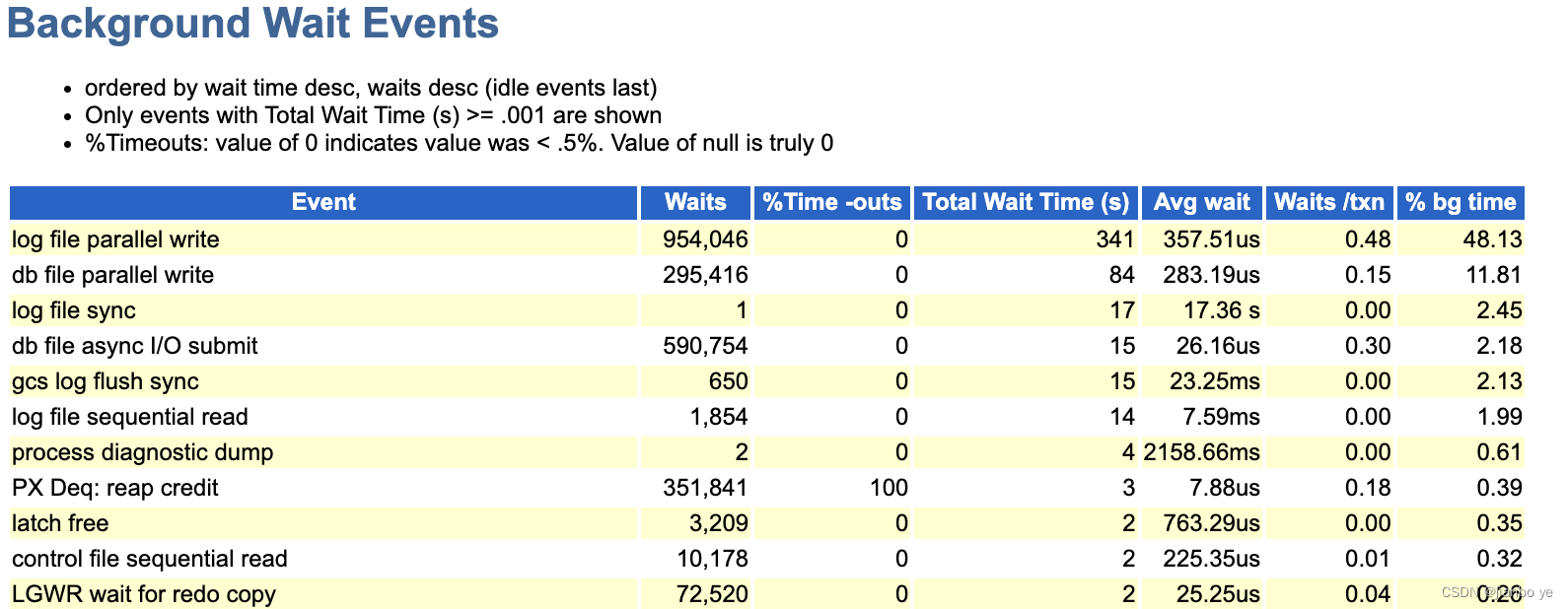
2、磁盘IO
1)通过查找存储厂商查看问题。。。。几乎很多客户的存储厂商感觉都是看不出很明显的问题,所以回复也是可想而知。
2)通过OSWATCH发现了问题
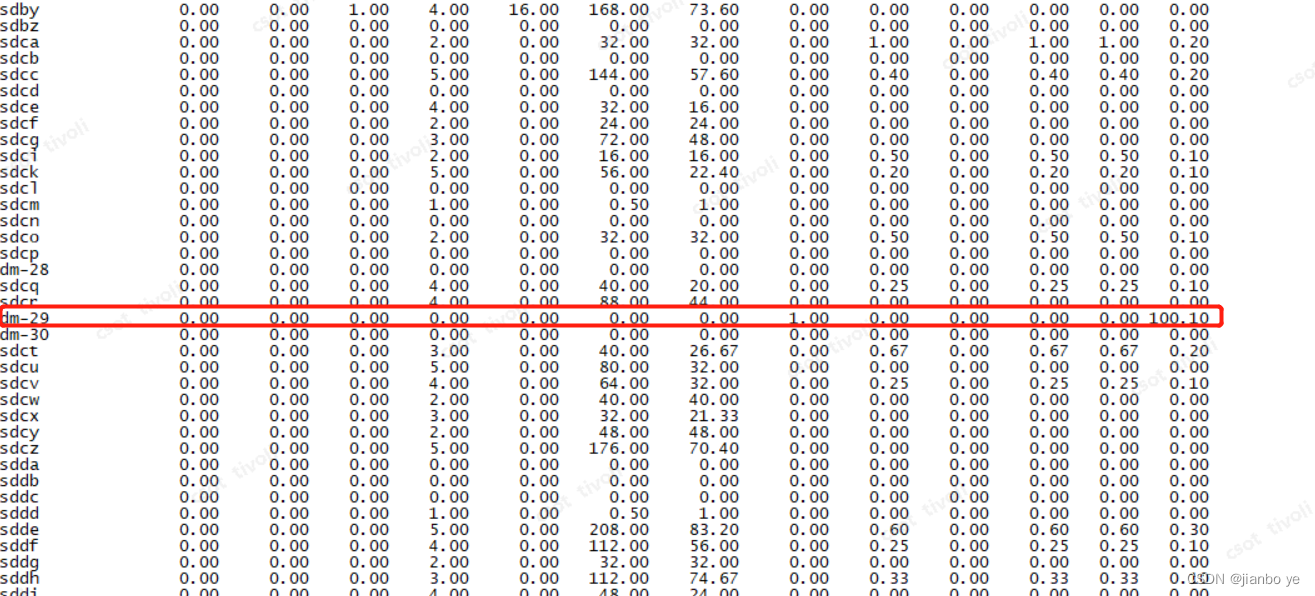
而这个dm-29就是我们的redo对应的磁盘。
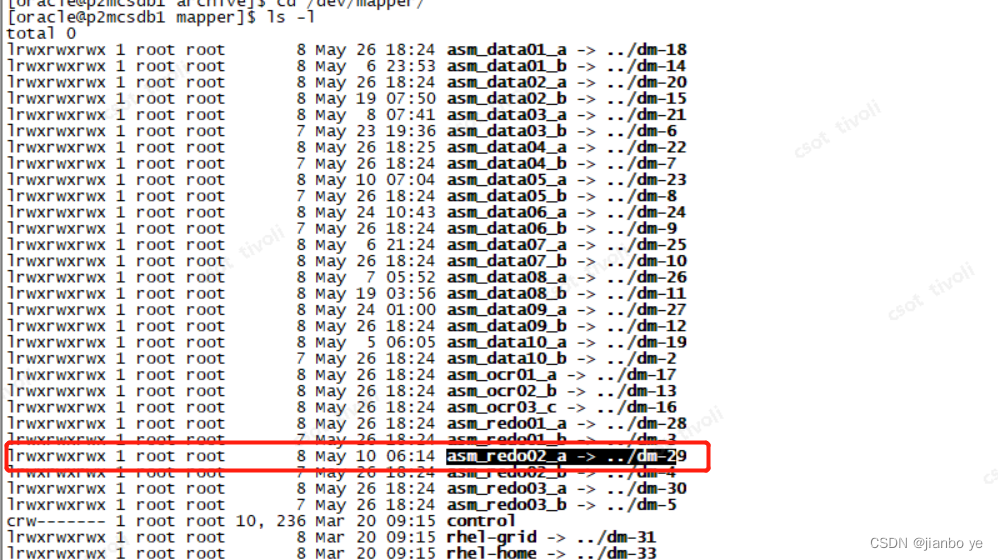
所以后面就是再找主机/存储厂商去继续分析问题。等问题分析完,再将业务回切会节点1.















 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









