







一、redis入门介绍
1、redis是什么
是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(key/value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一,也被人们称为数据结构服务器
2、redis能干嘛
- 缓存,毫无疑问这是Redis当今最为人熟知的使用场景。再提升服务器性能方面非常有效;
- 排行榜,在使用传统的关系型数据库(mysql oracle
等)来做这个事儿,非常的麻烦,而利用Redis的SortSet(有序集合)数据结构能够简单的搞定; - 计算器/限速器,利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
- 好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能;
- 简单消息队列,除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
- Session共享,以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
- 一些频繁被访问的数据,经常被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis中,因为redis
是放在内存中的可以很高效的访问
3、redis基础知识
- 单进程
- 单进程模型来处理客户端的请求。对读写等事件的响应 是通过对epoll函数的包装来做到的。Redis的实际处理速度完全依靠主进程的执行效率
- Epoll是Linux内核为处理大批量文件描述符而作了改进的epoll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。
- 默认16个数据库,类似数组下表从零开始,初始默认使用零号库
- Redis索引都是从零开始
二、redis的数据类型
参考文献:五大数据类型总结:字符串、散列、列表、集合和有序集合
1、字符串类型(String)
字符串类型是 Redis 中最基本的数据类型,可以存储二进制数据、图片和 Json 的对象。
字符串类型也是其他 4 种数据库类型的基础,其它数据类型可以说是从字符串类型中进行组织的,如:列表类型是以列表的形式组织字符串,集合类型是以集合的形式组织字符串。
应用:
(1)访问量统计:每次访问博客和文章使用 INCR 命令进行递增;
(2)将数据以二进制序列化的方式进行存储。
2、散列类型(Hash)
散列类型采用了字典结构(k-v)进行存储。
散列类型适合存储对象。可以采用这样的命名方式:对象类别和 ID 构成键名,使用字段表示对象的属性,而字段值则存储属性值。如:存储 ID 为 2 的汽车对象。
应用: 文章内容存储
3、列表类型(List)
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向两端添加元素。
列表类型内部是使用双向链表实现的,也就是说,获取越接近两端的元素速度越快,代价是通过索引访问元素比较慢。
应用:
(1)显示社交网站的新鲜事、热门评论和新闻等;
(2)当队列使用;
(3)记录日志。
4、集合(Set)
字符串的无序集合,不允许存在重复的成员。
多个集合类型之间可以进行并集、交集和差集运算。
应用: (1)文章标签。
5、有序集合(SortedSet)
在集合类型的基础上添加了排序的功能。
应用: (1)点击量排序
三、Redis持久化
参考地址:数据持久化
1、概述
Redis的强大性能很大程度上都是因为所有数据都是存储在内存中的,然而当Redis重启后,所有存储在内存中的数据将会丢失,在很多情况下是无法容忍这样的事情的。所以,我们需要将内存中的数据持久化!典型的需要持久化数据的场景如下:
- 将Redis作为数据库使用;
- 将Redis作为缓存服务器使用,但是缓存miss后会对性能造成很大影响,所有缓存同时失效时会造成服务雪崩,无法响应。
2、RDB方式
RDB方式的持久化是通过快照的方式完成的。当符合某种规则时,会将内存中的数据全量生成一份副本存储到硬盘上,这个过程称作”快照”。
快照执行的过程如下:
- Redis使用fork函数复制一份当前进程(父进程)的副本(子进程);
- 父进程继续处理来自客户端的请求,子进程开始将内存中的数据写入硬盘中的临时文件;
- 当子进程写完所有的数据后,用该临时文件替换旧的RDB文件,至此,一次快照操作完成。
在执行fork的时候操作系统(类Unix操作系统)会使用写时复制(copy-on-write)策略,即fork函数发生的一刻,父进程和子进程共享同一块内存数据,当父进程需要修改其中的某片数据(如执行写命令)时,操作系统会将该片数据复制一份以保证子进程不受影响,所以RDB文件存储的是执行fork操作那一刻的内存数据。所以RDB方式理论上是会存在丢数据的情况的(fork之后修改的的那些没有写进RDB文件)。
3、AOF方式
在使用Redis存储非临时数据时,一般都需要打开AOF持久化来降低进程终止导致的数据丢失,AOF可以将Redis执行的每一条写命令追加到硬盘文件中,这一过程显然会降低Redis的性能,但是大部分情况下这个影响是可以接受的,另外,使用较快的硬盘能提高AOF的性能。
虽然每次执行更改数据库的内容时,AOF都会记录执行的命令,但是由于操作系统本身的硬盘缓存的缘故,AOF文件的内容并没有真正地写入硬盘,在默认情况下,操作系统会每隔30s将硬盘缓存中的数据同步到硬盘,但是为了防止系统异常退出而导致丢数据的情况发生,我们还可以在Redis的配置文件中配置这个同步的频率:
1 # appendfsync always
2 appendfsync everysec
3 # appendfsync no
第一行表示每次AOF写入一个命令都会执行同步操作,这是最安全也是最慢的方式;
第二行表示每秒钟进行一次同步操作,一般来说使用这种方式已经足够;
第三行表示不主动进行同步操作,这是最不安全的方式。
4、二者的区别
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。

AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录

四、Redis的事务
参考文档:Redis之Redis事务
可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。
一个队列中,一次性、顺序性、排他性的执行一系列命令
1、常用命令

2、事务的几种case
1. 正常执行

2. 放弃事务
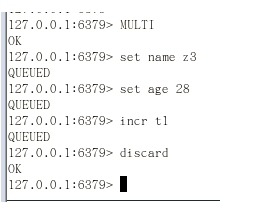
3. 全体连坐(类似于java编译期错误)
 4. 冤头债主
4. 冤头债主

5. 使用watch
case1:使用watch检测balance,事务期间balance数据未变动,事务执行成功
 case2:使用watch检测balance,在开启事务后(标注1处),在新窗口执行标注2中的操作,更改balance的值,模拟其他客户端在事务执行期间更改watch监控的数据,然后再执行标注1后命令,执行EXEC后,事务未成功执行。
case2:使用watch检测balance,在开启事务后(标注1处),在新窗口执行标注2中的操作,更改balance的值,模拟其他客户端在事务执行期间更改watch监控的数据,然后再执行标注1后命令,执行EXEC后,事务未成功执行。
 小结:
小结:
- Watch指令,类似乐观锁,事务提交时,如果Key的值已被别的客户端改变,比如某个list已被别的客户端push/pop过了,整个事务队列都不会被执行
- 通过WATCH命令在事务执行之前监控了多个Keys,倘若在WATCH之后有任何Key的值发生了变化,EXEC命令执行的事务都将被放弃,同时返回Nullmulti-bulk应答以通知调用者事务执行失败
3、三阶段
- 开启:以MULTI开始一个事务
- 入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
- 执行:由EXEC命令触发事务
4、三特性
- 单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题
- 不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
五、redis的主从复制
参考文档:Redis主从复制原理总结、Redis主从复制、Redis实现主从复制(Master&Slave)
1、介绍
- 是什么:我们所说的主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
- 能干嘛:读写分离,容灾恢复
2、常用3招
-
一主二仆
一个Master,两个Slave,Slave只能读不能写;当Slave与Master断开后需要重新slave of连接才可建立之前的主从关系;Master挂掉后,Master关系依然存在,Master重启即可恢复。

-
薪火相传
上一个Slave可以是下一个Slave的Master,Slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个slave的Master,如此可以有效减轻Master的写压力。如果slave中途变更转向,会清除之前的数据,重新建立最新的。

3. 反客为主
当Master挂掉后,Slave可键入命令 slaveof no one使当前redis停止与其他Master redis数据同步,转成Master redis
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









