






目录
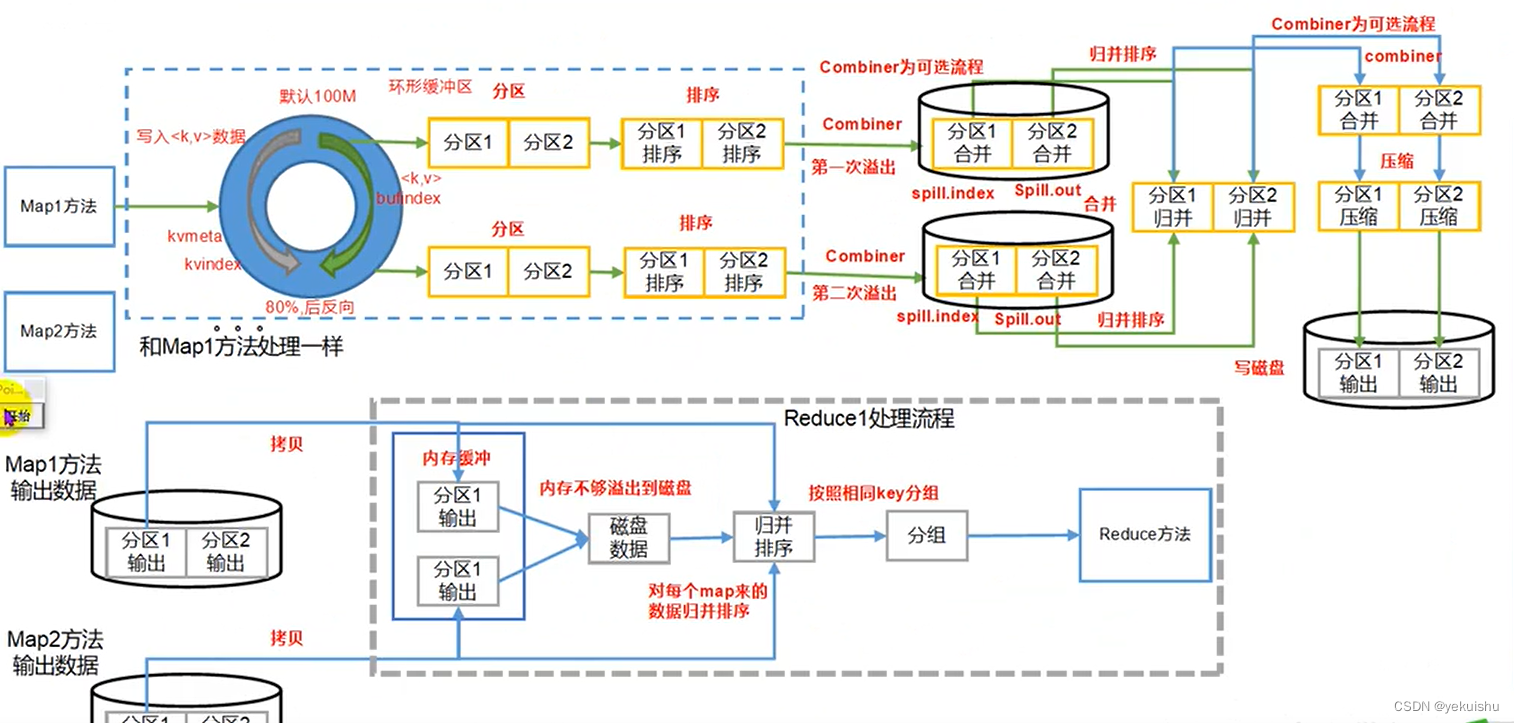
1、Map阶段
(1)减少溢写(Spill)次数:通过调整mapreduce.task.io.sort.mb及mapreduce.map.sort.spill.precent参数值,增大歘Spill的内存上线,减少Spill次数,从而减少磁盘IO
(2)减少合并(Merge)次数:通过mapreducetask.io.sort.factor参数,增大Merge的文件数目,减少Merge的次数,从而缩短MR处理时间。
(3)在Map之后,不影响业务逻辑前提下,先进行Combine处理,减少I/O.
set hive.mmap.aggr=true;
(4)shuffle阶段的压缩,网络传输。
2、Reduce阶段
(1)合理设置Map和Reduce数:合理设置Map、Reudce数目
(2)设置Map、Reduce共存:调整mapreduce.job.reduce.slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
(3)规避使用Reduce:因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
3、常用调优参数
| 配置参数 | 参数说明 |
| mapreduce.map.memory.mb | 一个MapTask可使用的资源上线(单位MB),默认为1024,如果MapTask实际使用的资源量超过该值,则会被强制杀死 |
| mapreduce.reduce.memery.mb | 一个ReduceTask可使用的资源上线(单位MB),默认为1024,如果MapTask实际使用的资源量超过该值,则会被强制杀死 |
| mapreduce.map.cpu.vcores | 每个MapTask可使用的最多cpu core数目,默认:1 |
| mapreduce.reduce.cpu.vcores | 每个ReduceTask可使用的最多cpu core数目,默认:1 |
| mapreduce.reduce.shuffle.parallelcopies | 每个Reduce去Map中 取数据的并行数,默认值是5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的数据大到多少比例开始写入磁盘。默认值0.66 |
| mapreduce.reduce.shuffle.input.buffer.perceent | Buffer大小占reduce可用内存的比例,默认0.7.如果超出了这个值,则开始溢写。 |
| mapreducereduce.reeduce..inputbuffer.percent | 指定多少比例的内存用来存放buffer中的数据,默认值是0.0 |
| mapreduce.task.io.sort.mb | 环形缓冲区大小 |
| mapreduce.map.sort.spill.precent | 环形缓冲区溢写比例 |
| mapreducetask.io.sort.factor | 一次排序的文件数量 |
4 Hadoop压缩配置
4.1 MR支持的压缩编码
表6-8
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
| DEFAULT | 无 | DEFAULT | .deflate | 否 |
| Gzip | gzip | DEFAULT | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 是 |
| Snappy | 无 | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
表6-9
| 压缩格式 | 对应的编码/解码器 |
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
表6-10
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
snappy | A fast compressor/decompressor
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
4.2 压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
表6-11
| 参数 | 默认值 | 阶段 | 建议 |
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | mapper输出 | 使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat. compress | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat. compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat. compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
4.3 开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。具体配置如下:
案例实操:
1.开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
2.开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
3.设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
4.执行查询语句
hive (default)> select count(ename) name from emp;
3.上一节中默认创建的ORC存储方式,导入数据后的大小为
2.8 M /user/hive/warehouse/log_orc/000000_0
比Snappy压缩的还小。原因是orc存储文件默认采用ZLIB压缩。比snappy压缩的小。
4.存储方式和压缩总结
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy,lzo。
4.4 开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
案例实操:
1.开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
2.开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3.设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
4.设置mapreduce最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5.测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory
‘/opt/module/datas/distribute-result’ select * from emp distribute by deptno sort by empno desc;
5 SMB join
全称Sort Merge Bucket Join。
2.1.6.1 作用
大表对小表应该使用MapJoin来进行优化,但是如果是大表对大表,如果进行shuffle,那就非常可怕,第一个慢不用说,第二个容易出异常,此时就可以使用SMB Join来提高性能。SMB Join基于bucket-mapjoin的有序bucket,可实现在map端完成join操作,可以有效地减少或避免shuffle的数据量。SMB join的条件和Map join类似但又不同。
2.1.6.2 条件
bucket mapjoin SMB join
set hive.optimize.bucketmapjoin = true; set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
一个表的bucket数是另一个表bucket数的整数倍 大表的bucket数=大表bucket数
bucket列 == join列 Bucket 列 == Join 列 == sort 列
必须是应用在map join的场景中 必须是应用在bucket mapjoin 的场景中
2.1.6.3 注意事项
hive并不检查两个join的表是否已经做好bucket且sorted,需要用户自己去保证join的表数据sorted,否则可能数据不正确。
有两个办法:
hive.enforce.sorting 设置为 true。开启强制排序时,插数据到表中会进行强制排序,默认false。
插入数据时通过在sql中用distributed c1 sort by c1 或者 cluster by c1
另外,表创建时必须是CLUSTERED且SORTED,如下:
create table test_smb_2(mid string,age_id string)
CLUSTERED BY(mid) SORTED BY(mid) INTO 500 BUCKETS;
综上,涉及到分桶表操作的齐全配置为:
--写入数据强制分桶
set hive.enforce.bucketing=true;
--写入数据强制排序
set hive.enforce.sorting=true;
--开启bucketmapjoin
set hive.optimize.bucketmapjoin = true;
--开启SMB Join
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
开启MapJoin的配置(hive.auto.convert.join和hive.auto.convert.join.noconditionaltask.size),还有限制对桶表进行load操作(hive.strict.checks.bucketing)可以直接设置在hive的配置项中,无需在sql中声明。
自动尝试SMB联接(hive.optimize.bucketmapjoin.sortedmerge)也可以在设置中进行提前配置。
6、开启本地模式
set hive.exec.mode.local.auto=true;
有时hive的输入数据量是非常小的。在这种情况下,为查询出发执行任务的时间消耗可能会比实际job的执行时间要多的多。对于大多数这种情况,hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间会明显被缩短
当一个job满足如下条件才能真正使用本地模式:
- 1.job的输入数据大小必须小于参数:hive.exec.mode.local.auto.inputbytes.max(默认128MB)
- 2.job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max(默认4)
- 3.job的reduce数必须为0或者1
可用参数hive.mapred.local.mem(默认0)控制child jvm使用的最大内存数。
7、什么情况下只有一个reduce
很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务;其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因:
a)没有group by的汇总,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’ group by pt; 写成 select count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’; 这点非常常见,希望大家尽量改写。
b)用了Order by
disticnt 需要判断是否启用了
c)Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换:
4)限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
8、矢量化查询
hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种hive特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
set hive.vectorized.execution.enabled=true;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









