







文章目录
1、gensim使用流程
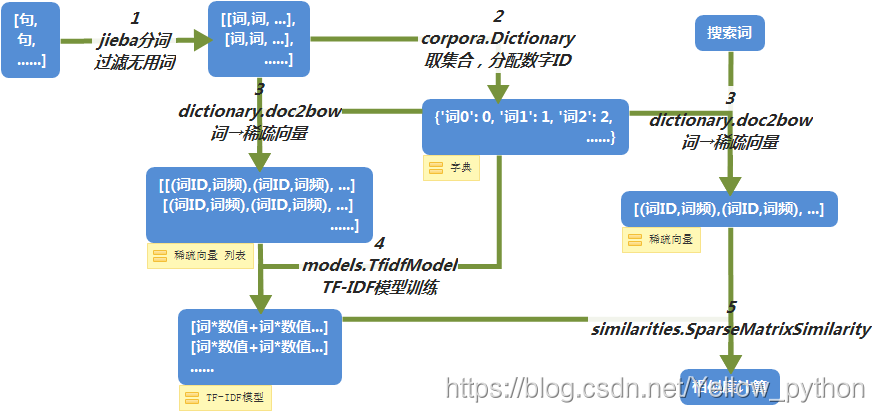
2、代码实现
from jieba import lcut
from gensim.similarities import SparseMatrixSimilarity
from gensim.corpora import Dictionary
from gensim.models import TfidfModel
# 文本集和搜索词
texts = ['吃鸡这里所谓的吃鸡并不是真的吃鸡,也不是谐音词刺激的意思',
'而是出自策略射击游戏《绝地求生:大逃杀》里的台词',
'我吃鸡翅,你吃鸡腿']
keyword = '玩过吃鸡?今晚一起吃鸡'
# 1、将【文本集】生成【分词列表】
texts = [lcut(text) for text in texts]
# 2、基于文本集建立【词典】,并获得词典特征数
dictionary = Dictionary(texts)
num_features = len(dictionary.token2id)
# 3.1、基于词典,将【分词列表集】转换成【稀疏向量集】,称作【语料库】
corpus = [dictionary.doc2bow(text) for text in texts]
# 3.2、同理,用【词典】把【搜索词】也转换为【稀疏向量】
kw_vector = dictionary.doc2bow(lcut(keyword))
# 4、创建【TF-IDF模型】,传入【语料库】来训练
tfidf = TfidfModel(corpus)
# 5、用训练好的【TF-IDF模型】处理【被检索文本】和【搜索词】
tf_texts = tfidf[corpus] # 此处将【语料库】用作【被检索文本】
tf_kw = tfidf[kw_vector]
# 6、相似度计算
sparse_matrix = SparseMatrixSimilarity(tf_texts, num_features)
similarities = sparse_matrix.get_similarities(tf_kw)
for e, s in enumerate(similarities, 1):
print('kw 与 text%d 相似度为:%.2f' % (e, s))
-
打印结果
-
keyword 与 text1 相似度为:0.65
keyword 与 text2 相似度为:0.00
keyword 与 text3 相似度为:0.12
3、过程拆解
3.1、生成分词列表
-
对文本集中的文本进行
中文分词,返回
- [‘word1’, ‘word2’, ‘word3’, …]
分词列表,格式如下:
import jieba
text = '七月七日长生殿,夜半无人私语时。'
words = jieba.lcut(text)
-
print(words)
- [‘七月’, ‘七日’, ‘长生殿’, ‘,’, ‘夜半’, ‘无人’, ‘私语’, ‘时’, ‘。’]
3.2、基于文本集建立词典,获取特征数
- corpora.Dictionary:建立词典
- len(dictionary.token2id):词典中词的个数
from gensim import corpora
import jieba
# 文本集
text1 = '坚果果实'
text2 = '坚果实在好吃'
texts = [text1, text2]
# 将文本集生成分词列表
texts = [jieba.lcut(text) for text in texts]
print('文本集:', texts)
# 基于文本集建立词典
dictionary = corpora.Dictionary(texts)
print('词典:', dictionary)
# 提取词典特征数
feature_cnt = len(dictionary.token2id)
print('词典特征数:%d' % feature_cnt)
-
打印结果
-
文本集: [[‘坚果’, ‘果实’], [‘坚果’, ‘实在’, ‘好吃’]]
词典: Dictionary(4 unique tokens: [‘坚果’, ‘果实’, ‘好吃’, ‘实在’])
词典特征数:4
3.3、基于词典建立语料库
语料库即存放稀疏向量的列表
from gensim import corpora
import jieba
text1 = '来东京吃东京菜'
text2 = '东京啊东京啊东京'
texts = [text1, text2]
texts = [jieba.lcut(text) for text in texts]
dictionary = corpora.Dictionary(texts)
print('词典(字典):', dictionary.token2id)
# 基于词典建立新的【语料库】
corpus = [dictionary.doc2bow(text) for text in texts]
print('语料库:', corpus)
-
打印结果
-
词典(字典): {‘东京’: 0, ‘吃’: 1, ‘来’: 2, ‘菜’: 3, ‘啊’: 4}
语料库: [[(0, 2), (1, 1), (2, 1), (3, 1)], [(0, 3), (4, 2)]]
3.3.1、doc2bow函数
-
1、将所有单词取【集合】,并对每个单词分配一个ID号
-
以
['东京', '啊', '东京', '啊', '东京']为例
对单词分配ID:东京→0;啊→4
变成:[0, 4, 0, 4, 0]
2、转换成
稀疏向量
-
0有
3个,即表示为( 0,3)
4有2个,即表示为( 4,2)
最终结果:[( 0,3), ( 4,2)]
3.3.2、搜索词也转成稀疏向量
from gensim import corpora
import jieba
text1 = '南方医院无痛人流'
text2 = '北方人流落南方'
texts = [text1, text2]
texts = [jieba.lcut(text) for text in texts]
dictionary = corpora.Dictionary(texts)
# 用【词典】把【搜索词】也转换为【稀疏向量】
keyword = '无痛人流'
kw_vector = dictionary.doc2bow(jieba.lcut(keyword))
-
print(kw_vector)
- [(0, 1), (3, 1)]
3.4、用语料库训练TF-IDF模型
- TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
from gensim import corpora, models, similarities
import jieba
text1 = '南方医院无痛人流'
text2 = '北方人流浪到南方'
texts = [text1, text2]
texts = [jieba.lcut(text) for text in texts]
dictionary = corpora.Dictionary(texts)
feature_cnt = len(dictionary.token2id.keys())
corpus = [dictionary.doc2bow(text) for text in texts]
# 用语料库来训练TF-IDF模型
tfidf = models.TfidfModel(corpus)
-
print(tfidf)
- TfidfModel(num_docs=2, num_nnz=9)
3.5、相似度计算
from gensim import corpora, models, similarities
import jieba
text1 = '无痛人流并非无痛'
text2 = '北方人流浪到南方'
texts = [text1, text2]
keyword = '无痛人流'
texts = [jieba.lcut(text) for text in texts]
dictionary = corpora.Dictionary(texts)
num_features = len(dictionary.token2id)
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.TfidfModel(corpus)
new_vec = dictionary.doc2bow(jieba.lcut(keyword))
# 相似度计算
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features)
print('\nTF-IDF模型的稀疏向量集:')
for i in tfidf[corpus]:
print(i)
print('\nTF-IDF模型的keyword稀疏向量:')
print(tfidf[new_vec])
print('\n相似度计算:')
sim = index[tfidf[new_vec]]
for i in range(len(sim)):
print('第', i+1, '句话的相似度为:', sim[i])

4、附录
-
阅读扩展
jieba中文分词
中文LDA模型
Python各种文本相似度计算
gensim实现搜索引擎 -
注释
| En | Cn |
|---|---|
| corpus | n. 文集;[计]语料库(复数:corpora) |
| sparse | adj. 稀疏的 |
| vector | n. 矢量 |
| Sparse Matrix Similarity | 稀疏矩阵相似性 |
| word2vec | word to vector |
| doc2bow | document to bag of words(词袋) |


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











