







接报障, 短信页面分页超时(.net 中默认最长超时时间为 30秒 ), 语句如下:
set statistics io on
set statistics time on
DECLARE @firstareaid BIGINT = 635098215722270914,
@sendTime_Start DATETIME = '2017/10/20 0:00:00',
@sql nvarchar(max)='
SELECT TOP 20
view_sms.* --共26个字段,不一一列举
FROM
dbo.[view_sms] WITH (NOLOCK)
WHERE [smsType] > 1010
AND [smscontent] > ''''
AND EXISTS(
SELECT 1
FROM organization_data A,
system_area_data B
WHERE A.areaid = B.areaid
AND B.parentid = @firstareaid
AND A.[organizationid] = [view_sms].[organizationid]
)
AND [sendTime] >= @sendTime_Start
ORDER BY
sendTime DESC'
EXEC sp_executesql @sql,N'@firstareaid BIGINT,@sendTime_Start DATETIME'
,@firstareaid = 635098215722270914
,@sendTime_Start = '2017/10/20 0:00:00'
/*
--相关表大小如下:
-- view_sms 由 sms_send_current_data union all sms_send_data
name rows reserved data_size index_size
organization_data 384 96 KB 48 KB 48 KB
system_area_data 35 32 KB 8 KB 24 KB
sms_send_current_data 222597 129336 KB 83744 KB 41496 KB
sms_send_data 2053548 853368 KB 611936 KB 239032 KB
*/
若将最后的排序字段 sendTime 改为主键 smsId , 则不到一秒,
但可惜的是业务逻辑不能变,因为两者顺序并不完全一致。
去掉 EXISTS 这个条件也不到一秒。
from view_sms 改成 from sms_send_data 也快不了多少。
先看下目前的执行计划:
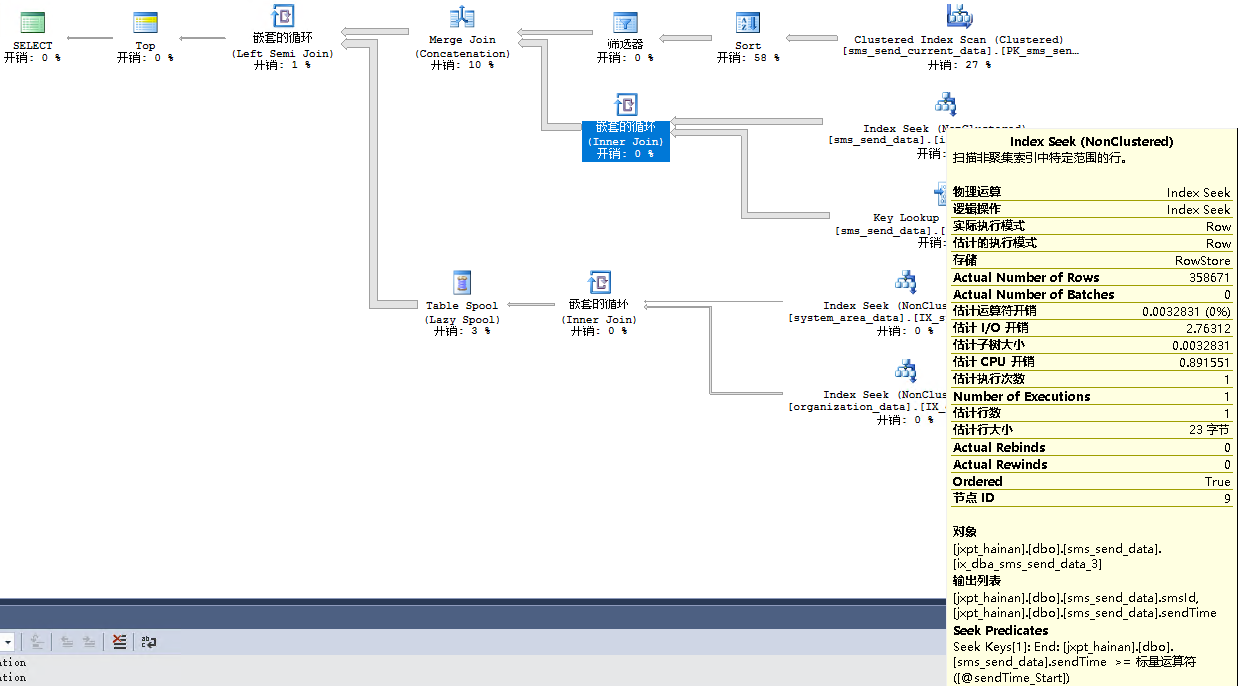
将语句末尾加 option ( hash join ) 之后不到一秒, 执行计划:
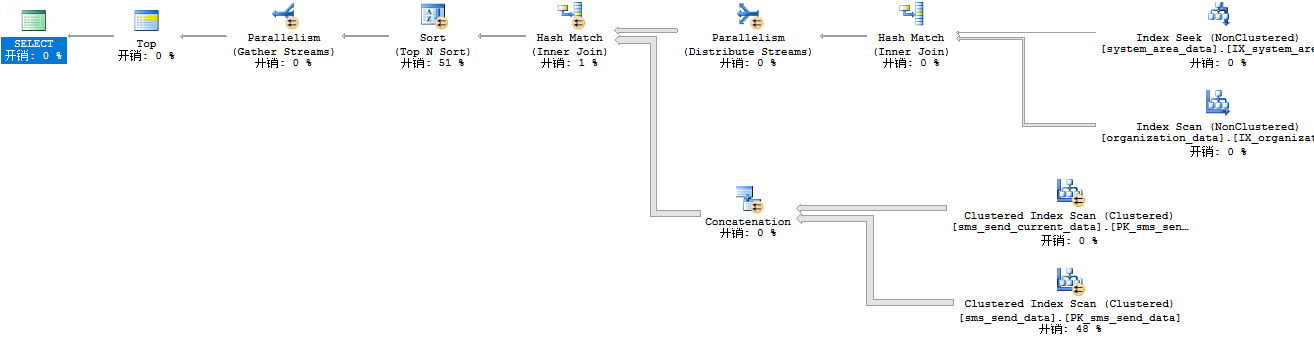
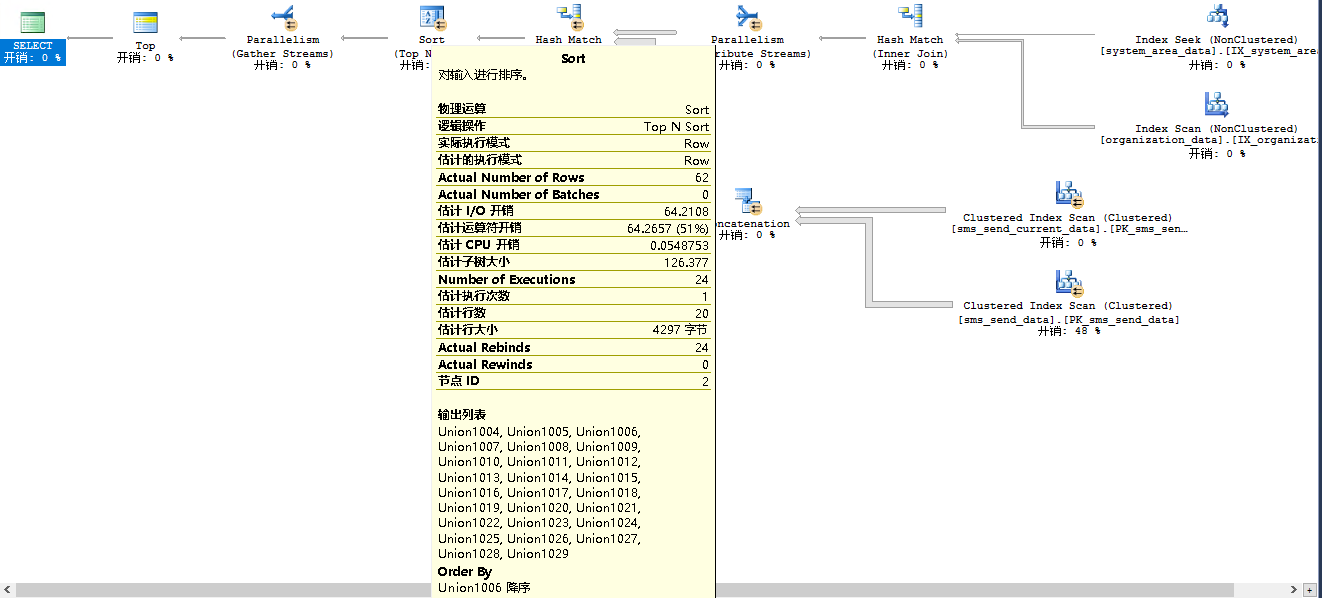
很让人惊讶, 执行计划如此简单, 而且两个表都直接弄了个聚集索引扫描(在一般情况下就是低效的代名词), 但实际上的效果却比较好。
最简单来看, 其估计行数与实际行数相差比较少。
| 优化前 | 优化后 |
|---|---|
set statistics io on set statistics time on DECLARE @firstareaid BIGINT = 635098215722270914, @sendTime_Start DATETIME = '2017/10/20 0:00:00', @sql nvarchar(max)=' SELECT TOP 20 view_sms.* FROM dbo.[view_sms] WITH (NOLOCK) WHERE [smsType] > 1010 AND [smscontent] > '''' AND EXISTS( SELECT 1 FROM organization_data A, system_area_data B WHERE A.areaid = B.areaid AND B.parentid = @firstareaid AND A.[organizationid] = dbo.[view_sms].[organizationid] ) AND [sendTime] >= @sendTime_Start ORDER BY sendTime DESC ' EXEC sp_executesql @sql,N'@firstareaid BIGINT,@sendTime_Start DATETIME' ,@firstareaid = 635098215722270914 ,@sendTime_Start = '2017/10/20 0:00:00' | set statistics io on set statistics time on DECLARE @firstareaid BIGINT = 635098215722270914, @sendTime_Start DATETIME = '2017/10/20 0:00:00', @sql nvarchar(max)=' SELECT TOP 20 view_sms.* FROM dbo.[view_sms] WITH (NOLOCK) WHERE [smsType] > 1010 AND [smscontent] > '''' AND EXISTS( SELECT 1 FROM organization_data A, system_area_data B WHERE A.areaid = B.areaid AND B.parentid = @firstareaid AND A.[organizationid] = dbo.[view_sms].[organizationid] ) AND [sendTime] >= @sendTime_Start ORDER BY sendTime DESC option(HASH JOIN)' EXEC sp_executesql @sql,N'@firstareaid BIGINT,@sendTime_Start DATETIME' ,@firstareaid = 635098215722270914 ,@sendTime_Start = '2017/10/20 0:00:00' |
| 表 'sms_send_current_data'。扫描计数 25,逻辑读取 5320 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'organization_data'。扫描计数 24,逻辑读取 72 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'system_area_data'。扫描计数 24,逻辑读取 48 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'Worktable'。扫描计数 24,逻辑读取 877028 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'sms_send_data'。扫描计数 25,逻辑读取 944460 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 28332 毫秒,占用时间 = 13990 毫秒。 SQL Server 执行时间: CPU 时间 = 28379 毫秒,占用时间 = 14036 毫秒。 | 表 'Workfile'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'organization_data'。扫描计数 1,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'system_area_data'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'sms_send_data'。扫描计数 25,逻辑读取 83040 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'sms_send_current_data'。扫描计数 25,逻辑读取 5321 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 2264 毫秒,占用时间 = 174 毫秒。 SQL Server 执行时间: CPU 时间 = 2264 毫秒,占用时间 = 174 毫秒。 |
| 总时间:14.036 s | 总时间:0.174 s |
不例外, hash join CPU 占用也不是很少。
不过对目前这个语句来说, 已经是比较好的优化选择了。
后面发现部分情况下会变得更慢, 改成用临时表, 这下才真正快了起来:
SET STATISTICS IO ON
SET STATISTICS TIME ON
DECLARE @firstareaid bigint,@sendTime_Start DATETIME
SET @firstareaid = 634594576097805995
SET @sendTime_Start ='2017-11-28 00:00:00.000'
IF OBJECT_ID('tempdb..#tmp') IS NOT NULL DROP TABLE #tmp
SELECT
smsId
INTO #tmp
FROM
dbo.[view_sms] WITH(NOLOCK)
WHERE
[smsType] > 1010
AND [smscontent] > ''
AND EXISTS(SELECT 1 FROM organization_data A ,system_area_data B
WHERE A.areaid = B.areaid AND B.parentid = @firstareaid AND A.[organizationid] = dbo.[view_sms].[organizationid])
AND [sendTime] >= @sendTime_Start
CREATE UNIQUE CLUSTERED INDEX ix_tmp_smsId ON #tmp(smsId)
SELECT COUNT(0) FROM #tmp
SELECT TOP 20
*
FROM
dbo.[view_sms] WITH(NOLOCK)
WHERE
EXISTS(
SELECT 1 FROM #tmp b WHERE [view_sms].smsId=b.smsId
)
ORDER BY
[sendTime] DESC
DROP TABLE #tmp















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









