







 文章介绍了如何利用提供的数据集构建基于特征提取和多模态融合的图像与文本检索模型,包括文本预处理、图像特征提取、特征融合以及图文检索的过程,并展示了任务一和任务二的结果。评价标准采用召回率@5。附有详细视频教程帮助理解。
文章介绍了如何利用提供的数据集构建基于特征提取和多模态融合的图像与文本检索模型,包括文本预处理、图像特征提取、特征融合以及图文检索的过程,并展示了任务一和任务二的结果。评价标准采用召回率@5。附有详细视频教程帮助理解。
目前b题已全部更新包含详细的代码模型和文章,本文也给出了结果展示和使用模型说明。
同时文章最下方包含详细的视频教学获取方式,手把手保姆级,模型高精度,结果有保障!
分析:
本题待解决问题
目标:利用提供的数据集,通过特征提取和多模态特征融合模型建立,实现图像与文本间的互检索。
具体任务:
基于图像检索的文本:利用提供的文本信息,对图像进行检索,输出相似度较高的前五张图像。
基于文本检索的图像:利用提供的图像ID,对文本进行检索,输出相似度较高的前五条文本。
数据集和任务要求
附件1:包含五万张图像和对应的文本信息。
附件2和附件3:分别提供了任务1和任务2的数据信息,包括测试集文本、图像ID和图像数据库。
附件4:提供了任务结果的模板文件。
评价标准
使用**召回率Recall at K(R@K)**作为评价指标,即查询结果中真实结果排序在前K的比率,本赛题设定K=5,即评价标准为R@5。
步骤一:构建图文检索模型
采用图文检索领域已经封装好的模型:多模态图文互检模型
基于本题附件一所给的数据进行调优
可以给大家展示以下我们模型的效果,和那种一两天做出来的效果完全不一样,我们的模型效果和两个任务的预测情况完整是准确且符合逻辑的。
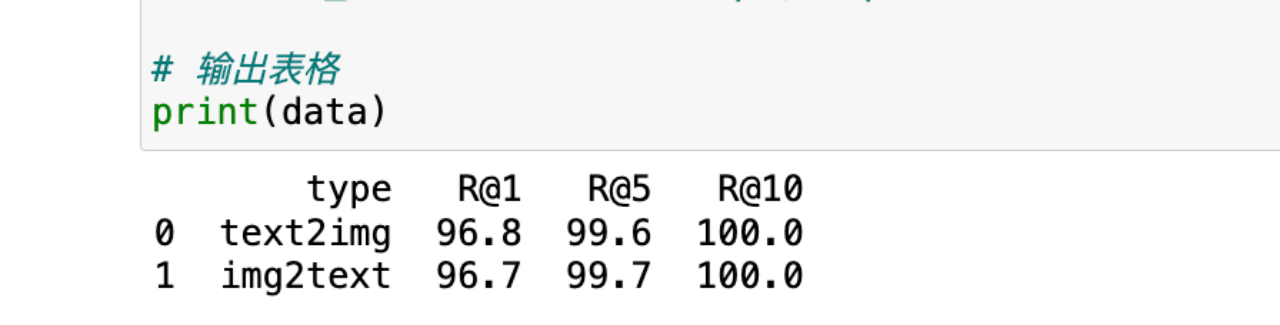
任务一结果展示:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











