






大学生平衡膳食食谱的优化设计及评价
摘要
大学阶段是学生获取知识和身体发育的关键时期,也是形成良好饮食习惯的重要阶段。然而,当前大学生中存在饮食结构不合理和不良饮食习惯的问题,主要表现为不吃早餐或早餐吃得马虎,经常食用高油高盐且营养不均衡的外卖和快餐,以及通过不科学的节食减肥,导致营养不良和健康受损。因此,大学生在这一阶段掌握营养知识并形成良好饮食习惯,对于促进生长发育和维护身体健康具有重要意义。
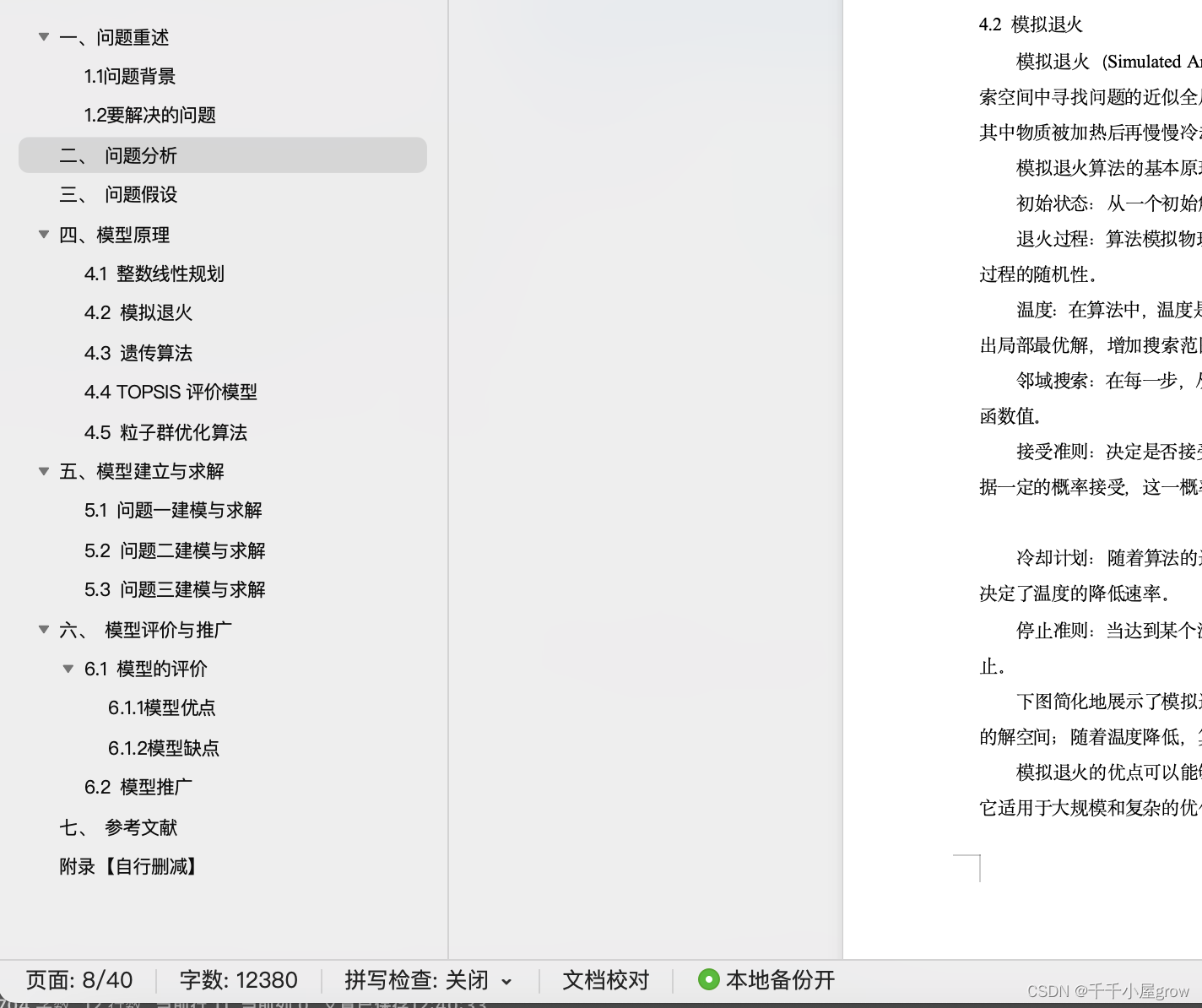
在本文中,针对给出的一份男大学生以及女大学生的食谱,本文从产能营养素、非产能营养素以及蛋白质氨基酸评分入手,分别计算了两个食谱对应的产能营养素、非产能营养素以及蛋白质氨基酸评分并与参考的摄入量进行对比,随后构建了TOPSIS评价模型,对产能营养素、非产能营养素以及蛋白质氨基酸评分三项指标赋予适当的权重,以参考的摄入量作为最优值对给定食谱进行评价,最后根据评价结果,我们对食谱进行一定的调整,分别为男大的食谱中减去了一个炸鸡块以及为女大食谱加上了两份米饭。
对于问题二三来说,我们综合进行考虑。首先针对氨基酸评分最大化这个目标,我们结合实际情况构建了相关的约束条件,分别包含每餐的热量摄入占比,每天的微量元素(非产能营养素)摄入情况、AAS等进行约束,随后分别采用PSO粒子群优化算法以及遗传算法对目标进行优化。最后取得不错的结果。在此基础上,分别考虑了最经济型食谱以及兼顾经济以及氨基酸评分两点作为目标的情况,同样结果不错。最后我们进一步考虑整周的食谱,考虑菜品尽可能不重复,并将其量化成约束条件,进一步给出三个优化目标下优化函数最优的食谱。
关键词:TOPSIS评价模型、遗传算法、PSO粒子群优化算法、整数规划
在这一小节中,我们需要对给出的附件数据进行数据预处理,以方便我们后续的模型构建。
观察到给出的附件1-3的数据文件是在同一个sheet下的多个表格,这不利于python对其进行读取以及后续操作,因此本文中,根据早餐、午餐以及晚餐三餐,将其划分成3个sheet,保存在新的excel文件中。
这样之后,我们就可以比较容易的提取出男大学生以及女大学生的三餐食谱,分别是:
男大学生:{‘早餐’: [‘小米粥’, ‘油条’, ‘煎鸡蛋’, ‘拌海带丝’],
‘午餐’: [‘大米饭’, ‘拌木耳’, ‘地三鲜’, ‘红烧肉’],
‘晚餐’: [‘砂锅面’, ‘包子’, ‘炸鸡块’]}
女大学生:{‘早餐’: [‘豆浆’, ‘鸡排面’],
‘午餐’: [‘鸡蛋饼’, ‘水饺’, ‘葡萄’],
‘晚餐’: [‘大米饭’, ‘香菇炒油菜’, ‘炒肉蒜台’, ‘茄汁沙丁鱼’, ‘苹果’]}
为了进一步计算两份食谱中的营养素等含量,我们需要对比《中国食物成分表》,从中查询了学校提供食物中包含的所有主要成分的食材对应的营养成分,统计成一个表格,下面将展示部分数据:
5.1.1营养分析评价模型
在收集好相关的膳食营养成分数据之后,下面我们需要对膳食食谱进行全面的营养分析评价,我们将按照以下步骤进行:
- 食物结构分析:分析食谱中食物的种类和数量,确保食物种类多样化。对于这一步我们已经在上一小节中提取出了男女两位大学生的一日食谱。
- 营养素含量计算:计算每种食物的营养素含量,包括热量、蛋白质、脂肪和碳水化合物。
- 能量及营养素评估:将计算出的营养素摄入量与推荐摄入量进行比较,评价摄入量是否符合推荐标准。
- 无产营养素以及AAS计算:计算每种食物的营养素含量,包括钙、铁、锌、以及各类维生素含量。随后根据给出的蛋白质氨基酸含量,进一步计算AAS。
- TOPSIS综合评价模型:根据计算得到的营养素含量、无产营养素以及AAS,结合推荐的每日营养素摄入量对给出的食谱进行评价。
5.1.2 模型公式
-
营养素含量计算公式
对于每种食物i,其营养素 j的含量可以表示为:其中:
表示食物 中营养素 的含量。
表示食物 i 每100克中营养素 j 的含量。
表示食物 i 的可食部重量(克)。 -
总营养素含量计算公式
一日三餐的总营养素含量为所有食物营养素含量的总和:
5.2 问题二建模与求解
问题二包括三个优化目标:用餐费用最经济、最大化蛋白质氨基酸评分和兼顾蛋白质氨基酸评分及经济性。下面我们将详细描述每个优化目标的建模过程及数据处理步骤。
优化目标一:用餐费用最经济
-
数据准备:
食物数据:包括食物名称、主要成分、价格、热量、蛋白质、脂肪、碳水化合物和蛋白质氨基酸评分(AAS)。 -
决策变量:
X ij : 第 i 天第 j 种食物的份数,其中 i = 1, 2, …, j 是食物种类索引。 -
目标函数:
- 最小化总费用:
其中, c_j 是第 j 种食物的价格,N 是食物种类总数。
-
约束条件:
- 每天的热量需求:
其中, e_j 是第 j 种食物的热量。
- 每天的蛋白质需求:
其中, p_j 是第 j 种食物的蛋白质含量。
- 每天的脂肪需求:
其中, f_j 是第 j 种食物的脂肪含量。
- 每天的碳水化合物需求:
其中, c_j 是第 j 种食物的碳水化合物含量。
-
每天的食物份数限制:
-
食物份数非负:
优化目标二:最大化蛋白质氨基酸评分
-
数据准备:
- 同优化目标一的数据准备步骤。
-
决策变量:
x_ij : 第 i 天第 j 种食物的份数,其中 i = 1, 2, …, j 是食物种类索引。 -
目标函数:
- 最大化总蛋白质氨基酸评分:
其中, aas_j 是第 j 种食物的蛋白质氨基酸评分。
- 约束条件:同优化目标一的约束条件。
优化目标三:兼顾蛋白质氨基酸评分及经济性
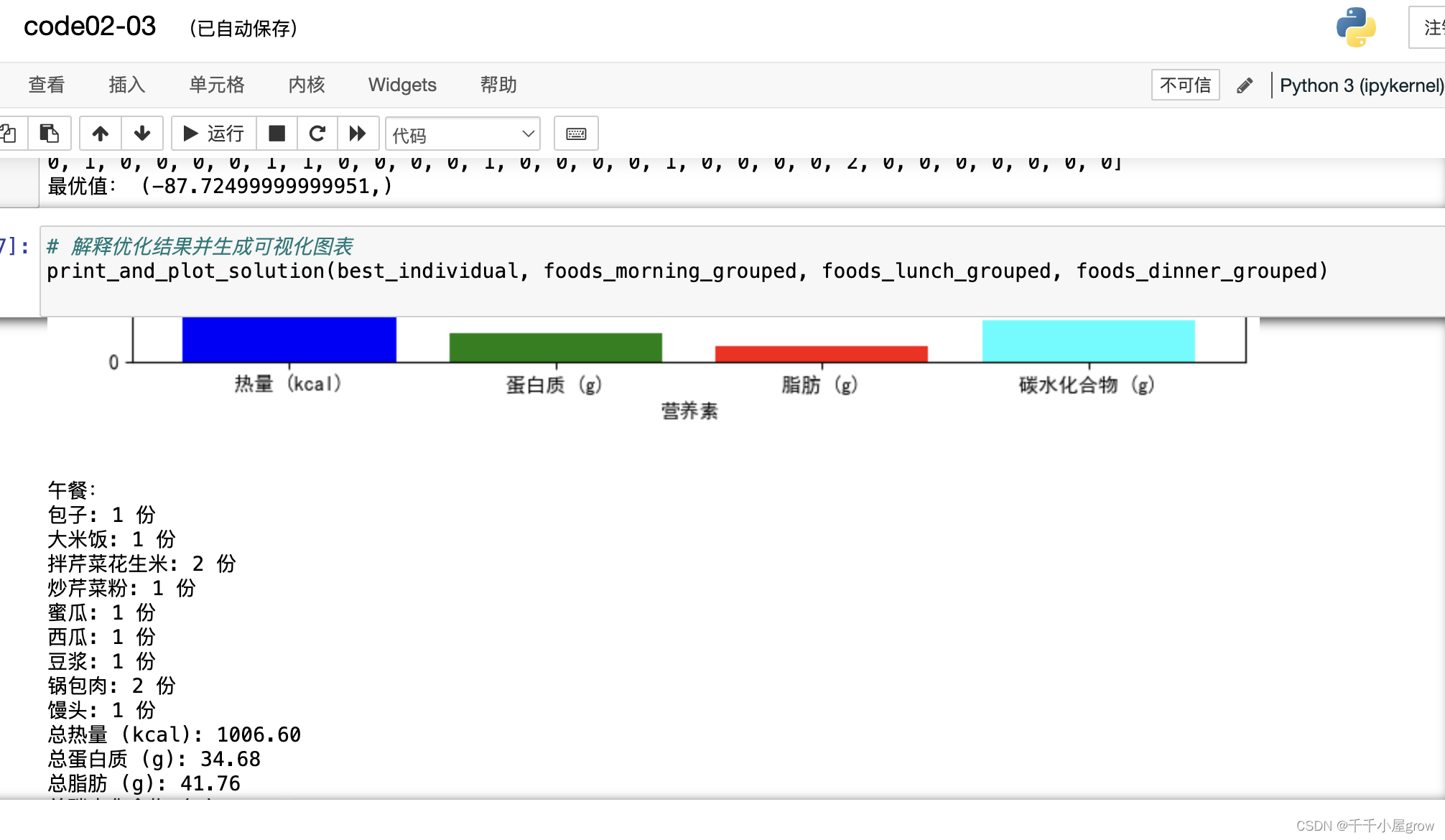
核心代码:
# 定义评估函数以最小化费用
def evaluate_cost(individual):
x_morning = individual[:len(foods_morning_grouped)]
x_lunch = individual[len(foods_morning_grouped):len(foods_morning_grouped)+len(foods_lunch_grouped)]
x_dinner = individual[len(foods_morning_grouped)+len(foods_lunch_grouped):]
total_cost = np.dot(x_morning, foods_morning_grouped['价格\n(元/份)'].values) + np.dot(x_lunch, foods_lunch_grouped['价格\n(元/份)'].values) + np.dot(x_dinner, foods_dinner_grouped['价格\n(元/份)'].values)
total_energy = np.dot(x_morning, foods_morning_grouped['热量 (kcal)'].values) + np.dot(x_lunch, foods_lunch_grouped['热量 (kcal)'].values) + np.dot(x_dinner, foods_dinner_grouped['热量 (kcal)'].values)
total_protein = np.dot(x_morning, foods_morning_grouped['蛋白质 (g)'].values) + np.dot(x_lunch, foods_lunch_grouped['蛋白质 (g)'].values) + np.dot(x_dinner, foods_dinner_grouped['蛋白质 (g)'].values)
total_fat = np.dot(x_morning, foods_morning_grouped['脂肪 (g)'].values) + np.dot(x_lunch, foods_lunch_grouped['脂肪 (g)'].values) + np.dot(x_dinner, foods_dinner_grouped['脂肪 (g)'].values)
total_carb = np.dot(x_morning, foods_morning_grouped['碳水化合物 (g)'].values) + np.dot(x_lunch, foods_lunch_grouped['碳水化合物 (g)'].values) + np.dot(x_dinner, foods_dinner_grouped['碳水化合物 (g)'].values)
total_servings = np.sum(individual)
penalty = 0
if total_energy > 4000:
penalty += (total_energy - 4000) * 10
if total_energy < 2400:
penalty += (2400 - total_energy) * 10
if total_protein < 60:
penalty += (60 - total_protein) * 10
if total_fat < 53:
penalty += (53 - total_fat) * 10
if total_carb < 300:
penalty += (300 - total_carb) * 10
if total_servings > 25:
penalty += (total_servings - 25) * 10
return total_cost + penalty,
toolbox.register("evaluate", evaluate_cost)
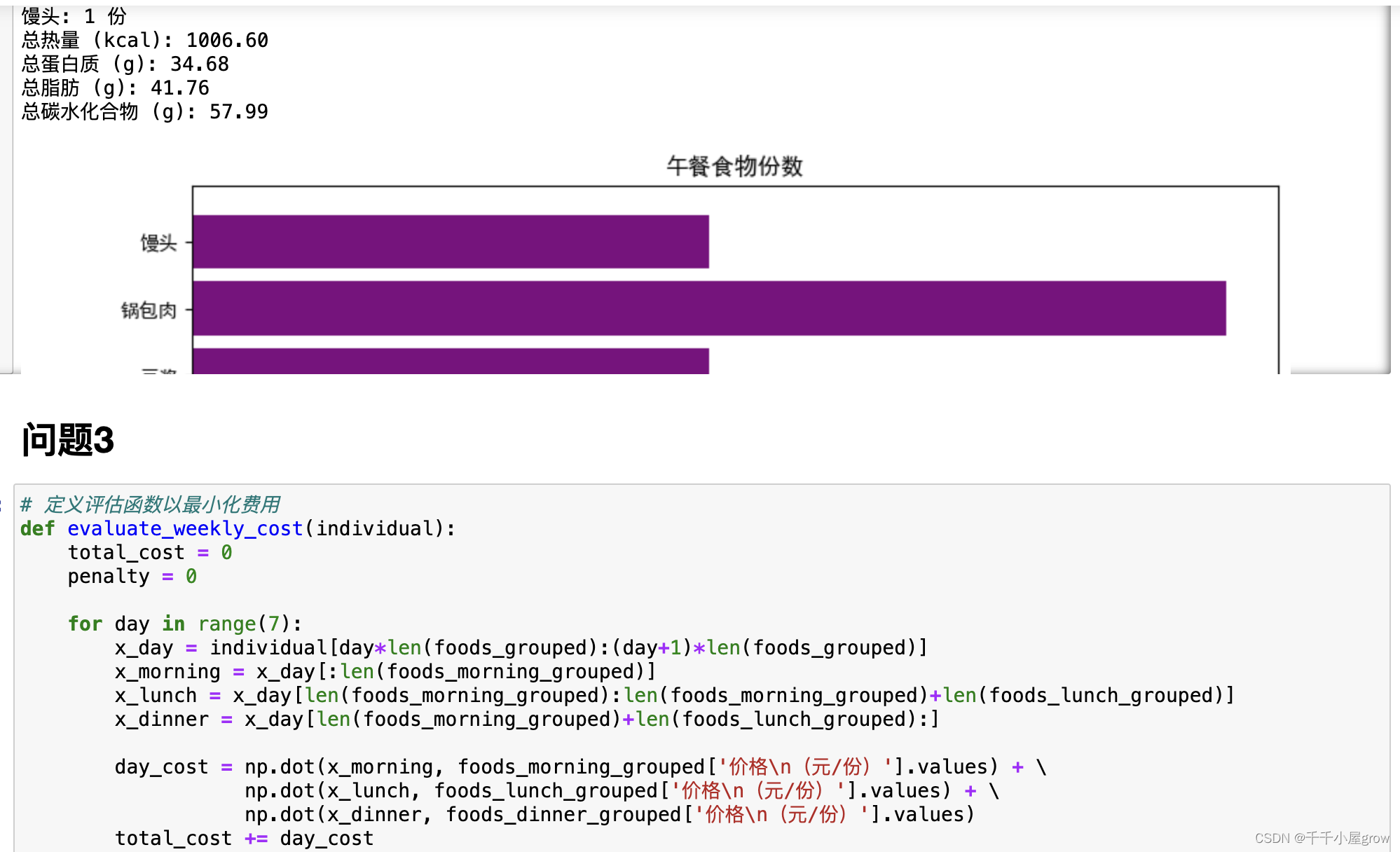
问题三核心代码:
# 删除已存在的类
if hasattr(creator, "FitnessMin"):
del creator.FitnessMin
if hasattr(creator, "Individual"):
del creator.Individual
# 创建最小化问题的fitness function
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
# 创建个体和种群
creator.create("Individual", list, fitness=creator.FitnessMin)
toolbox = base.Toolbox()
# 定义个体生成函数,生成整数列表,表示每种食物的份数
toolbox.register("attr_int", random.randint, 0, 10)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_int, n=len(foods_grouped) * 7)
# 定义种群生成函数
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
# 注册选择函数
toolbox.register("select", tools.selTournament, tournsize=3)
# 注册交叉和变异函数
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutUniformInt, low=0, up=10, indpb=0.2)
# 评估函数:兼顾蛋白质氨基酸评分及经济性
def evaluate_weekly_combined(individual):
total_cost = 0
total_aas = 0
penalty = 0
unique_meals = set()
for day in range(7):
x_day = individual[day*len(foods_grouped):(day+1)*len(foods_grouped)]
x_morning = x_day[:len(foods_morning_grouped)]
x_lunch = x_day[len(foods_morning_grouped):len(foods_morning_grouped)+len(foods_lunch_grouped)]
x_dinner = x_day[len(foods_morning_grouped)+len(foods_lunch_grouped):]
day_cost = np.dot(x_morning, foods_morning_grouped['价格\n(元/份)'].values) + \
np.dot(x_lunch, foods_lunch_grouped['价格\n(元/份)'].values) + \
np.dot(x_dinner, foods_dinner_grouped['价格\n(元/份)'].values)
total_cost += day_cost
day_aas = np.dot(x_morning, foods_morning_grouped['AAS'].values) + \
np.dot(x_lunch, foods_lunch_grouped['AAS'].values) + \
np.dot(x_dinner, foods_dinner_grouped['AAS'].values)
total_aas += day_aas
day_energy = np.dot(x_morning, foods_morning_grouped['热量 (kcal)'].values) + \
np.dot(x_lunch, foods_lunch_grouped['热量 (kcal)'].values) + \
np.dot(x_dinner, foods_dinner_grouped['热量 (kcal)'].values)
day_protein = np.dot(x_morning, foods_morning_grouped['蛋白质 (g)'].values) + \
np.dot(x_lunch, foods_lunch_grouped['蛋白质 (g)'].values) + \
np.dot(x_dinner, foods_dinner_grouped['蛋白质 (g)'].values)
day_fat = np.dot(x_morning, foods_morning_grouped['脂肪 (g)'].values) + \
np.dot(x_lunch, foods_lunch_grouped['脂肪 (g)'].values) + \
np.dot(x_dinner, foods_dinner_grouped['脂肪 (g)'].values)
day_carb = np.dot(x_morning, foods_morning_grouped['碳水化合物 (g)'].values) + \
np.dot(x_lunch, foods_lunch_grouped['碳水化合物 (g)'].values) + \
np.dot(x_dinner, foods_dinner_grouped['碳水化合物 (g)'].values)
day_servings = np.sum(x_day)
# 计算不重复食谱的惩罚
day_meal = tuple(x_day)
if day_meal in unique_meals:
penalty += 1000 # 对重复食谱进行高惩罚
else:
unique_meals.add(day_meal)
if day_energy > 4000:
penalty += (day_energy - 4000) * 10
if day_energy < 2400:
penalty += (2400 - day_energy) * 10
if day_protein < 60:
penalty += (60 - day_protein) * 10
if day_fat < 53:
penalty += (53 - day_fat) * 10
if day_carb < 300:
penalty += (300 - day_carb) * 10
if day_servings > 25:
penalty += (day_servings - 25) * 10
return total_cost - total_aas + penalty,
toolbox.register("evaluate", evaluate_weekly_combined)
# 设置遗传算法的参数
population = toolbox.population(n=1000) # 种群大小
ngen = 3000 # 迭代次数
cxpb = 0.7 # 交叉概率
mutpb = 0.2 # 变异概率
# 运行遗传算法
algorithms.eaSimple(population, toolbox, cxpb, mutpb, ngen, stats=None, halloffame=None, verbose=True)
# 获取最优解
best_individual = tools.selBest(population, k=1)[0]
print("最优解:", best_individual)
print("最优值:", toolbox.evaluate(best_individual))
## 2024电工杯助攻详情
## docs.qq.com/doc/DVWRIQUlKaVNqcWFr


















 3536
3536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











