









Java语言基础
函数
函数的定义
函数就是定义在类中的具有特定功能的一段独立小程序。函数也称为方法。
函数的格式:
修饰符 返回值类型 函数名(参数类型 形式参数1, 参数类型 形式参数2, ... )
{
执行语句;
return 返回值;
}- 返回值类型:函数运行后的结果的数据类型。
- 参数类型:是形式参数的数据类型。
- 形式参数:是一个变量,用于存储调用函数时传递给函数的实际参数。
- 实际参数:传递给形式参数的具体数值。
- return:用于结束函数。
- 返回值:该值会返回给调用者。
试看以下代码:
int x = 4;
System.out.println(x*3+5);
x = 6;
System.out.println(x*3+5);发现以上的运算,因为获取不同数据的运算结果,代码出现了重复。为了提高代码的复用性,对代码进行了抽取,将这个部分定义成一个独立的功能,方便于日后使用,java中对该功能的定义是通过函数的形式来体现的。
所以,我们有了一个需求:定义一个功能,完成一个整数*3+5的运算,并打印结果。
public static int getResult(int num) {
return num * 3 + 5;
} 当函数运算后没有具体的返回值,这时返回值类型用一个特殊的关键字来标识,该关键字就是void。void:代表的是函数没有具体返回值的情况。当函数的返回值类型是void时,函数中的return语句可以省略不写。即:
public static void getResult(int num) {
System.out.println(num * 3 + 5);
return; // 可以省略
} 函数的特点
- 定义函数可以将功能代码进行封装,便于对该功能进行复用
- 函数只有被调用才会被执行
- 函数的出现提高了代码的复用性
- 对于函数没有具体返回值的情况,返回值类型用关键字
void表示,那么该函数中的return语句如果在最后一行可以省略不写。
注意:
- 函数中只能调用函数,不可以在函数内部定义函数。
- 定义函数时,函数的结果应该返回给调用者,交由调用者处理。
函数的应用
如何定义一个函数呢?
- 既然函数是一个独立的功能,那么该功能的运算结果是什么呢?所以得先明确。因为这是在明确函数的返回值类型。
- 再明确在定义该功能的过程中,是否需要未知的内容参与运算。因为这是在明确函数的参数列表(参数的类型和参数的个数)。
例1,需求:定义一个功能:完成3+4的运算,并将结果返回给调用者。
解:
- 明确功能的结果:是一个整数的和。
- 在实现该功能的过程中,是否有未知内容参与运算:没有。
其实这两个功能就是在明确函数的定义:
- 明确函数的返回值类型
- 明确函数的参数列表(参数的类型和参数的个数)
public static int getSum() {
return 3 + 4;
}以上这个函数的功能,结果是固定的,毫无扩展性而言,为了方便用户需求,由用户来指定加数和被加数,这样,功能才有意义。
例2,定义一个功能,可以实现两个整数的加法运算。
解:
- 功能结果是一个和,返回值类型是int
- 有未知内容参与运算,有2个,这2个未知内容的类型都是int
public static int getSum(int x, int y) {
return x + y;
}例3,需求:判断两个数是否相同?
解:
- 明确功能结果:结果是boolean类型
- 功能是否有未知内容参与运算:有,两个整数
public static boolean compare(int a, int b) {
if(a == b)
return true;
else
return false;
}第一次优化后:
public static boolean compare(int a, int b) {
if(a == b)
return true;
return false;
}第二次优化后:
public static boolean compare(int a, int b) {
return a == b ? true : false;
}最后一次优化:
public static boolean compare(int a, int b) {
return a == b;
}例4,需求:定义功能,对两个数进行比较,获取较大的数。
解:
public static int getMax(int a, int b) {
return (a > b) ? a : b;
}练习一:定义一个功能,用于打印矩形。
解:
- 确定结果:没有,因为直接打印,所以返回值类型是void
- 有未知内容吗?:有,2个,因为矩形的行和列不确定
public static void draw(int row, int col) {
for (int x = 0; x < row; x++) {
for (int y = 0; y < col; y++) {
System.out.print("*");
}
System.out.println();
}
}练习二:定义一个打印99乘法表功能的函数。
解:
public static void print99() {
for (int x = 1; x <= 9; x++) {
for (int y = 1; y <= x; y++) {
System.out.print(y+"*"+x+"="+y*x+"\t");
}
System.out.println();
}
}函数的重载(overload)
重载的概念:在同一个类中,允许存在一个以上的同名函数,只要它们的参数个数或者参数类型不同即可。
重载的特点:与返回值类型无关,只看参数列表。
重载的好处:方便于阅读,优化了程序设计。
例,定义一个加法运算,获取两个整数的和。
public static int add(int x, int y) {
return x + y;
}定义一个加法运算,获取三个整数的和:
public static int add(int x, int y, int z) {
return x + y + z;
}这两段代码就是函数的重载,当然函数中可调用函数,所以以上代码可以写成:
public static int add(int x, int y, int z) {
return add(x, y) + z;
}例,定义一个打印99乘法表功能的函数,很简单,我们已经做了,代码如下:
public static void print99() {
for (int x = 1; x <= 9; x++) {
for (int y = 1; y <= x; y++) {
System.out.print(y+"*"+x+"="+y*x+"\t");
}
System.out.println();
}
}此时,如果我们还要打印一个任意数乘法表功能的函数,我们可以这样做:
public static void print99(int num) {
for (int x = 1; x <= num; x++) {
for (int y = 1; y <= x; y++) {
System.out.print(y+"*"+x+"="+y*x+"\t");
}
System.out.println();
}
}同理,打印99乘法表功能的函数,我们还可以写成:
public static void print99() {
print99(9);
}什么时候用重载?
答:当定义的功能相同,但参与运算的未知内容不同,那么,这时就定义一个函数名称以表示其功能,方便阅读,而通过参数列表的不同来区分多个同名函数。
注意:
- 参数列表是有顺序的
- 重载和返回值类型没关系
练习:以下哪些函数与函数void show(int a, char b, double c) {}重载?
a.
void show(int x, char y, double z) {}
b.
int show(int a, double c, char b) {}
c.
void show(int a, double c, char b) {}
d.
boolean show(int c, char b) {}
e.
void show(double c) {}
f.
double show(int x, char y, double z) {} 解:
a.
void show(int x, char y, double z) {} // 没有,因为和原函数一样
b.
int show(int a, double c, char b) {} // 重载,因为参数类型不同。注意:重载和返回值类型没有关系
c.
void show(int a, double c, char b) {} // 重载,因为参数类型不同。注意:重载和返回值类型没有关系
d.
boolean show(int c, char b) {} // 重载,因为参数个数不同
e.
void show(double c) {} // 重载,因为参数个数不同
f.
double show(int x, char y, double z) {} // 没有,这个函数不可以和给定函数同时存在于一个函数当中。数组
数组的定义:同一种类型数据的集合。其实数组就是一个容器。
数组的好处:可以自动给数组中的元素从0开始编号,方便操作这些元素。
数组的格式①:元素类型[] 数组名 = new 元素类型[元素个数或数组长度];
例,需求:想定义一个可以存储3个整数的容器。
int[] x = new int[3];JVM的内存划分
Java程序在运行时,需要在内存中分配空间。为了提高运算效率,对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。共划分了5个不同的区域:
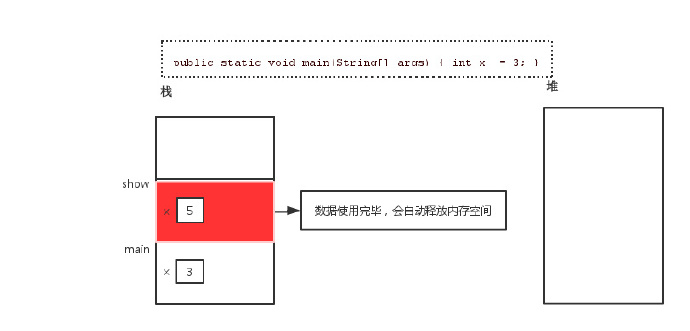
- 栈内存:用于存储局部变量(只要是在方法中定义的变量都是局部变量),一旦变量的生命周期结束,该变量就被释放。
- 堆内存:
- 数组和对象,通过
new建立的实例都存放在堆内存中 - 每一个实体都有内存地址值
- 堆内存的变量都有默认初始化值。不同类型不一样,int为0,double为0.0,boolean为false,char为’\u0000’(即空格)
- 实体不再被使用,会在不确定的时间内被垃圾回收器回收
- 数组和对象,通过
- 方法区:又叫方法和数据共享区。运行时期,class文件进入的地方
- 本地方法区:和系统底层的方法相关,JVM调用了系统中的功能
- 寄存器:给CPU使用,不多说。
数组内存结构
对于代码int x = 3,在内存中的情况为:
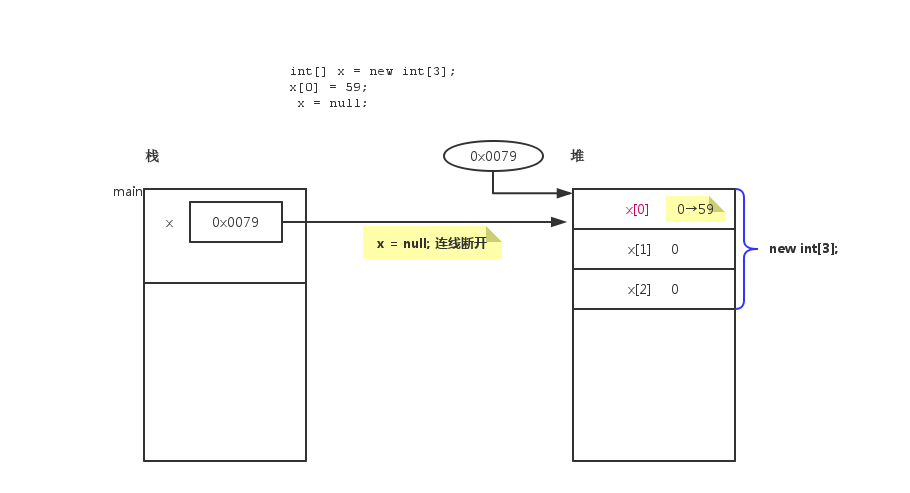
对于如下代码:
int[] x = new int[3];
x[0] = 59;
x = null;有如下内存分析图:
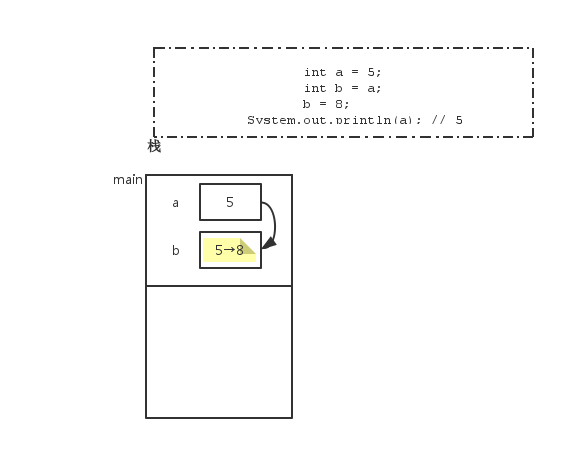
而对于以下代码来说:
int a = 5;
int b = a;
b = 8;
System.out.println(a); // 5内存结构图如下:
数组的格式②:元素类型[] 数组名 = new 元素类型[]{元素, 元素, ……};
例,
int[] arr = new int[] {3, 1, 6, 5, 4};又可简写成:
int[] arr = {3, 1, 6, 5, 4};数组操作常见问题
数组脚标越界异常(
ArrayIndexOutOfBoundsException)int[] arr = new int[3]; System.out.println(arr[3]); // ArrayIndexOutOfBoundsException: 3:操作数组时,访问到了数组中不存在的角标空指针异常(
NullPointerException)int[] arr = new int[3]; arr = null; System.out.println(arr[1]); // NullPointerException:空指针异常,当引用没有任何指向,值为null的情况,该引用还在用于操作实体。
数组的常见操作
获取数组中的元素,通常会用到遍历,数组中有一个属性可以直接获取到数组的元素个数:length,使用方式:数组名称.length。
例1,
int[] arr = {3, 6, 5, 1, 8, 9, 67};
System.out.println("length: "+arr.length);
for (int x = 0; x < arr.length; x++) {
System.out.println("arr["+x+"]="+arr[x]+";");
}此时,直接输出变量arr:
System.out.println(arr);会得到诸如[I@139a55的值,[表示是一个一维数组,I表示数组中的元素类型是int,139a55是有哈希算法算出来的地址值。
例2,定义一个功能,用于打印数组中的元素,元素间用逗号隔开。
public static void printArray(int[] arr) {
System.out.print("[");
for (int x = 0; x < arr.length; x++) {
if(x != arr.length - 1)
System.out.print(arr[x] + ", ");
else
System.out.println(arr[x]+"]");
}
}例3,给定一个数组,如{5, 1, 6, 4, 2, 8, 9},获取数组中的最大值,以及最小值。
获取最大值的原理图:

用文字描述即为:
- 获取最值需要进行比较。每一次比较都会有一个较大的值,因为该值不确定,通过一个变量进行存储。
- 让数组中的每一个元素都和这个变量中的值进行比较,如果大于了变量中的值,就用该变量记录较大值。
- 当所有的元素都比较完成,那么该变量中存储的就是数组中的最大值了。
解:
步骤:
- 定义变量,初始化为数组中的任意一个元素即可。
- 通过循环语句对数组进行遍历。
- 在遍历过程中定义判断条件,如果遍历到的元素比变量中的元素大,就赋值给该变量。
需要定义一个功能来完成,以便提高复用性。
- 明确结果:数组中的最大元素,int
- 未知内容:一个数组,int[]
public static int getMax(int[] arr) {
int max = arr[0];
for (int x = 1; x < arr.length; x++) {
if(arr[x] > max)
max = arr[x];
}
return max;
}获取最大值的另一种方式,可不可以将临时变量初始化为0呢?可以,这种方式其实是在初始化为数组中的任意一个角标。
public static int getMax_2(int[] arr) {
int max = 0;
for (int x = 1; x < arr.length; x++) {
if(arr[x] > arr[max])
max = x;
}
return arr[max];
}同理,获取数组中的最小值,代码如下:
public static int getMin(int[] arr) {
int min = 0;
for (int x = 1; x < arr.length; x++) {
if(arr[x] < arr[min])
min = x;
}
return arr[min];
}那如何获取double类型数组的最大值呢?
因为功能一致,所以定义相同函数名称,以重载形式存在。这里只略写。
public static double getMax(double[] arr) {
}例4,对给定数组进行排序,如{5, 1, 6, 4, 2, 8, 9}。
方式一:选择排序
选择排序的原理图:
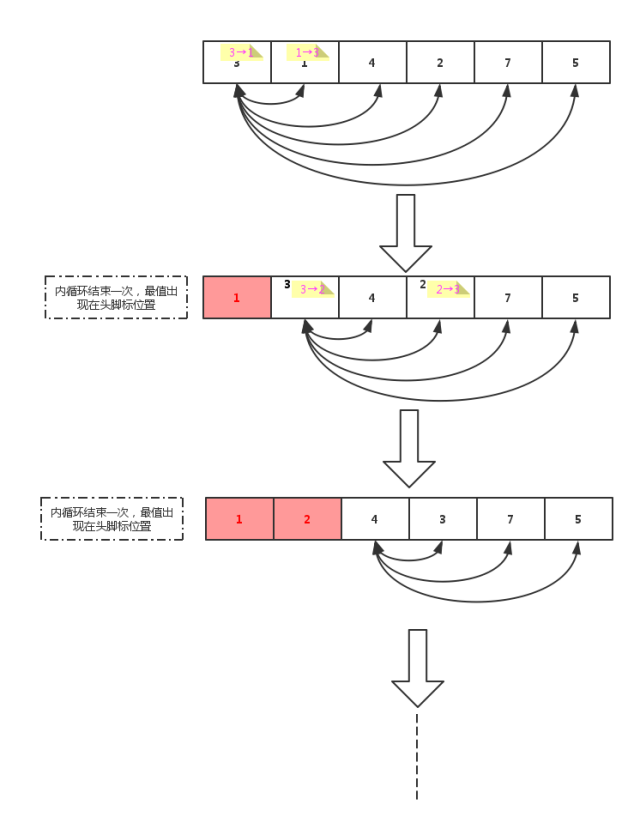
内循环结束一次,最值出现在头角标位置上。
public static void selectSort(int[] arr) {
for (int x = 0; x < arr.length - 1; x++) {
for (int y = x + 1; y < arr.length; y++) {
if(arr[x] > arr[y]) {
int temp = arr[x];
arr[x] = arr[y];
arr[y] = temp;
}
}
}
}方式二:冒泡排序
冒泡排序的原理图:
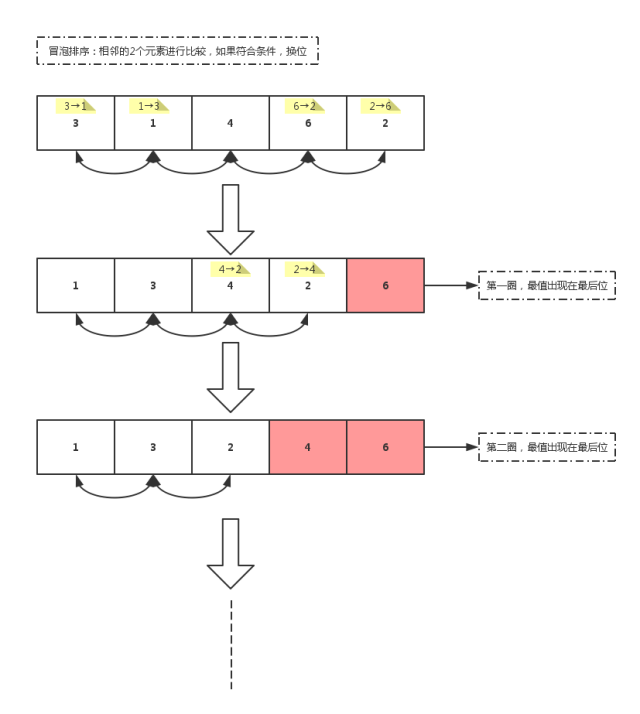
相邻的2个元素进行比较,如果符合条件,换位。第一圈,最值出现在最后位…
public static void bubbleSort(int[] arr) {
for (int x = 0; x < arr.length - 1; x++) {
for (int y = 0; y < arr.length - x - 1; y++) { // -x:让每一次比较的元素减少,-1:避免角标越界
if(arr[y] > arr[y+1]) {
int temp = arr[y];
arr[y] = arr[y+1];
arr[y+1] = temp;
}
}
}
}发现无论什么排序,都需要对满足条件的元素进行位置置换,所以可以把这部分相同的代码提取出来,单独封装成一个函数。
public static void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}那么,选择排序可以写为:
public static void selectSort(int[] arr) {
for (int x = 0; x < arr.length - 1; x++) {
for (int y = x + 1; y < arr.length; y++) {
if(arr[x] > arr[y]) {
swap(arr, x, y);
}
}
}
}冒泡排序可以写为:
public static void bubbleSort(int[] arr) {
for (int x = 0; x < arr.length - 1; x++) {
for (int y = 0; y < arr.length - x - 1; y++) { // -x:让每一次比较的元素减少,-1:避免角标越界
if(arr[y] > arr[y+1]) {
swap(arr, y, y+1);
}
}
}
}例5,数组的查找操作——折半查找。折半查找,可以提高效率,但是必须要保证该数组是有序的数组。
折半查找原理图:
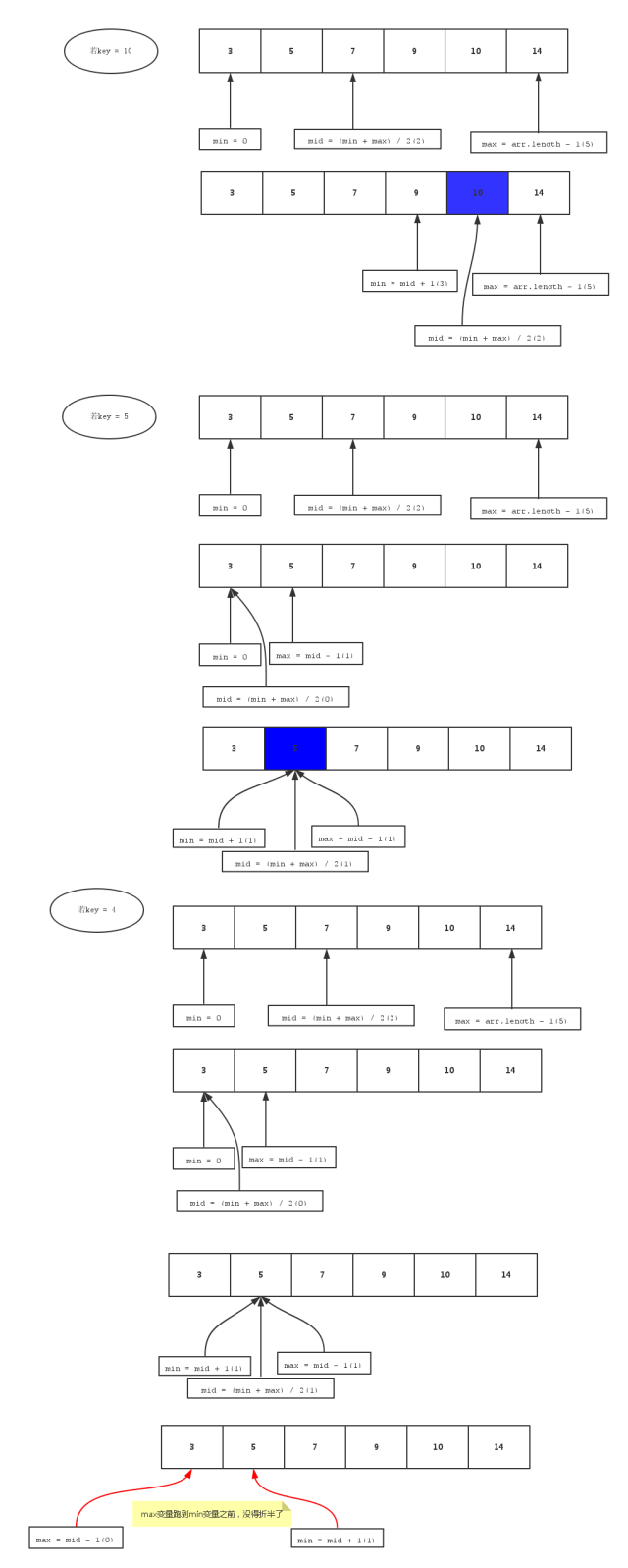
折半查找的第一种形式:
public static int halfSearch(int[] arr, int key) {
int min, max, mid;
min = 0;
max = arr.length - 1;
mid = (max + min) / 2;
while(arr[mid] != key) {
if(key > arr[mid])
min = mid + 1;
else if(key < arr[mid])
max = mid - 1;
if(min > max)
return -1;
mid = (max + min) / 2;
}
return mid;
}折半查找的第二种形式:
public static int halfSearch_2(int[] arr, int key) {
int min = 0, max = arr.length - 1, mid;
while(min <= max) {
mid = (max + min) >> 1;
if(key > arr[mid])
min = mid + 1;
else if(key < arr[mid])
max = mid - 1;
else
return mid;
}
return -1;
}举一反三:有一个有序的数组,想要将一个元素插入到该数组中,还要保证该数组是有序的,问如何获取该位置?
原理:如何获取该元素在数组中的位置。使用折半查找。
public static int getIndex(int[] arr, int key) {
int min = 0, max = arr.length - 1, mid;
while(min <= max) {
mid = (max + min) >> 1;
if(key > arr[mid])
min = mid + 1;
else if(key < arr[mid])
max = mid - 1;
else
return mid;
}
return min;
}例6,进制转换。
如,十进制→二进制
public static void toBin(int num) {
StringBuffer sb = new StringBuffer();
while(num > 0) {
// System.out.println(num%2);
sb.append(num%2);
num /= 2;
}
System.out.println(sb.reverse());
}该方法有局限性,即转换的十进制数只能是正数,还有此刻我们并不熟悉StringBuffer类。
十进制→十六进制
public static void toHex(int num) {
StringBuffer sb = new StringBuffer();
for (int x = 0; x < 8; x++) {
int temp = num & 15;
if(temp > 9)
// System.out.println((char)(temp - 10 + 'A'));
sb.append((char)(temp - 10 + 'A'));
else
// System.out.println(temp);
sb.append(temp);
num = num >>> 4;
}
System.out.println(sb.reverse());
}我们使用查表法进一步优化。如对于十进制→十六进制。查表法,将所有的元素临时存储起来,建立对应关系,每一次&15后的值作为索引去查建立好的表,就可以找对应的元素,这样比-10+'A'简单的多。
这个表怎么建立呢?可以通过数组的形式来定义。
public static void toHex(int num) {
char[] chs = {'0', '1', '2', '3',
'4', '5', '6', '7',
'8', '9', 'A', 'B',
'C', 'D', 'E', 'F'};
// 定义一个临时容器
char[] arr = new char[8]; // '\u0000',u指代unicode码,空格
int pos = arr.length;
while(num != 0) {
int temp = num & 15;
// System.out.println(chs[temp]);
arr[--pos] = chs[temp];
num = num >>> 4;
}
System.out.println("pos = " + pos);
// 存储数据的arr数组遍历
for (int x = pos; x < arr.length; x++) {
System.out.print(arr[x]+",");
}
}那么接下来,就该十进制→二进制了。
public static void toBin(int num) {
// 定义二进制的表
char[] chs = {'0', '1'};
// 定义一个临时存储容器
char[] arr = new char[32];
// 定义一个操作数组的指针
int pos = arr.length;
while(num != 0) {
int temp = num & 1;
arr[--pos] = chs[temp];
num = num >>> 1;
}
for (int x = pos; x < arr.length; x++) {
System.out.print(arr[x]);
}
}最后,做进制转换的最优优化:
// 十进制→二进制
public static void toBin(int num) {
trans(num, 1, 1);
}
// 十进制→八进制
public static void toOtc(int num) {
trans(num, 7, 3);
}
// 十进制→十六进制
public static void toHax(int num) {
trans(num, 15, 4);
}
public static void trans(int num, int base, int offset) {
if(num == 0) {
System.out.println(0);
return;
}
char[] chs = {'0', '1', '2', '3',
'4', '5', '6', '7',
'8', '9', 'A', 'B',
'C', 'D', 'E', 'F'};
char[] arr = new char[32];
int pos = arr.length;
while(num != 0) {
int temp = num & base;
arr[--pos] = chs[temp];
num = num >>> offset;
}
for (int x = pos; x < arr.length; x++) {
System.out.print(arr[x]);
}
}二维数组
格式1:int[][] arr = new int[3][2];
定义了名称为arr的二维数组,二维数组中有3个一维数组,每一个一维数组中有2个元素,一维数组的名称分别为arr[0], arr[1], arr[2],给第一个一维数组1脚标位赋值为78写法是: arr[0][1] = 78;
对于如下代码:
int[][] arr = new int[2][3];
arr[1][2] = 8;
arr[0][3] = 90;
System.out.println(arr); // [[I@139a55(二维数组实体) 139a55(哈希值,实体在内存中存放的位置)
System.out.println(arr[0]); // [I@1db9742(一维数组实体)
System.out.println(arr[0][1]); // 0(一维数组中的元素)格式2:int[][] arr = new int[3][];
二维数组中有3个一维数组, 每个一维数组都是默认初始化值null,可以对这三个一维数组分别进行初始化。
int[][] arr = new int[3][];
System.out.println(arr[0]); // null
arr[0] = new int[3];
arr[1] = new int[1];
arr[2] = new int[2];
System.out.println(arr); // [[I@139a55
System.out.println(arr.length); // 打印的是二维数组的长度:3
System.out.println(arr[0].length); // 打印二维数组中第1个一维数组的长度内存图如下:
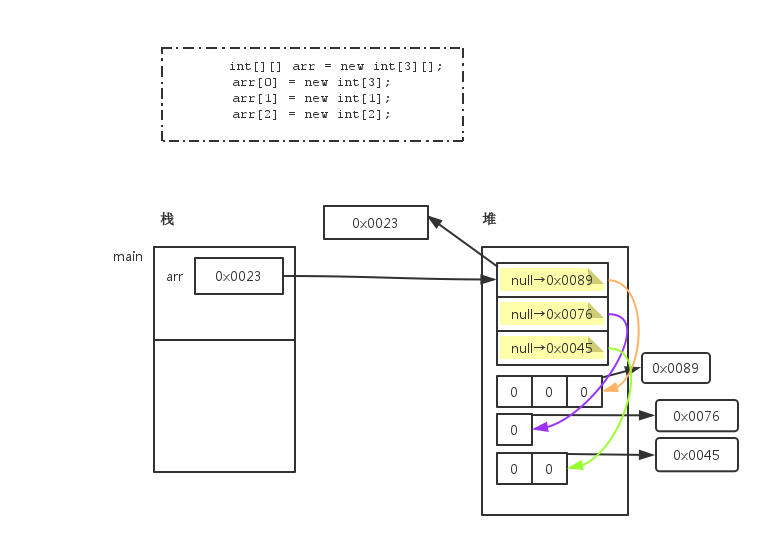
格式3:int[][] arr = {{3,8,2},{2,7},{9,0,1,6}};
练习:从以下代码可以看出哪个选项正确与否?
int[] x, y[]; a.
x[0] = y;
b.
y[0] = x;
c.
y[0][0] = x;
d.
x[0][0] = y;
e.
y[0][0] = x[0];
f.
x = y; 解:一维数组可以写为:
int[] x;
int x[];二维数组可以写为:
int[][] y;
int y[][];
int[] y[]; // 注意这种特殊写法所以:
a.
x[0] = y; // error
b.
y[0] = x; // yes
c.
y[0][0] = x; // error
d.
x[0][0] = y; // error
e.
y[0][0] = x[0]; // yes
f.
x = y; // error














 5707
5707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











