







一、调用大概过程:
TokenizerChain类的createComponents(String fieldName, Reader aReader)会调用在schema中注册的分词器工厂类和过滤器的工厂类分别调用工厂类的create()方法创建对应的实例,代码如下:
protected TokenStreamComponents createComponents(String fieldName, Reader aReader) {
Tokenizer tk = tokenizer.create( aReader );
TokenStream ts = tk;
for (TokenFilterFactory filter : filters) {
ts = filter.create(ts);
}
return new TokenStreamComponents(tk, ts);
}AnalysisRequestHandlerBase类中的 getQueryTokenSet(String query, Analyzer analyzer)方法会调用分词器和过滤器的incrementToken()方法,对字符串进行分词过滤,源码如下:
protected Set<BytesRef> getQueryTokenSet(String query, Analyzer analyzer) {
try {
final Set<BytesRef> tokens = new HashSet<BytesRef>();
final TokenStream tokenStream = analyzer.tokenStream("", new StringReader(query));
final TermToBytesRefAttribute bytesAtt = tokenStream.getAttribute(TermToBytesRefAttribute.class);
final BytesRef bytes = bytesAtt.getBytesRef();
tokenStream.reset();
while (tokenStream.incrementToken()) {
bytesAtt.fillBytesRef();
tokens.add(BytesRef.deepCopyOf(bytes));
}
tokenStream.end();
tokenStream.close();
return tokens;
} catch (IOException ioe) {
throw new RuntimeException("Error occured while iterating over tokenstream", ioe);
}
}二、自定义三元分词器ThreeTokenizer.java
主要借鉴lucene自带的CJKTokenizer分词器,实现对中文字符串实现三元分词,主要代码如下:
@Override
public boolean incrementToken() throws IOException {
clearAttributes();
/** how many character(s) has been stored in buffer */
while(true) { // loop until we find a non-empty token
int length = 0;
/** the position used to create Token */
int start = offset;
while(true) { // loop until we've found a full token
/** current character */
char c;
/** unicode block of current character for detail */
Character.UnicodeBlock ub;
offset++;
if(bufferIndex >= dataLen) {
dataLen = input.read(ioBuffer);
bufferIndex = 0;
}
if(dataLen == -1) {
if(length > 0) {
if(preIsTokened == true) {
length = 0;
preIsTokened = false;
} else {
offset--;
}
break;
} else {
offset--;
return false;
}
} else {
//get current character
c = ioBuffer[bufferIndex++];
//get the UnicodeBlock of the current character
ub = Character.UnicodeBlock.of(c);
}
//if the current character is ASCII or Extend ASCII
if((ub == Character.UnicodeBlock.BASIC_LATIN) || (ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS)) {
if(ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS) {
int i = (int) c;
if(i >= 65281 && i <= 65374) {
// convert certain HALFWIDTH_AND_FULLWIDTH_FORMS to BASIC_LATIN
i = i - 65248;
c = (char) i;
}
}
// if the current character is a letter or "_" "+" "#"
if(Character.isLetterOrDigit(c) || ((c == '_') || (c == '+') || (c == '#'))) {
if(length == 0) {
// "javaC1C2C3C4linux" <br>
// ^--: the current character begin to token the ASCII
// letter
start = offset - 1;
} else if(tokenType == THREE_TOKEN_TYPE) {
// "javaC1C2C3C4linux" <br>
// ^--: the previous non-ASCII
// : the current character
offset--;
bufferIndex--;
if(preIsTokened == true) {
// there is only one non-ASCII has been stored
length = 0;
preIsTokened = false;
break;
} else {
break;
}
}
// store the LowerCase(c) in the buffer
buffer[length++] = Character.toLowerCase(c);
tokenType = SINGLE_TOKEN_TYPE;
// break the procedure if buffer overflowed!
if(length == MAX_WORD_LEN) {
break;
}
} else if(length > 0) {
if(preIsTokened == true) {
length = 0;
preIsTokened = false;
} else {
break;
}
}
} else {
// non-ASCII letter, e.g."C1C2C3C4"
if(Character.isLetter(c)) {
if(length == 0) {
start = offset - 1;
buffer[length++] = c;
tokenType = THREE_TOKEN_TYPE;
} else {
if(tokenType == SINGLE_TOKEN_TYPE) {
offset--;
bufferIndex--;
//return the previous ASCII characters
break;
} else {
buffer[length++] = c;
tokenType = THREE_TOKEN_TYPE;
if(length == 3) {
offset -= 2;
bufferIndex -= 2;
preIsTokened = true;
break;
}
}
}
} else if(length > 0) {
if(preIsTokened == true) {
// empty the buffer
length = 0;
preIsTokened = false;
} else {
break;
}
}
}
}
if(length > 0) {
termAtt.copyBuffer(buffer, 0, length);
offsetAtt.setOffset(correctOffset(start), correctOffset(start + length));
typeAtt.setType(TOKEN_TYPE_NAMES[tokenType]);
return true;
} else if(dataLen == -1) {
offset--;
return false;
}
// Cycle back and try for the next token (don't
// return an empty string)
}
}分词器的工厂类:
public class ThreeTokenizerFactory extends TokenizerFactory {
@Override
public Tokenizer create(Reader input) {
return new ThreeTokenizer(input);
}
}三、自定义停用词过滤器CnFilter.java
对分词器流出的词元进行过滤,去除指定词元,代码如下:
public class CnFilter extends TokenFilter {
private static final Logger logger = LoggerFactory.getLogger(CnFilter.class);
public final static String STOP_WORDS_FILE = "./stopwords.txt";
public final static int START_SIZE = 10;
private CharArraySet stopSet;
private CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
protected CnFilter(TokenStream input) {
super(input);
try {
stopSet = new CharArraySet(Version.LUCENE_42, START_SIZE, false);
//read stop words from stopFile
WordlistLoader.getWordSet(new FileReader(STOP_WORDS_FILE), stopSet);
} catch(FileNotFoundException e) {
logger.error("can't find the stopFile");
e.printStackTrace();
} catch(IOException e) {
logger.error("reading stopFile,IOException..");
e.printStackTrace();
}
}
@Override
public boolean incrementToken() throws IOException {
while(input.incrementToken()) {
char text[] = termAtt.buffer();
int termLength = termAtt.length();
if(!stopSet.contains(text, 0, termLength)) {
switch(Character.getType(text[0])) {
case Character.LOWERCASE_LETTER:
case Character.UPPERCASE_LETTER:
// English word/token should larger than 1 character.
if(termLength > 1) {
return true;
}
break;
case Character.OTHER_LETTER:
// One Chinese character as one Chinese word.
// Chinese word extraction to be added later here.
return true;
}
}
}
return false;
}
}对应工厂类:
public class CnFilterFactory extends TokenFilterFactory {
@Override
public TokenStream create(TokenStream input) {
return new CnFilter(input);
}
}使用的停用词文本为:
mm
蛋糕卡四、分词效果如下:
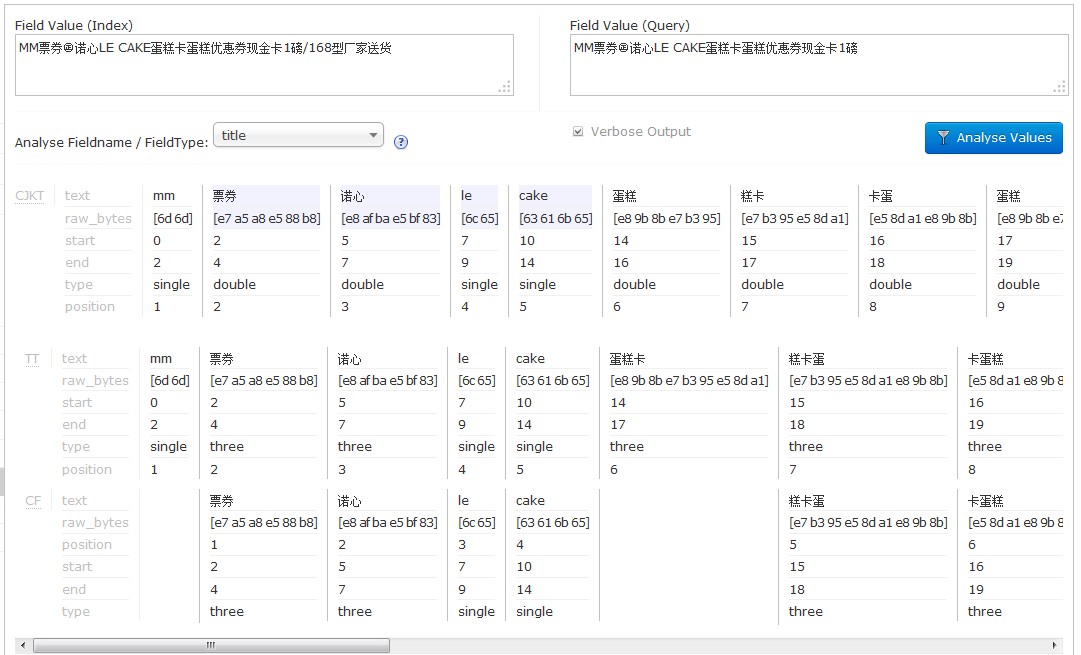
index使用cjk分词,query使用自定义的三元分词+自定义停用词过滤器
*************************************************************************************************************************************************************************************************************************
*************************************************************************************************************************************************************************************************************************
实际使用时,index可以使用一元+二元 查询使用二元分词。
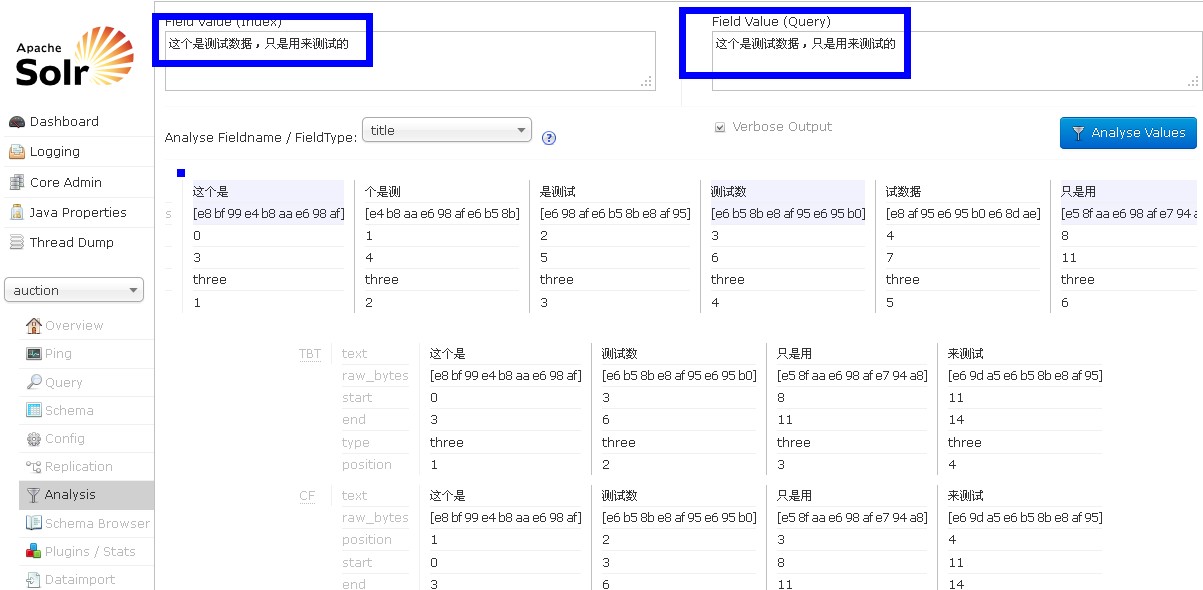
五、不连续三元分词
只需注释掉ThreeTokenizer.java 部分代码即可,如下:
if(length == 3) {
//offset -= 2;
//bufferIndex -= 2;
preIsTokened = true;
break;
}使用三元连续分词和三元非连续分词效果如下:















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









