







VQA: Given an image and a question in natural language, it requires reasoning over visual elements of the image and general knowledge to infer the correct answer.
和基于对象检测的任务区别
- 对象识别-对图像主要对象进行分类
目标检测-通过对图像中每个对象实例放置bbox进行定位特定的语义概念
语义分割-通过对每个像素分类为特定语义类
实例分割(Instance segmentation)-区分同一语义类不同实例

但语义分割和实例分割仍存在label ambiguity的问题,比如

图中“黄叉”位置取"bag",“black”,"person"都没有问题,而且将它的位置标记为其中一个,都不足以了解三者在空间上的关系
和Textual QA区别
- 图像维度更高,会引入更多的噪声
- 图像没有文化那样的结构化和语法规则
- 文本往往是一个抽象的概念,而图像更加具体,让计算机从图像中理解抽象概念有难度
和Image captioning区别
- VQA需要对图片进行推理,而不是只是将图片进行结构化翻译
- VQA更容易评估,因为答案一般都是短语,而非像caption那样的长文本,难以评价
- 在不加限制情况下,image captioning往往会倾向于生成得分更高的表述
- image captioning的描述粒度可以由人工提前设定,而VQA中回答的粒度是由提出的问题决定的
难点
-
需要完全理解图像
-
一个健壮的VQA系统应该同时解决以下问题
Basic:- Object recognition - What is in the image?
- Object detection - Are there any cats in the image?
- Attribute classification - What color is the cat?
- Scene classification - Is it sunny?
- Counting - How many cats are in the image?
Senior:
- Spatial relationship - What is between the cat and the sofa?
- Common sense reasoning questions - Why is the girl crying?
Methods for VQA
1. Joint embedding approaches
利用CNNs&RNNs分别去学习图片和句子,然后联合编码,最后进行分类操作,或者生成长度不等的序列。

2. Attention mechanisms
该方法是从image captioning中借鉴而来,相比于对全局进行学习,更加关注特定区域,使得模型更加关注关键图像的部位

3. Compositional models
针对不同的问题用组合模型设计计算方法
3.1 Neural Module Networks

将问题进行语法分析,然后判断需要用的模块
3.2 Dynamic Memory Networks

有四个模块,表征图像的input module、表征问题的question module、作为内存的episodic memory module和产生答案的answer module
4. external knowledge
利用外部数据,获取先验知识,构建知识库
5. 基于贝叶斯方法
The idea behind bayesian approaches is to model co-occurrence statistics of both the question and the image features, as a way of inferring relationships between questions and images.
例如 Kafle和Kanan的Answer-Type Prediction for Visual Question Answering,作者给出了问题特征和答案类型的图像特征概率,引文他们观察到给定一个问题,答案的类型可以经常预测。比如,"How many players are in the image?"需要回答数字
Datasets


GQA
评估指标
- Classic accuracy
- WUPS
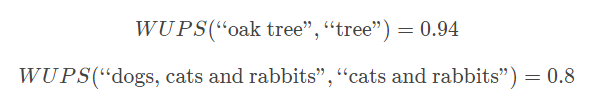
建议低于0.9的都乘个0.1
很多时候比classic accuracy更加适合,但由于依赖语义相似性,所以如果基础试试是“黑色”或“绿色”,则“红色”答案将具有非常高的分数。 - 对于多个独立的ground truth答案
例如在VQA数据集中,一个问题有多个GT答案,可以看given answer是否和more frequent answer匹配,或者是至少和其中一个GT答案匹配 - 人工评判
应用
- 帮助盲人和视障人士
- 应用到图像检索系统
- 促进CV和NLP发展
参考文献:
[1]Visual Question Answering: A Survey of Methods and Datasets
[2]Visual Question Answering
[3]一文看懂深度学习中的VQA(视觉问答)技术
[4]Visual Question Answering: Datasets, Algorithms, and Future Challenges















 6969
6969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









