










写在前面:本系列文章先把各个层对应的文件源码剖析一遍,最后再穿插起来,理清整个协议栈网络数据包的上下传送通道,从整体实现上进行把握。
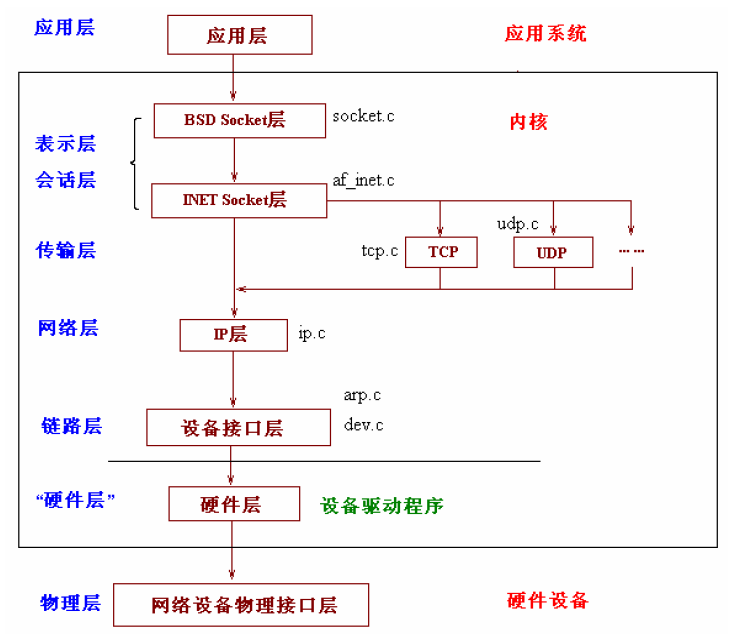
图片来源于《Linux 内核网络栈源代码情景分析》
更上层函数:tcp socket函数介绍。本篇则是介绍BSD Socket层。其对应函数集定义在socket.c 文件中,阅读源码后,你会发现这些函数都是层层嵌套调用表现出了上下层之间的关系。内核版本:Linux 1.2.13
源码剖析:
为方便大家理清思路,先介绍几个中间函数。建议:像这些大型软件项目,函数内通常还会调用一些公用的基础类的工具函数,我们在阅读源码时,应该先弄清楚这些函数,这样当阅读对应函数时,能很好地把握该函数的内部细节。
/*下面两个函数实现地址用户空间和内核空间地址之间的相互移动*/
//从uaddr拷贝ulen大小的数据到kaddr
static int move_addr_to_kernel(void *uaddr, int ulen, void *kaddr)
{
int err;
if(ulen<0||ulen>MAX_SOCK_ADDR)
return -EINVAL;
if(ulen==0)
return 0;
//检查用户空间的指针所指的指定大小存储块是否可读
if((err=verify_area(VERIFY_READ,uaddr,ulen))<0)
return err;
memcpy_fromfs(kaddr,uaddr,ulen);//实质是memcpy函数
return 0;
}
//注意的是,从内核拷贝数据到用户空间是值-结果参数
//ulen这个指向某个整数变量的指针,当函数被调用的时候,它告诉内核需要拷贝多少
//函数返回时,该参数作为一个结果,告诉进程,内核实际拷贝了多少信息
static int move_addr_to_user(void *kaddr, int klen, void *uaddr, int *ulen)
{
int err;
int len;
//判断ulen指向的存储块是否可写,就是判断ulen是否可作为左值
if((err=verify_area(VERIFY_WRITE,ulen,sizeof(*ulen)))<0)
return err;
len=get_fs_long(ulen);//len = *ulen,ulen作为值传入,告诉要拷贝多少数据
if(len>klen)
len=klen;//供不应求,按供的算。实际拷贝的数据
if(len<0 || len> MAX_SOCK_ADDR)
return -EINVAL;
if(len)
{
//判断uaddr用户空间所指的存储块是否可写
if((err=verify_area(VERIFY_WRITE,uaddr,len))<0)
return err;
memcpy_tofs(uaddr,kaddr,len);//实质是调用memcpy
}
put_fs_long(len,ulen);//*ulen = len,作为结果返回,即实际拷贝了多少数据
return 0;
}static inline unsigned long get_user_long(const int *addr)
{
return *addr;
}
#define get_fs_long(addr) get_user_long((int *)(addr))为套接字分配文件描述符,套接字其实同普通的文件描述符差不多,分配文件描述符的同时需要一个file结构,file结构中f_inode字段指向inode(这里的形参)
/*
* 为网络套接字分配一个文件描述符
*/
static int get_fd(struct inode *inode)
{
int fd;
struct file *file;
/*
* Find a file descriptor suitable for return to the user.
*/
file = get_empty_filp();//分配文件对象,文件描述符对应实体,file结构体指示一个打开的文件,filp:file pointer
if (!file)
return(-1);
//找到可用的文件描述符
for (fd = 0; fd < NR_OPEN; ++fd)
if (!current->files->fd[fd])
break;
//没有空闲可用的文件描述符,则退出
if (fd == NR_OPEN)
{
file->f_count = 0;
return(-1);
}
//在文件描述符集合中删除一个新的文件描述符
FD_CLR(fd, ¤t->files->close_on_exec);
current->files->fd[fd] = file;//赋值,挂钩
file->f_op = &socket_file_ops;//指定操作函数集,实现了网络操作的普通文件接口
file->f_mode = 3;//权限
file->f_flags = O_RDWR;//标志,可读可写
file->f_count = 1;//引用计数
file->f_inode = inode;//与文件inode建立联系,inode为对文件的索引
if (inode)
inode->i_count++;//inode的引用计数也要增1
file->f_pos = 0;//偏移值
return(fd);
}
每个文件描述符都与对应的inode结构关联,通过文件描述符可以找到file结构,通过file结构可以找到inode,而socket结构又是作为inode结构中的一个变量,反过来,inode也是作为socket结构的一个变量,分配套接字时,两者之间需要建立关联,见sock_alloc()。
/*
* 通过inode结构查找对应的socket结构
*/
inline struct socket *socki_lookup(struct inode *inode)
{
return &inode->u.socket_i;//socket结构是作为inode结构中的一个变量
}
/*
* 给定文件描述符返回socket结构以及file结构指针
*/
static inline struct socket *sockfd_lookup(int fd, struct file **pfile)
{
struct file *file;
struct inode *inode;
//有效性检查,并从文件描述符中得到对应的file结构
if (fd < 0 || fd >= NR_OPEN || !(file = current->files->fd[fd]))
return NULL;
//得到对应inode结构
inode = file->f_inode;
if (!inode || !inode->i_sock)
return NULL;
if (pfile)
*pfile = file;//参数返回file结构指针
//返回inode对应的socket结构
return socki_lookup(inode);
}分配一个socket结构
/*
* 分配一个socket结构
*/
struct socket *sock_alloc(void)
{
struct inode * inode;
struct socket * sock;
inode = get_empty_inode();//分配一个inode对象
if (!inode)
return NULL;
//获得的inode结构的初始化
inode->i_mode = S_IFSOCK;
inode->i_sock = 1;
inode->i_uid = current->uid;
inode->i_gid = current->gid;
sock = &inode->u.socket_i;
sock->state = SS_UNCONNECTED;
sock->flags = 0;
sock->ops = NULL;
sock->data = NULL;
sock->conn = NULL;
sock->iconn = NULL;
sock->next = NULL;
sock->wait = &inode->i_wait;
sock->inode = inode;//回绑
sock->fasync_list = NULL;
sockets_in_use++;//系统当前使用的套接字数量加1
return sock;
}
释放(关闭)套接字
/*
* Release a socket.
*/
//释放对端的套接字
static inline void sock_release_peer(struct socket *peer)
{
peer->state = SS_DISCONNECTING;//状态切换到正在处理关闭连接
wake_up_interruptible(peer->wait);//唤醒指定的注册在等待队列上的进程
sock_wake_async(peer, 1);//异步唤醒,涉及到套接字状态的改变,需要通知相应进程进行某种处理
}
/*
* 释放(关闭)一个套接字
*/
void sock_release(struct socket *sock)
{
int oldstate;
struct socket *peersock, *nextsock;
//只要套接字不是出于未连接状态,就将其置为正在处理关闭连接状态
if ((oldstate = sock->state) != SS_UNCONNECTED)
sock->state = SS_DISCONNECTING;
/*
* Wake up anyone waiting for connections.
*/
//iconn只用于服务器端,表示等待连接但尚未完成连接的客户端socket结构链表
for (peersock = sock->iconn; peersock; peersock = nextsock)
{
nextsock = peersock->next;
sock_release_peer(peersock);
}
/*
* Wake up anyone we're connected to. First, we release the
* protocol, to give it a chance to flush data, etc.
*/
//如果该套接字已连接,peersock指向其连接的服务器端套接字
peersock = (oldstate == SS_CONNECTED) ? sock->conn : NULL;
//转调用release函数
if (sock->ops)
sock->ops->release(sock, peersock);
//释放对端套接字
if (peersock)
sock_release_peer(peersock);
--sockets_in_use; /* 数量减1 */
iput(SOCK_INODE(sock));
}/*
* Internal representation of a socket. not all the fields are used by
* all configurations:
*
* server client
* conn client connected to server connected to
* iconn list of clients -unused-
* awaiting connections
* wait sleep for clients, sleep for connection,
* sleep for i/o sleep for i/o
*/
//该结构表示一个网络套接字
struct socket {
short type; /* 套接字所用的流类型*/
socket_state state;//套接字所处状态
long flags;//标识字段,目前尚无明确作用
struct proto_ops *ops; /* 操作函数集指针 */
/* data保存指向‘私有'数据结构指针,在不同的域指向不同的数据结构 */
//在INET域,指向sock结构,UNIX域指向unix_proto_data结构
void *data;
//下面两个字段只用于UNIX域
struct socket *conn; /* 指向客户端连接的服务器端套接字 */
struct socket *iconn; /* 指向正等待连接的客户端 */
struct socket *next;//链表
struct wait_queue **wait; /* 等待队列 */
struct inode *inode;//inode结构指针
struct fasync_struct *fasync_list; /* 异步唤醒链表结构 */
};
创建套接字socket,socket
/*
* 系统调用,创建套接字socket。涉及到socket结构的创建.
*/
static int sock_socket(int family, int type, int protocol)
{
int i, fd;
struct socket *sock;
struct proto_ops *ops;
/* 匹配应用程序调用socket()函数时指定的协议 */
for (i = 0; i < NPROTO; ++i)
{
if (pops[i] == NULL) continue;
if (pops[i]->family == family)
break;
}
//没有匹配的协议,则出错退出
if (i == NPROTO)
{
return -EINVAL;
}
ops = pops[i];
/*
* Check that this is a type that we know how to manipulate and
* the protocol makes sense here. The family can still reject the
* protocol later.
*/
//套接字类型检查
if ((type != SOCK_STREAM && type != SOCK_DGRAM &&
type != SOCK_SEQPACKET && type != SOCK_RAW &&
type != SOCK_PACKET) || protocol < 0)
return(-EINVAL);
/*
* Allocate the socket and allow the family to set things up. if
* the protocol is 0, the family is instructed to select an appropriate
* default.
*/
//分配套接字结构
if (!(sock = sock_alloc()))
{
printk("NET: sock_socket: no more sockets\n");
return(-ENOSR); /* Was: EAGAIN, but we are out of
system resources! */
}
//指定对应类型,协议,以及操作函数集
sock->type = type;
sock->ops = ops;
//分配下层sock结构,sock结构是比socket结构更底层的表示一个套接字的结构
//前面博文有说明:http://blog.csdn.net/wenqian1991/article/details/21740945
//socket是通用的套接字结构体,而sock与具体使用的协议相关
if ((i = sock->ops->create(sock, protocol)) < 0)
{
sock_release(sock);
return(i);
}
//分配一个文件描述符并在后面返回给应用层序作为以后的操作句柄
if ((fd = get_fd(SOCK_INODE(sock))) < 0)
{
sock_release(sock);
return(-EINVAL);
}
return(fd);
}
/*
* Bind a name to a socket. Nothing much to do here since it's
* the protocol's responsibility to handle the local address.
*
* We move the socket address to kernel space before we call
* the protocol layer (having also checked the address is ok).
*/
//建议对于理解这类系统调用函数,先看看应用层的对应函数,如bind,listen等
//bind函数对应的BSD层函数,用于绑定一个本地地址,服务器端
//umyaddr表示需要绑定的地址结构,addrlen表示改地址结构的长度
static int sock_bind(int fd, struct sockaddr *umyaddr, int addrlen)
{
struct socket *sock;
int i;
char address[MAX_SOCK_ADDR];
int err;
//套接字参数有效性检查
if (fd < 0 || fd >= NR_OPEN || current->files->fd[fd] == NULL)
return(-EBADF);
//获取fd对应的socket结构
if (!(sock = sockfd_lookup(fd, NULL)))
return(-ENOTSOCK);
//将地址从用户缓冲区复制到内核缓冲区
if((err=move_addr_to_kernel(umyaddr,addrlen,address))<0)
return err;
//转调用bind指向的函数
if ((i = sock->ops->bind(sock, (struct sockaddr *)address, addrlen)) < 0)
{
return(i);
}
return(0);
}
/*
* Perform a listen. Basically, we allow the protocol to do anything
* necessary for a listen, and if that works, we mark the socket as
* ready for listening.
*/
//服务器端监听客户端的连接请求
//fd表示bind后的套接字,backlog表示排队的最大连接个数
//listen函数把一个未连接的套接字转换为一个被动套接字,
//指示内核应接受该套接字的连接请求
static int sock_listen(int fd, int backlog)
{
struct socket *sock;
if (fd < 0 || fd >= NR_OPEN || current->files->fd[fd] == NULL)
return(-EBADF);
if (!(sock = sockfd_lookup(fd, NULL)))
return(-ENOTSOCK);
//前提是没有建立连接
if (sock->state != SS_UNCONNECTED)
{
return(-EINVAL);
}
//调用底层实现函数
if (sock->ops && sock->ops->listen)
sock->ops->listen(sock, backlog);
sock->flags |= SO_ACCEPTCON;//设置标识字段
return(0);
}
服务器接收请求,accept
/*
* For accept, we attempt to create a new socket, set up the link
* with the client, wake up the client, then return the new
* connected fd. We collect the address of the connector in kernel
* space and move it to user at the very end. This is buggy because
* we open the socket then return an error.
*/
//用于服务器接收一个客户端的连接请求,这里是值-结果参数,之前有说到
//fd 为监听后套接字。最后返回一个记录了本地与目的端信息的套接字
//upeer_sockaddr用来返回已连接客户的协议地址,如果对协议地址不感兴趣就NULL
static int sock_accept(int fd, struct sockaddr *upeer_sockaddr, int *upeer_addrlen)
{
struct file *file;
struct socket *sock, *newsock;
int i;
char address[MAX_SOCK_ADDR];
int len;
if (fd < 0 || fd >= NR_OPEN || ((file = current->files->fd[fd]) == NULL))
return(-EBADF);
if (!(sock = sockfd_lookup(fd, &file)))
return(-ENOTSOCK);
if (sock->state != SS_UNCONNECTED)//socket各个状态的演变是一步一步来的
{
return(-EINVAL);
}
//这是tcp连接,得按步骤来
if (!(sock->flags & SO_ACCEPTCON))//没有listen
{
return(-EINVAL);
}
//分配一个新的套接字,用于表示后面可进行通信的套接字
if (!(newsock = sock_alloc()))
{
printk("NET: sock_accept: no more sockets\n");
return(-ENOSR); /* Was: EAGAIN, but we are out of system
resources! */
}
newsock->type = sock->type;
newsock->ops = sock->ops;
//套接字重定向,目的是初始化新的用于数据传送的套接字
//继承了第一参数传来的服务器的IP和端口号信息
if ((i = sock->ops->dup(newsock, sock)) < 0)
{
sock_release(newsock);
return(i);
}
//转调用inet_accept函数
i = newsock->ops->accept(sock, newsock, file->f_flags);
if ( i < 0)
{
sock_release(newsock);
return(i);
}
//分配一个文件描述符,用于以后的数据传送
if ((fd = get_fd(SOCK_INODE(newsock))) < 0)
{
sock_release(newsock);
return(-EINVAL);
}
//返回通信远端的地址
if (upeer_sockaddr)
{//得到客户端地址,并复制到用户空间
newsock->ops->getname(newsock, (struct sockaddr *)address, &len, 1);
move_addr_to_user(address,len, upeer_sockaddr, upeer_addrlen);
}
return(fd);
}
客户端主动发起连接请求,connect
/*
* 首先将要连接的源端地址从用户缓冲区复制到内核缓冲区,之后根据套接字目前所处状态
* 采取对应措施,如果状态有效,转调用connect函数
*/
//这是客户端,表示客户端向服务器端发送连接请求
static int sock_connect(int fd, struct sockaddr *uservaddr, int addrlen)
{
struct socket *sock;
struct file *file;
int i;
char address[MAX_SOCK_ADDR];
int err;
if (fd < 0 || fd >= NR_OPEN || (file=current->files->fd[fd]) == NULL)
return(-EBADF);
if (!(sock = sockfd_lookup(fd, &file)))
return(-ENOTSOCK);
if((err=move_addr_to_kernel(uservaddr,addrlen,address))<0)
return err;
//根据状态采取对应措施
switch(sock->state)
{
case SS_UNCONNECTED:
/* This is ok... continue with connect */
break;
case SS_CONNECTED:
/* Socket is already connected */
if(sock->type == SOCK_DGRAM) /* Hack for now - move this all into the protocol */
break;
return -EISCONN;
case SS_CONNECTING:
/* Not yet connected... we will check this. */
/*
* FIXME: for all protocols what happens if you start
* an async connect fork and both children connect. Clean
* this up in the protocols!
*/
break;
default:
return(-EINVAL);
}
i = sock->ops->connect(sock, (struct sockaddr *)address, addrlen, file->f_flags);
if (i < 0)
{
return(i);
}
return(0);
}
所有网络调用函数都具有共同的入口函数 sys_socket
/*
* System call vectors. Since I (RIB) want to rewrite sockets as streams,
* we have this level of indirection. Not a lot of overhead, since more of
* the work is done via read/write/select directly.
*
* I'm now expanding this up to a higher level to separate the assorted
* kernel/user space manipulations and global assumptions from the protocol
* layers proper - AC.
*/
//本函数是网络栈专用操作函数集的总入口函数,主要是将请求分配,调用具体的底层函数进行处理
asmlinkage int sys_socketcall(int call, unsigned long *args)
{
int er;
switch(call)
{
case SYS_SOCKET://socket函数
er=verify_area(VERIFY_READ, args, 3 * sizeof(long));
if(er)
return er;
return(sock_socket(get_fs_long(args+0),
get_fs_long(args+1),//返回地址上的值
get_fs_long(args+2)));
case SYS_BIND://bind函数
er=verify_area(VERIFY_READ, args, 3 * sizeof(long));
if(er)
return er;
return(sock_bind(get_fs_long(args+0),
(struct sockaddr *)get_fs_long(args+1),
get_fs_long(args+2)));
case SYS_CONNECT://connect函数
er=verify_area(VERIFY_READ, args, 3 * sizeof(long));
if(er)
return er;
return(sock_connect(get_fs_long(args+0),
(struct sockaddr *)get_fs_long(args+1),
get_fs_long(args+2)));
case SYS_LISTEN://listen函数
er=verify_area(VERIFY_READ, args, 2 * sizeof(long));
if(er)
return er;
return(sock_listen(get_fs_long(args+0),
get_fs_long(args+1)));
case SYS_ACCEPT://accept函数
er=verify_area(VERIFY_READ, args, 3 * sizeof(long));
if(er)
return er;
return(sock_accept(get_fs_long(args+0),
(struct sockaddr *)get_fs_long(args+1),
(int *)get_fs_long(args+2)));
case SYS_GETSOCKNAME://getsockname函数
er=verify_area(VERIFY_READ, args, 3 * sizeof(long));
if(er)
return er;
return(sock_getsockname(get_fs_long(args+0),
(struct sockaddr *)get_fs_long(args+1),
(int *)get_fs_long(args+2)));
case SYS_GETPEERNAME://getpeername函数
er=verify_area(VERIFY_READ, args, 3 * sizeof(long));
if(er)
return er;
return(sock_getpeername(get_fs_long(args+0),
(struct sockaddr *)get_fs_long(args+1),
(int *)get_fs_long(args+2)));
case SYS_SOCKETPAIR://socketpair函数
er=verify_area(VERIFY_READ, args, 4 * sizeof(long));
if(er)
return er;
return(sock_socketpair(get_fs_long(args+0),
get_fs_long(args+1),
get_fs_long(args+2),
(unsigned long *)get_fs_long(args+3)));
case SYS_SEND://send函数
er=verify_area(VERIFY_READ, args, 4 * sizeof(unsigned long));
if(er)
return er;
return(sock_send(get_fs_long(args+0),
(void *)get_fs_long(args+1),
get_fs_long(args+2),
get_fs_long(args+3)));
case SYS_SENDTO://sendto函数
er=verify_area(VERIFY_READ, args, 6 * sizeof(unsigned long));
if(er)
return er;
return(sock_sendto(get_fs_long(args+0),
(void *)get_fs_long(args+1),
get_fs_long(args+2),
get_fs_long(args+3),
(struct sockaddr *)get_fs_long(args+4),
get_fs_long(args+5)));
case SYS_RECV://recv函数
er=verify_area(VERIFY_READ, args, 4 * sizeof(unsigned long));
if(er)
return er;
return(sock_recv(get_fs_long(args+0),
(void *)get_fs_long(args+1),
get_fs_long(args+2),
get_fs_long(args+3)));
case SYS_RECVFROM://recvfrom函数
er=verify_area(VERIFY_READ, args, 6 * sizeof(unsigned long));
if(er)
return er;
return(sock_recvfrom(get_fs_long(args+0),
(void *)get_fs_long(args+1),
get_fs_long(args+2),
get_fs_long(args+3),
(struct sockaddr *)get_fs_long(args+4),
(int *)get_fs_long(args+5)));
case SYS_SHUTDOWN://shutdown函数
er=verify_area(VERIFY_READ, args, 2* sizeof(unsigned long));
if(er)
return er;
return(sock_shutdown(get_fs_long(args+0),
get_fs_long(args+1)));
case SYS_SETSOCKOPT://setsockopt函数
er=verify_area(VERIFY_READ, args, 5*sizeof(unsigned long));
if(er)
return er;
return(sock_setsockopt(get_fs_long(args+0),
get_fs_long(args+1),
get_fs_long(args+2),
(char *)get_fs_long(args+3),
get_fs_long(args+4)));
case SYS_GETSOCKOPT://getsockopt函数
er=verify_area(VERIFY_READ, args, 5*sizeof(unsigned long));
if(er)
return er;
return(sock_getsockopt(get_fs_long(args+0),
get_fs_long(args+1),
get_fs_long(args+2),
(char *)get_fs_long(args+3),
(int *)get_fs_long(args+4)));
default:
return(-EINVAL);
}
}
下面再看看socket.c 即BSD socket层中的其余函数
/*
* Sockets are not seekable.
*/
static int sock_lseek(struct inode *inode, struct file *file, off_t offset, int whence)
{
return(-ESPIPE);
}
/*
* Read data from a socket. ubuf is a user mode pointer. We make sure the user
* area ubuf...ubuf+size-1 is writable before asking the protocol.
*/
static int sock_read(struct inode *inode, struct file *file, char *ubuf, int size)
{
struct socket *sock;
int err;
if (!(sock = socki_lookup(inode)))
{
printk("NET: sock_read: can't find socket for inode!\n");
return(-EBADF);
}
if (sock->flags & SO_ACCEPTCON)
return(-EINVAL);
if(size<0)
return -EINVAL;
if(size==0)
return 0;
if ((err=verify_area(VERIFY_WRITE,ubuf,size))<0)
return err;
return(sock->ops->read(sock, ubuf, size, (file->f_flags & O_NONBLOCK)));
}
/*
* Write data to a socket. We verify that the user area ubuf..ubuf+size-1 is
* readable by the user process.
*/
static int sock_write(struct inode *inode, struct file *file, char *ubuf, int size)
{
struct socket *sock;
int err;
if (!(sock = socki_lookup(inode)))
{
printk("NET: sock_write: can't find socket for inode!\n");
return(-EBADF);
}
if (sock->flags & SO_ACCEPTCON)
return(-EINVAL);
if(size<0)
return -EINVAL;
if(size==0)
return 0;
if ((err=verify_area(VERIFY_READ,ubuf,size))<0)
return err;
return(sock->ops->write(sock, ubuf, size,(file->f_flags & O_NONBLOCK)));
}
/*
* You can't read directories from a socket!
*/
static int sock_readdir(struct inode *inode, struct file *file, struct dirent *dirent,
int count)
{
return(-EBADF);
}
/*
* With an ioctl arg may well be a user mode pointer, but we don't know what to do
* with it - thats up to the protocol still.
*/
int sock_ioctl(struct inode *inode, struct file *file, unsigned int cmd,
unsigned long arg)
{
struct socket *sock;
if (!(sock = socki_lookup(inode)))
{
printk("NET: sock_ioctl: can't find socket for inode!\n");
return(-EBADF);
}
return(sock->ops->ioctl(sock, cmd, arg));
}
static int sock_select(struct inode *inode, struct file *file, int sel_type, select_table * wait)
{
struct socket *sock;
if (!(sock = socki_lookup(inode)))
{
printk("NET: sock_select: can't find socket for inode!\n");
return(0);
}
/*
* We can't return errors to select, so it's either yes or no.
*/
if (sock->ops && sock->ops->select)
return(sock->ops->select(sock, sel_type, wait));
return(0);
}
void sock_close(struct inode *inode, struct file *filp)
{
struct socket *sock;
/*
* It's possible the inode is NULL if we're closing an unfinished socket.
*/
if (!inode)
return;
//找对inode对应的socket结构
if (!(sock = socki_lookup(inode)))
{
printk("NET: sock_close: can't find socket for inode!\n");
return;
}
sock_fasync(inode, filp, 0);//更新异步通知列表
sock_release(sock);//释放套接字
}
/*
* Update the socket async list
*/
//输入参数on的取值决定是分配还是释放一个fasync_struct结构,该结构用于异步唤醒
static int sock_fasync(struct inode *inode, struct file *filp, int on)
{
struct fasync_struct *fa, *fna=NULL, **prev;
struct socket *sock;
unsigned long flags;
if (on)//分配
{
fna=(struct fasync_struct *)kmalloc(sizeof(struct fasync_struct), GFP_KERNEL);
if(fna==NULL)
return -ENOMEM;
}
sock = socki_lookup(inode);
prev=&(sock->fasync_list);
save_flags(flags);//保存当前状态
cli();
//从链表中找到与file结构对应的fasync_struct
for(fa=*prev; fa!=NULL; prev=&fa->fa_next,fa=*prev)
if(fa->fa_file==filp)
break;
if(on)//分配后的建立联系
{
//如果已经有对应的file结构,则释放之前创建的
if(fa!=NULL)
{
kfree_s(fna,sizeof(struct fasync_struct));
restore_flags(flags);
return 0;
}
//如果没有,则挂载这个新创建的结构
fna->fa_file=filp;
fna->magic=FASYNC_MAGIC;
fna->fa_next=sock->fasync_list;
sock->fasync_list=fna;
}
//释放
else
{
if(fa!=NULL)
{
*prev=fa->fa_next;
kfree_s(fa,sizeof(struct fasync_struct));
}
}
restore_flags(flags);//恢复状态
return 0;
}
/*
* 异步唤醒函数,通过遍历socket结构中fasync_list变量指向的队列,
* 对队列中每个元素调用kill_fasync函数
*/
int sock_wake_async(struct socket *sock, int how)
{
if (!sock || !sock->fasync_list)
return -1;
switch (how)
{
case 0:
//kill_fasync函数即通过相应的进程发送信号。这就是异步唤醒功能
kill_fasync(sock->fasync_list, SIGIO);
break;
case 1:
if (!(sock->flags & SO_WAITDATA))
kill_fasync(sock->fasync_list, SIGIO);
break;
case 2:
if (sock->flags & SO_NOSPACE)
{
kill_fasync(sock->fasync_list, SIGIO);
sock->flags &= ~SO_NOSPACE;
}
break;
}
return 0;
}
/*
* 只用于UNIX域名(iconn,conn只用于UNIX域),用于处理一个客户端连接请求
*/
int sock_awaitconn(struct socket *mysock, struct socket *servsock, int flags)
{
struct socket *last;
/*
* We must be listening
*/
//检查服务器端是否是处于监听状态,即可以进行连接
if (!(servsock->flags & SO_ACCEPTCON))
{
return(-EINVAL);
}
/*
* Put ourselves on the server's incomplete connection queue.
*/
//将本次客户端连接的套接字插入服务器端,socket结构iconn字段指向的链表
//表示客户端正等待连接
mysock->next = NULL;
cli();
if (!(last = servsock->iconn))
servsock->iconn = mysock;
else
{
while (last->next)
last = last->next;
last->next = mysock;
}
mysock->state = SS_CONNECTING;//正在处理连接
mysock->conn = servsock;//客户端连接的服务器端套接字
sti();
/*
* Wake up server, then await connection. server will set state to
* SS_CONNECTED if we're connected.
*/
//唤醒服务器端进程,以处理本地客户端连接
wake_up_interruptible(servsock->wait);
sock_wake_async(servsock, 0);
//检查连接状态
if (mysock->state != SS_CONNECTED)
{
if (flags & O_NONBLOCK)
return -EINPROGRESS;
//等待服务器端处理本次连接
interruptible_sleep_on(mysock->wait);
//检查连接状态,如果仍然没有建立连接
if (mysock->state != SS_CONNECTED &&
mysock->state != SS_DISCONNECTING)
{
/*原因如下
* if we're not connected we could have been
* 1) interrupted, so we need to remove ourselves
* from the server list
* 2) rejected (mysock->conn == NULL), and have
* already been removed from the list
*/
//如果被其他中断,需要主动将本地socket从对方服务器中iconn中删除
if (mysock->conn == servsock)
{
cli();
//找到iconn中的本地socket结构
if ((last = servsock->iconn) == mysock)
servsock->iconn = mysock->next;
else
{
while (last->next != mysock)
last = last->next;
last->next = mysock->next;
}
sti();
}
//被服务器拒绝,本地socket已经被删除,无需手动删除
return(mysock->conn ? -EINTR : -EACCES);//两种原因情况的返回
}
}
return(0);
}
socket.c 文件中函数的实现绝大多数都是简单调用下层函数,而这些下层函数就是af_inet.c 文件中定义的函数。socket.c 对应 BSD socket层,文件af_inet.c 则对应的是INET socket层。这些上下层次的表示从函数的嵌套调用关系上体现出来。
参考资料:《Linux 内核网络栈源代码情景分析》、Linux kernel 1.2.13















 2580
2580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









