






神经网络篇

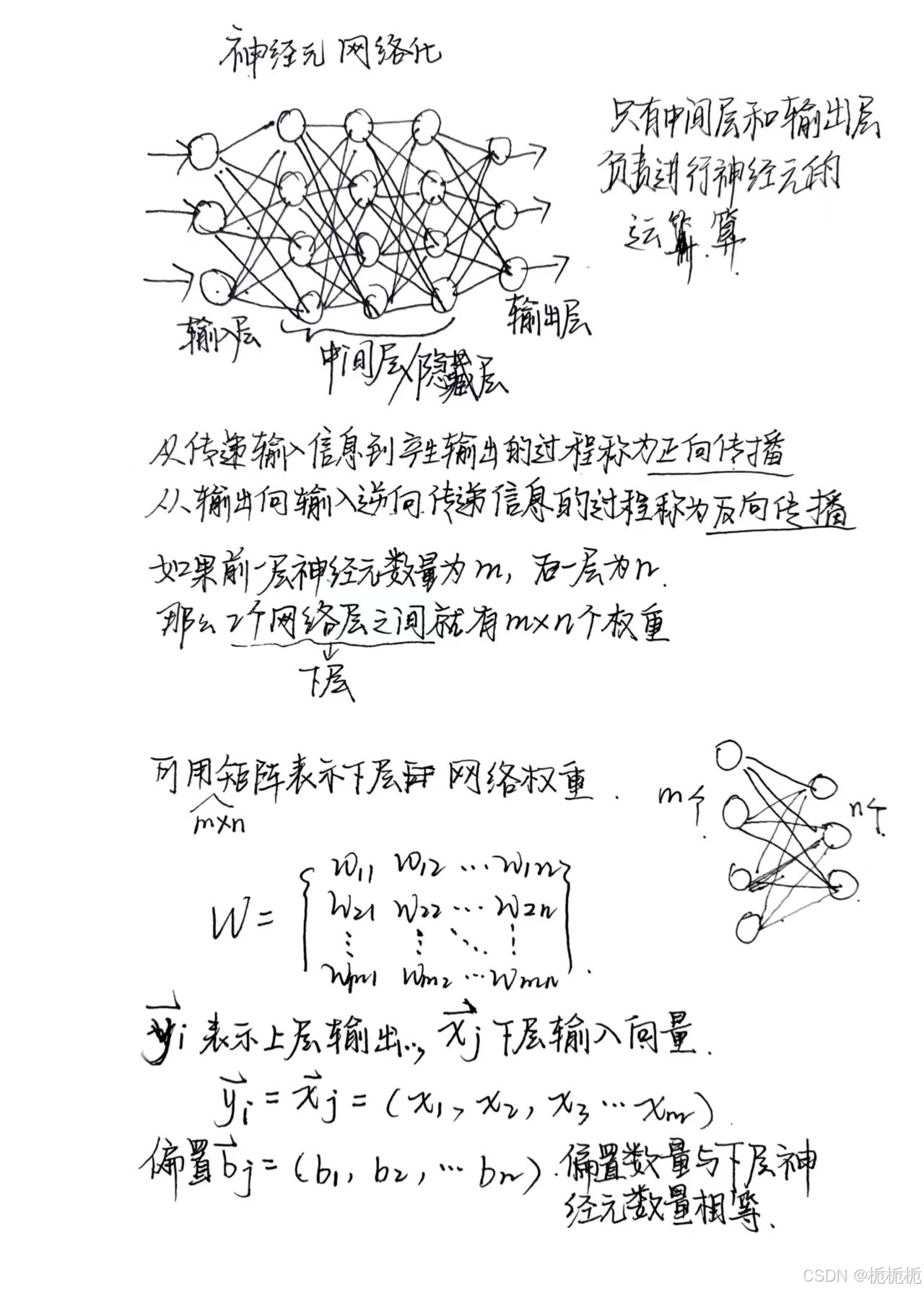

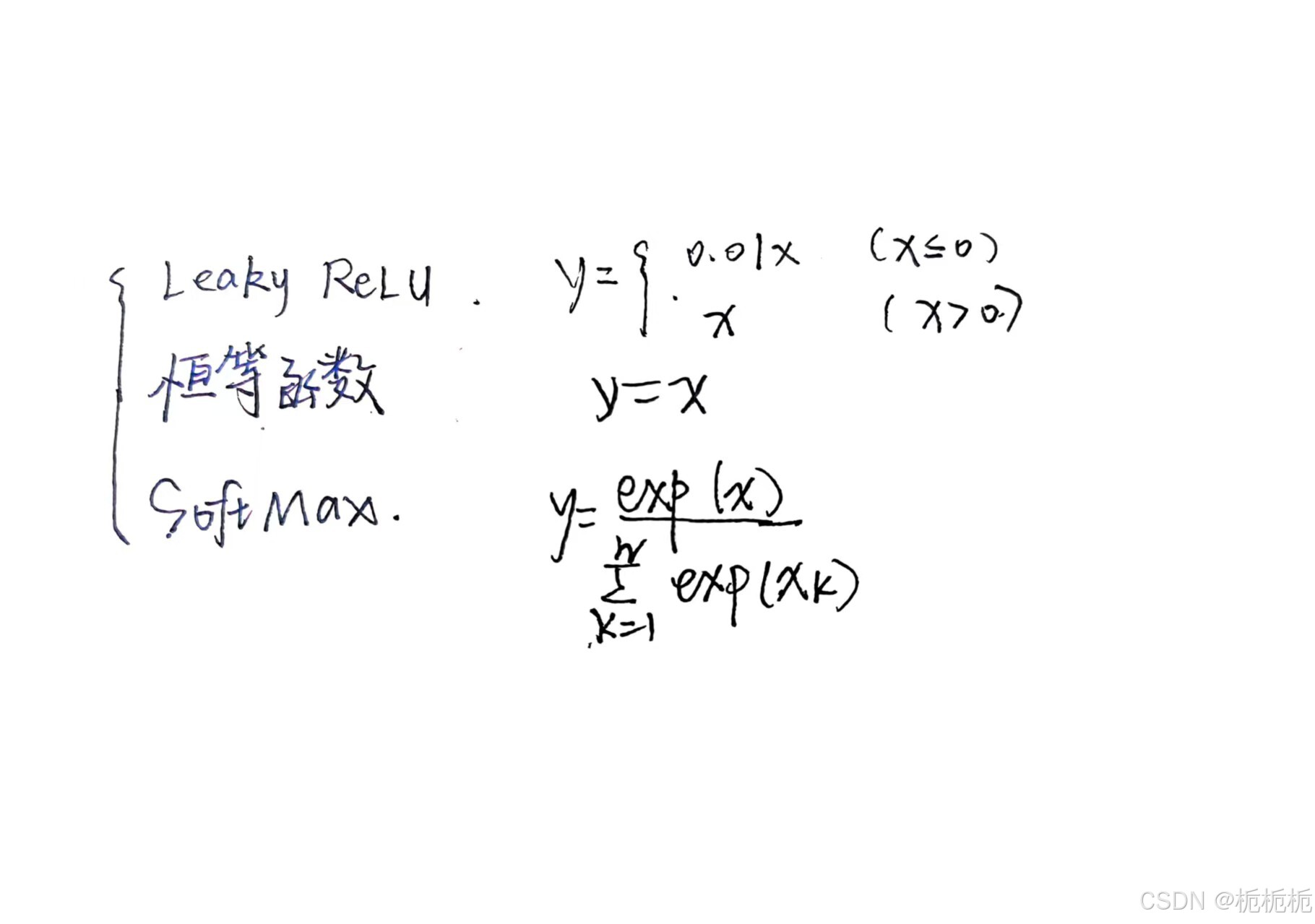
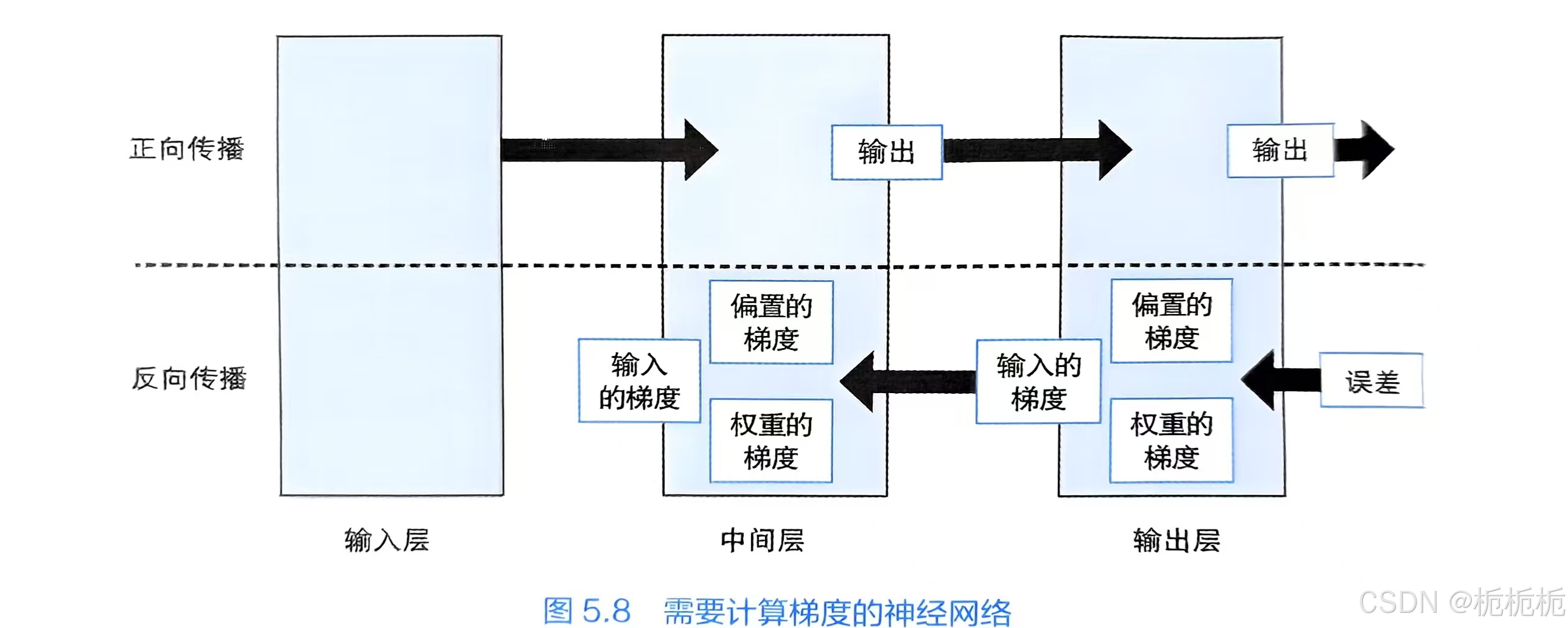
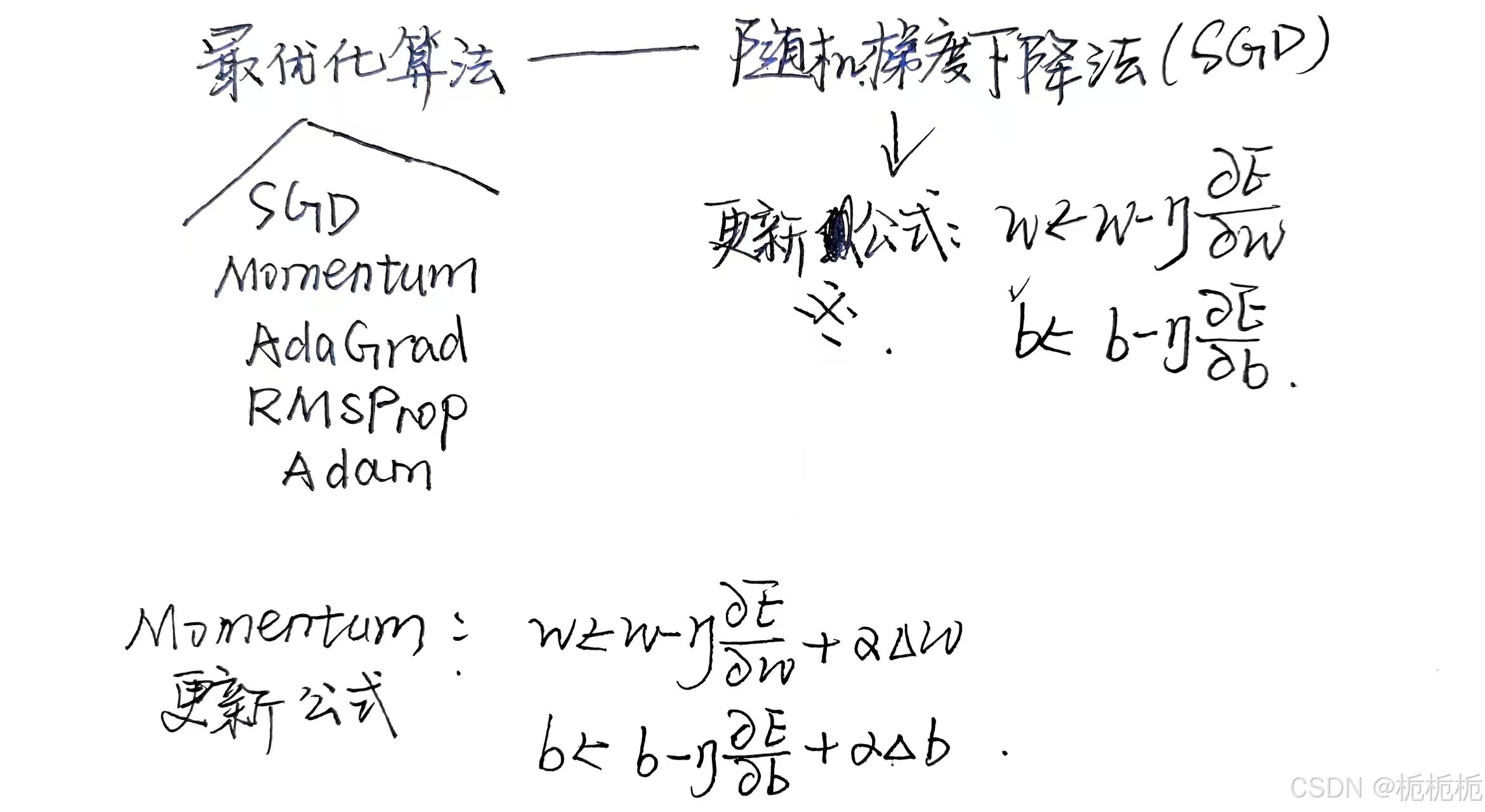
反向传播篇



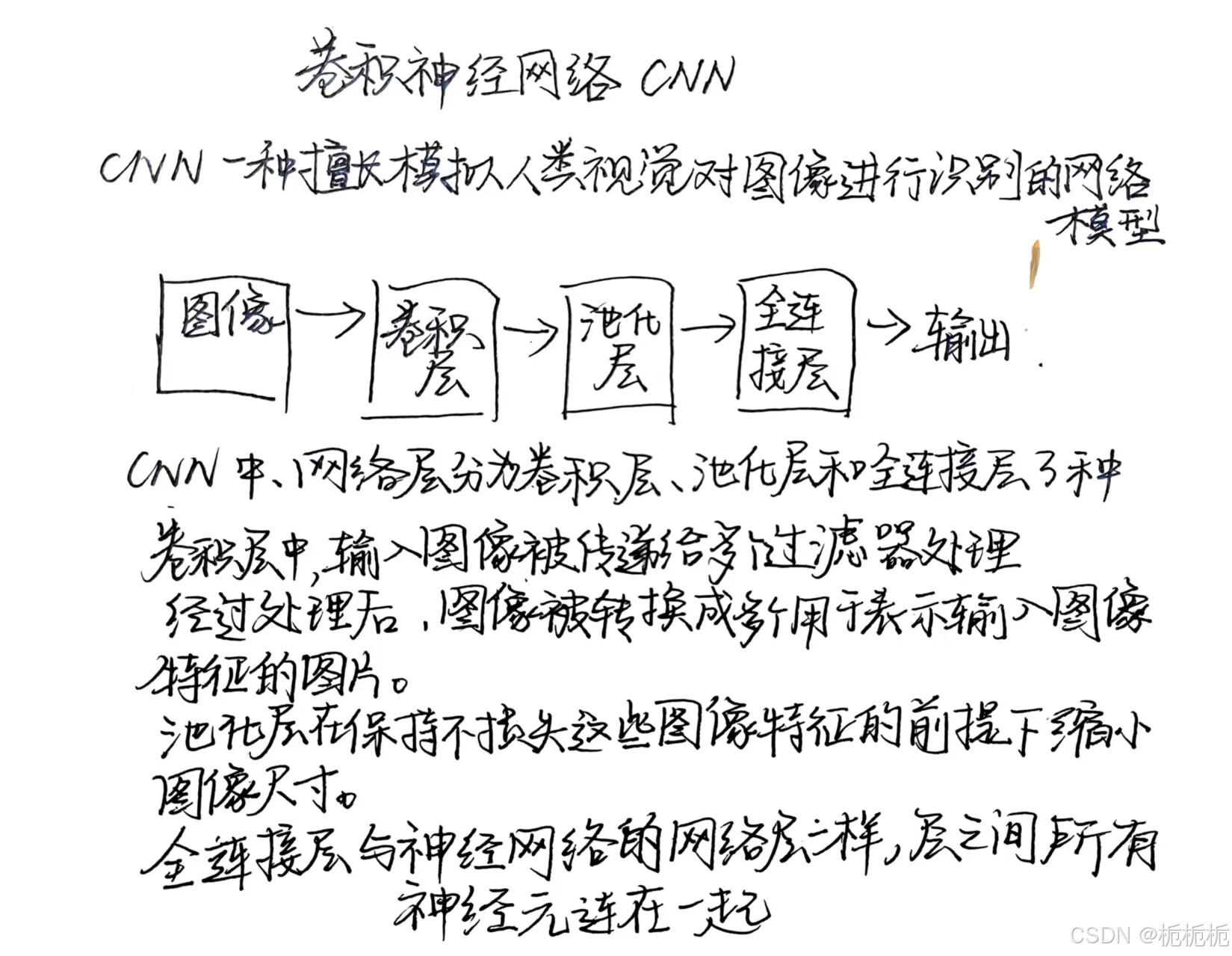
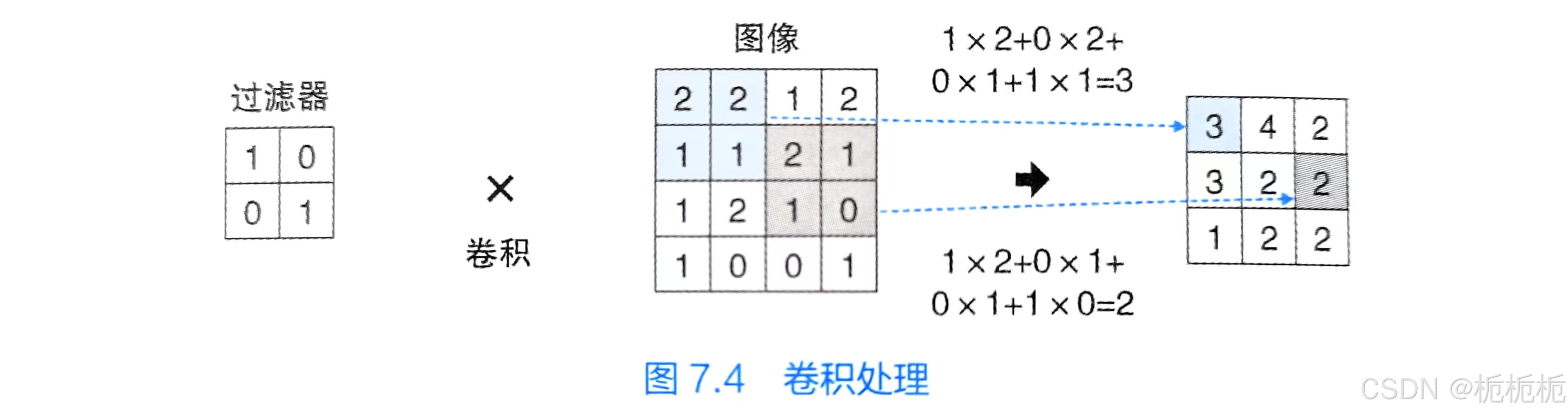
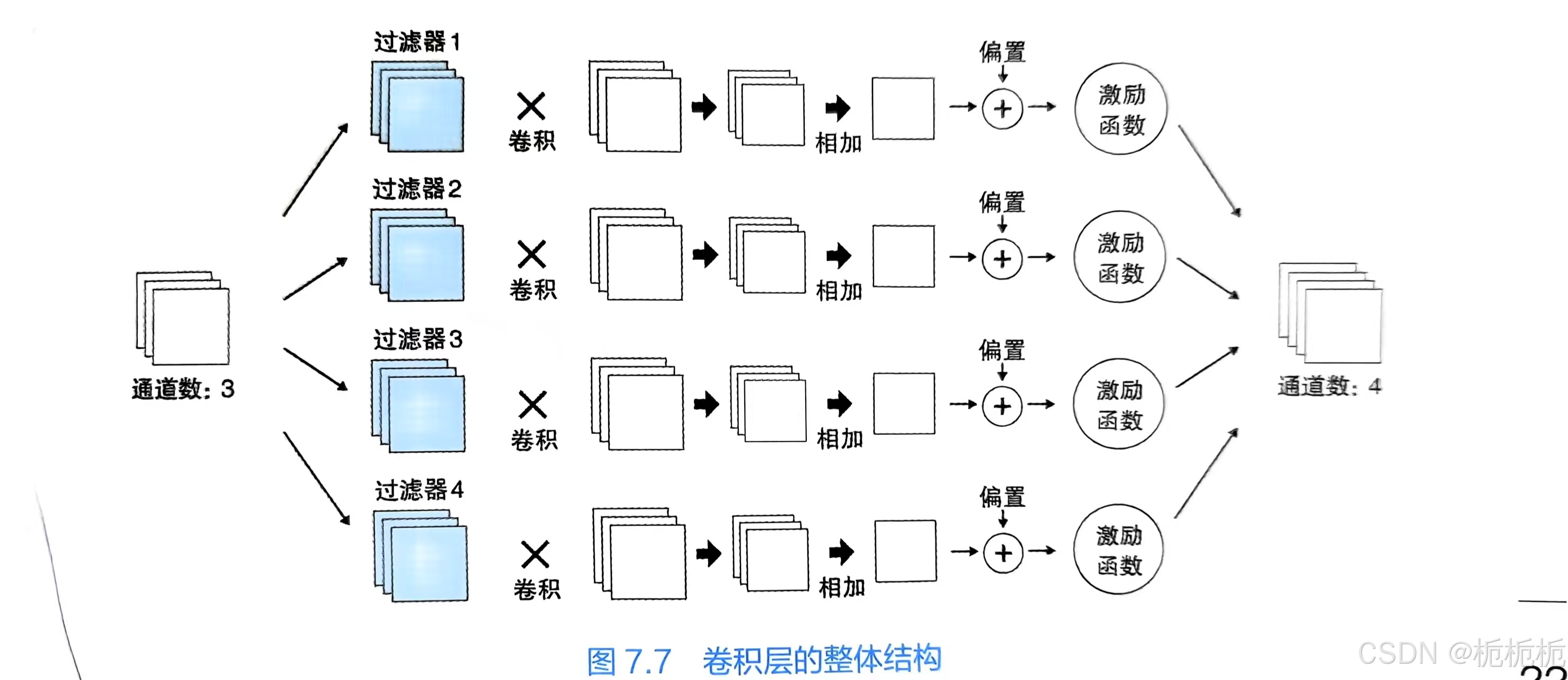
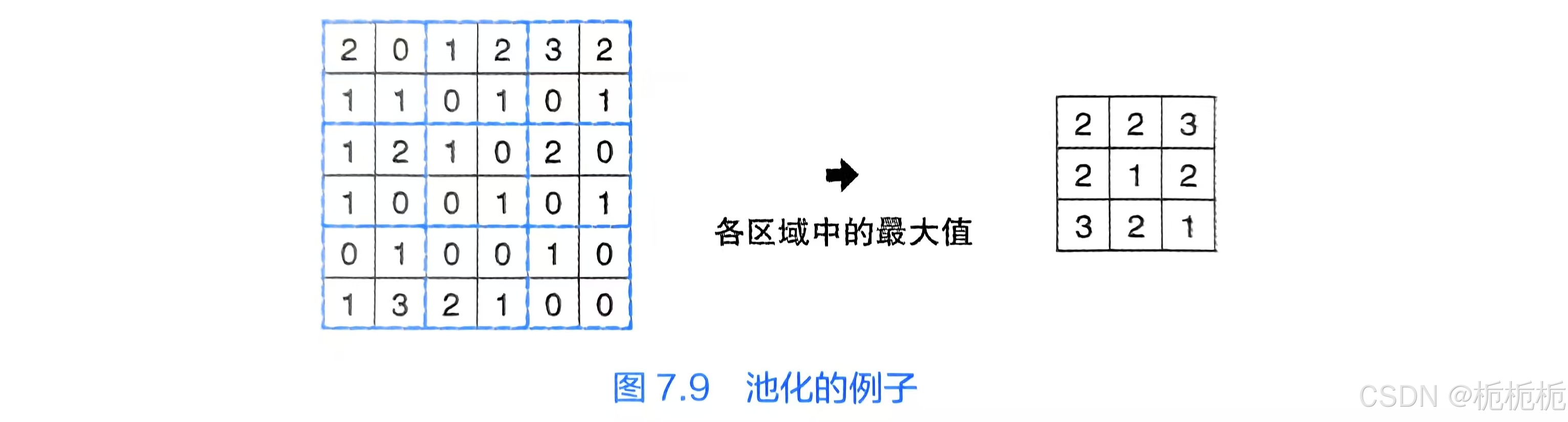
卷积神经网络CNN篇








循环神经网络RNN篇
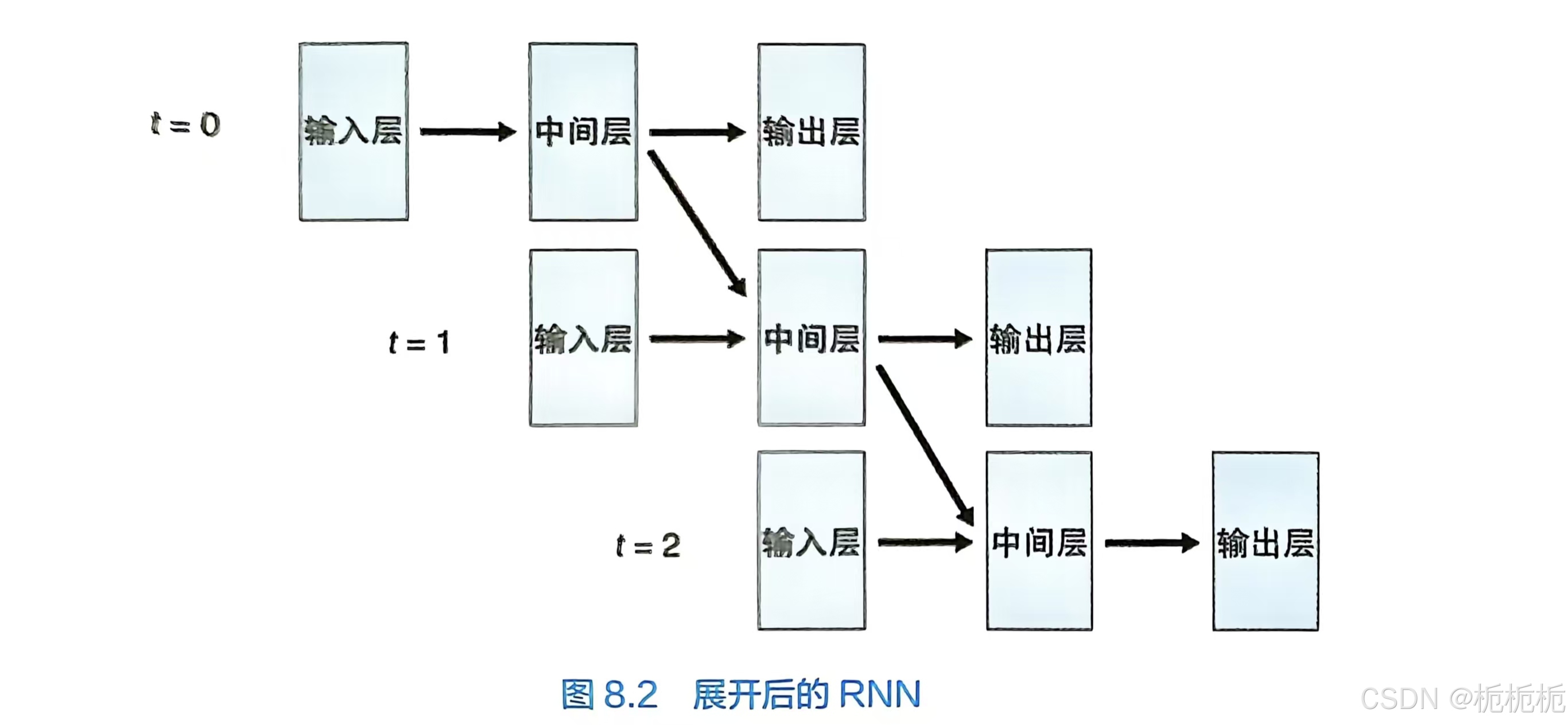
RNN
循环神经网络是一种能处理上下文的神经网络,适用于语音,文章,动画等内容的处理。循环神经网络可以将随着时间变化的数据即时间序列的数据作为输入数据进行处理。

RNN可以利用过往的记忆对数据进行判断处理。
RNN的学习是通过反向传播算法来实现的,但是所使用的误差的计算方法与普通神经网络是不同的。RNN的误差需要对过去的状态进行追溯,某一时刻的误差是该时刻的输出与正确答案的误差,再和追溯得到的误差相加所得到的值。RNN通过这种方式,对全部时间内的误差进行追溯来计算梯度,并对权重和偏置量进行更新。
RNN使用时间序列来构建神经网络,但是如果通过太多的网络层进行误差传播,将会导致梯度消失或者产生发散的问题。由于RNN是使用从前一个时刻继承来的数据对同一个权重进行反复的乘法运算,因此这一问题的产生会比普通的神经网络显得更为突出。普通的神经网络因为不使用递归,每层网络之间的权重也不同,较RNN而言,发生这种问题的概率低很多。正因为如此,使用RNN进行短期记忆是可以的,但是要实现长期记忆比较难。(对数据进行长期性的记忆行为,称为长期依赖性。)
LSTM
LSTM(Long short-term memory)用于克服在RNN中实现长期记忆的保存困难的问题。
无论是长期记忆的保存还是短期记忆的保存,都可以用LSTM来实现。
LSTM是循环神经网络的一个分支,引入了门的机制,可以对过去的信息做出忘掉or记住的判断,对下一刻必要的信息进行继承。
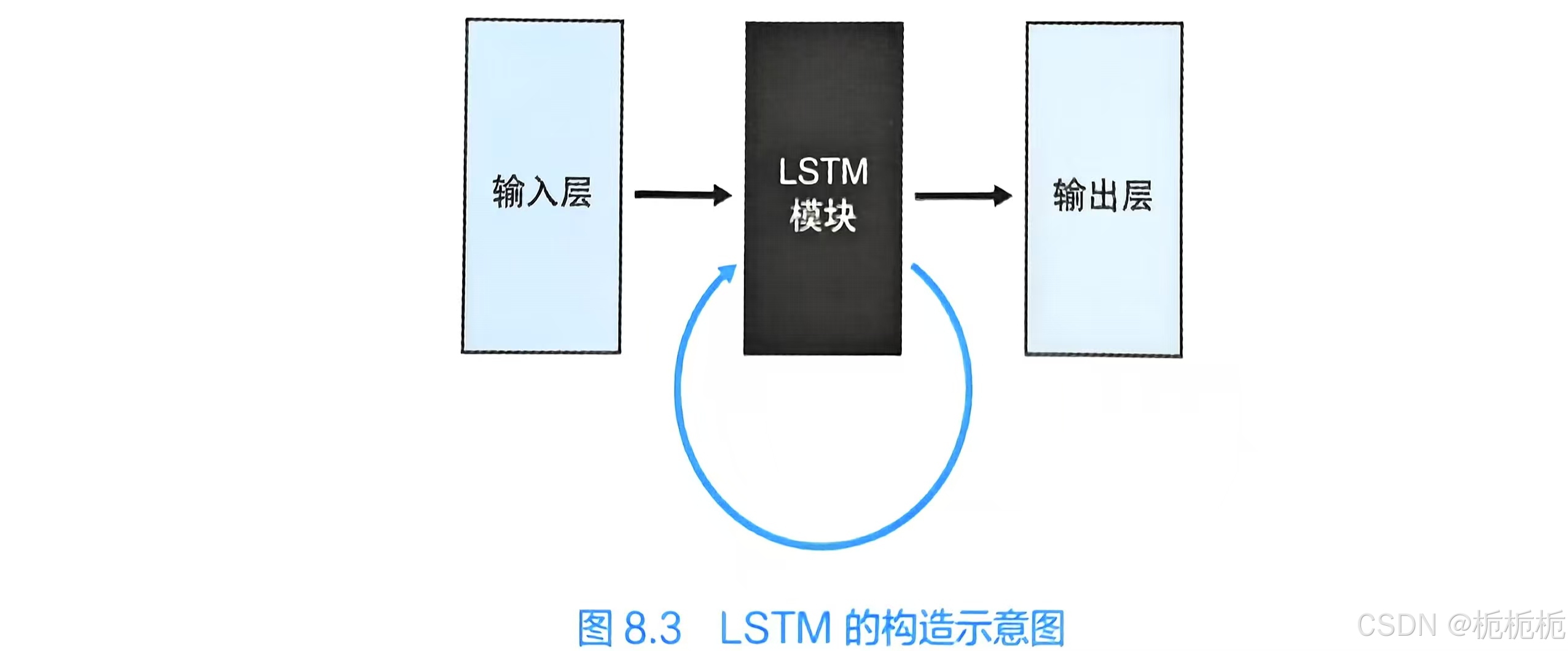
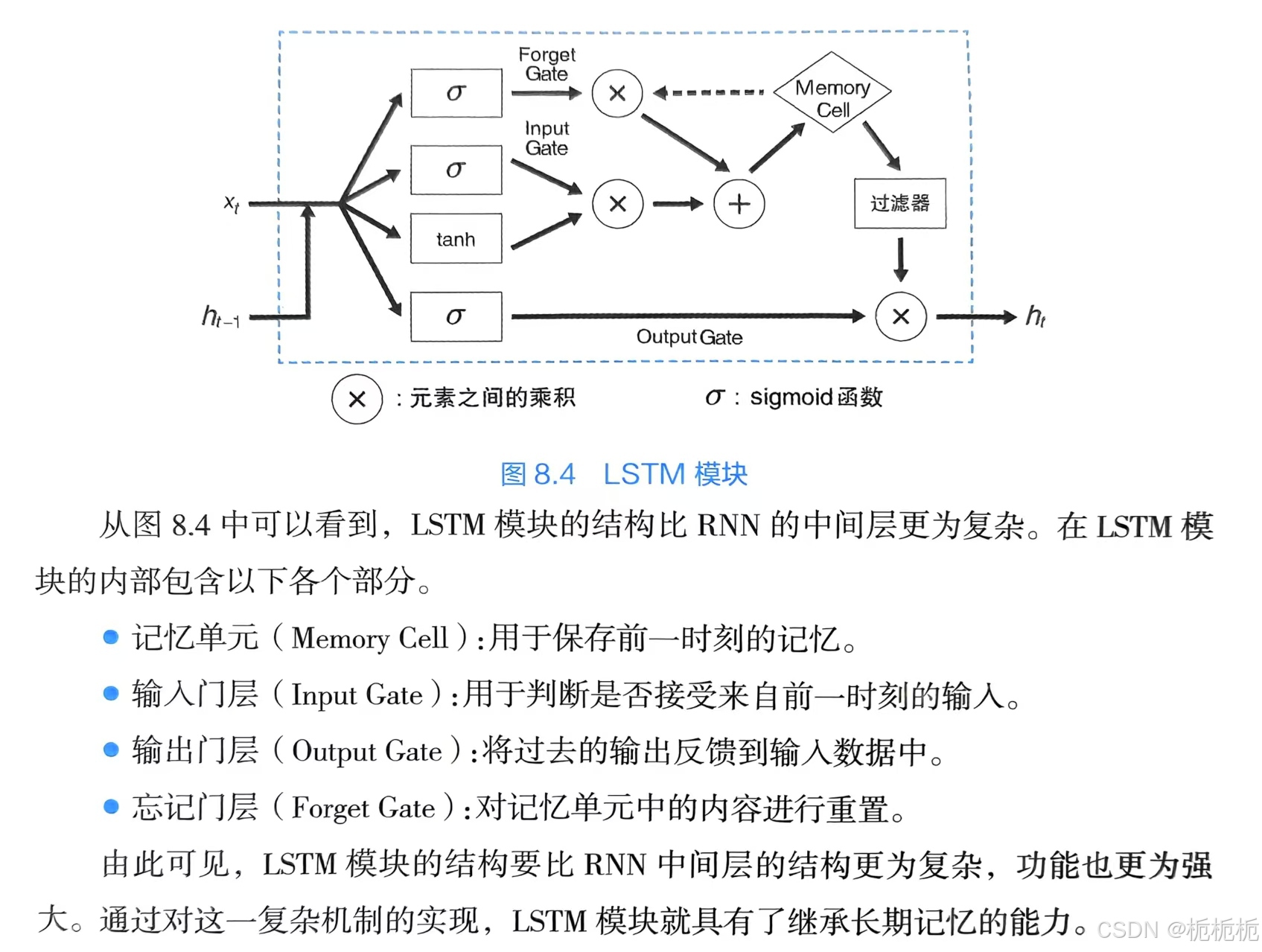
LSTM和RNN一样都有递归的网络结构,但是他用LSTM模块(类似电路的结构)代替了RNN使用的中间层。
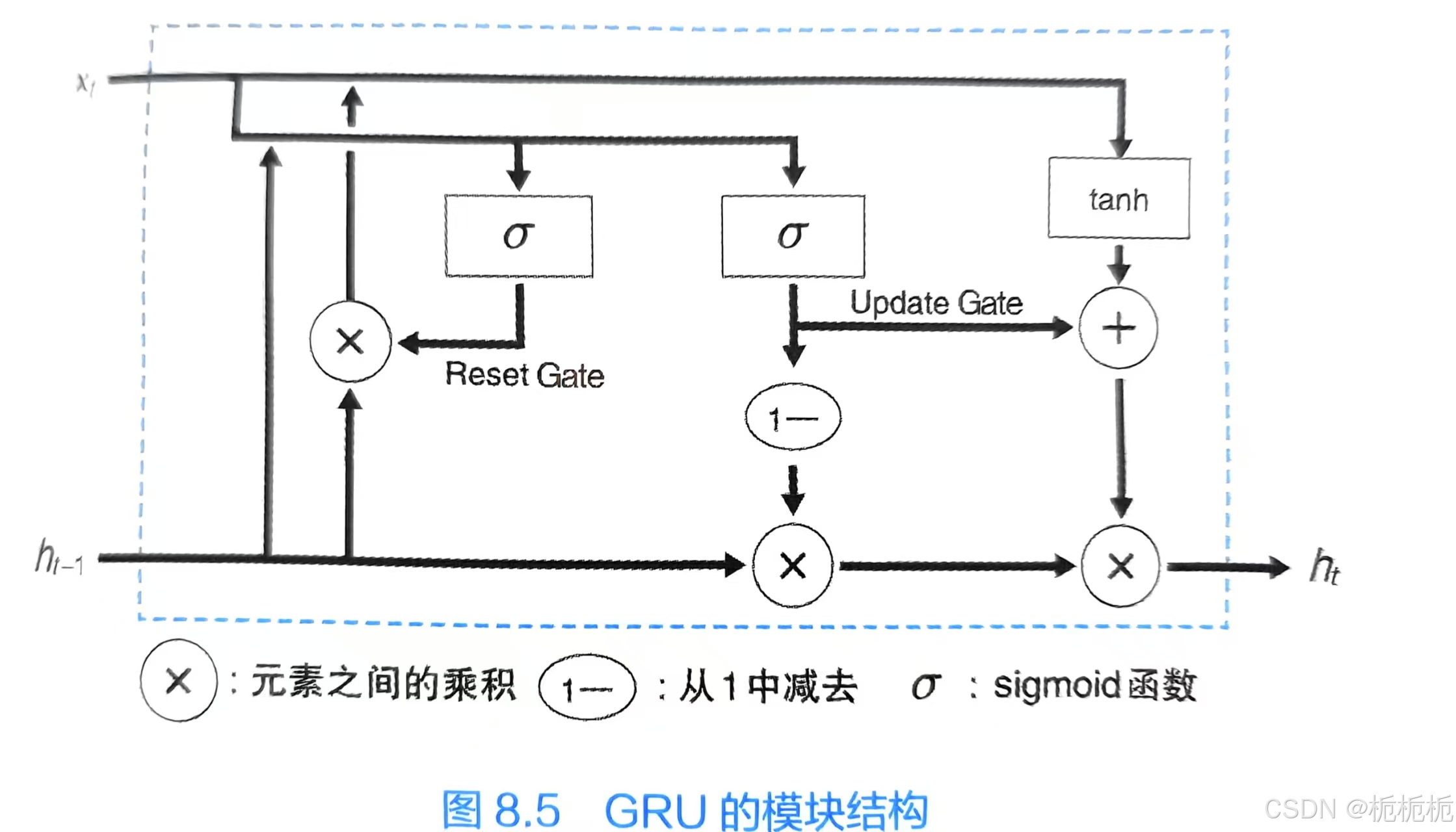
GRU
是对LSTM的改进。GRU对输入门层和忘记门层进行合并,统一成更新门层;记忆门层和输出门层也被去掉了;有一个复位门层来将值清零。
自然语言处理
1.语素分析
将自然语言分解成语素的技术。语素是任意包含实际意义的最小单位的文字集合。(英语好分,因为有空格。)
2.单词嵌入
使用神经网络对自然语言进行处理之前,需要先将单词数据转换为利于神经网络使用的矢量型数据。
单词嵌入就是将自然语言中的单词进行矢量化的一种方式。
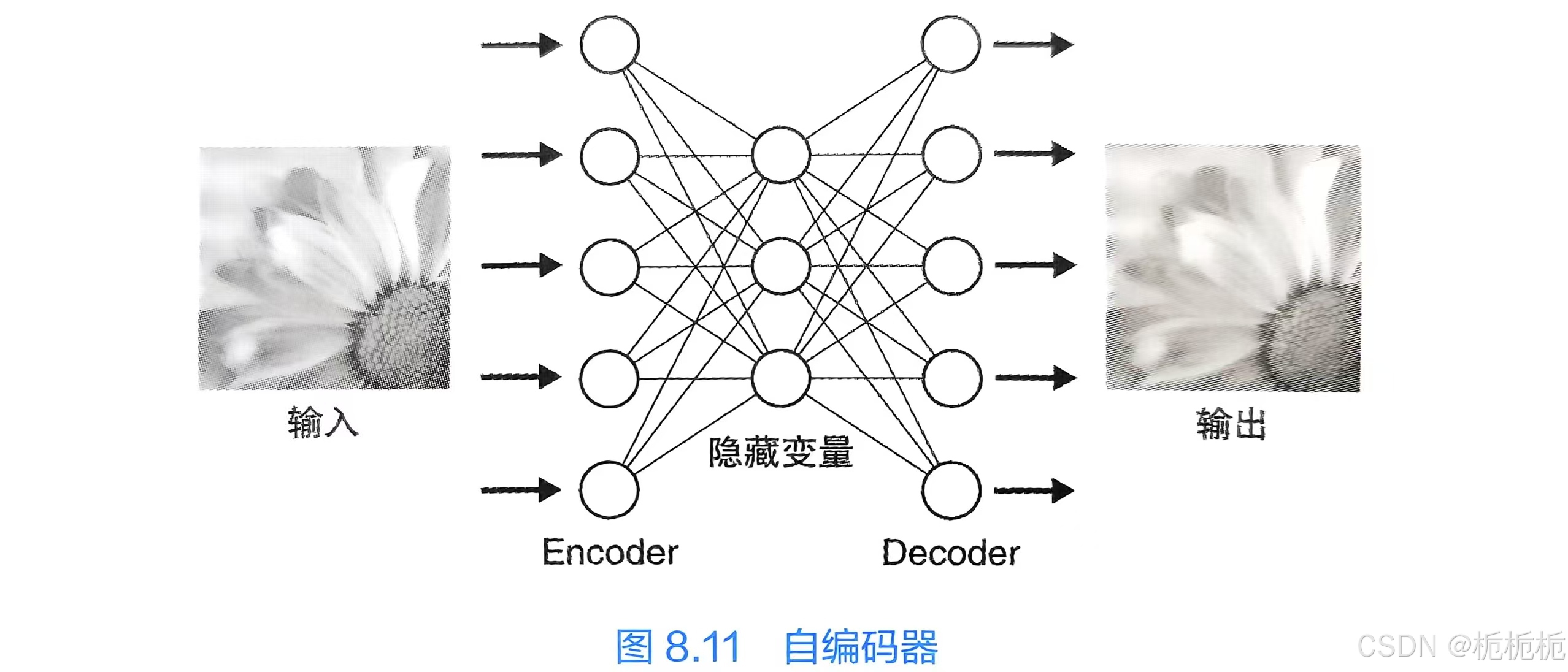
生成式模型
指通过对训练数据的学习,获得能够自动生成与训练数据相似的新的数据能力的一种模型。(通过学习获得使自动生成的数据的分布与训练数据的分布保持一致的能力的一种神经网络模型。)
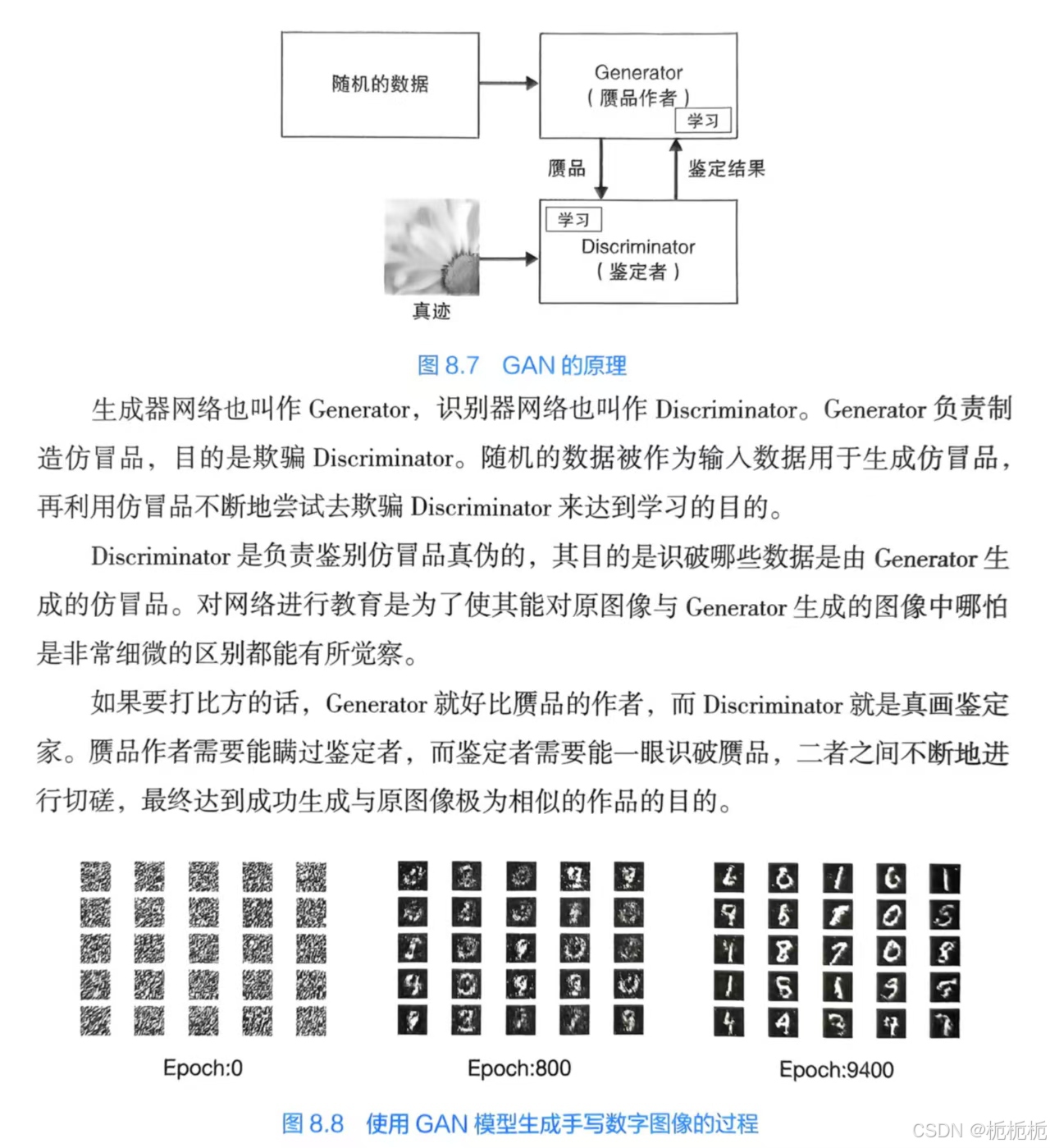
GAN
generative adversarial network,生成式对抗网络。
通过运用生成器网络与识别器网络,让两个网络进行相互竞争来实现学习。常被用于图像自动生成。
VAE
variational autoencoder,变分自编码器。
属于生成式模型的一类,通过对训练数据的特征进行捕捉,实现自动生成类似训练数据的数据。
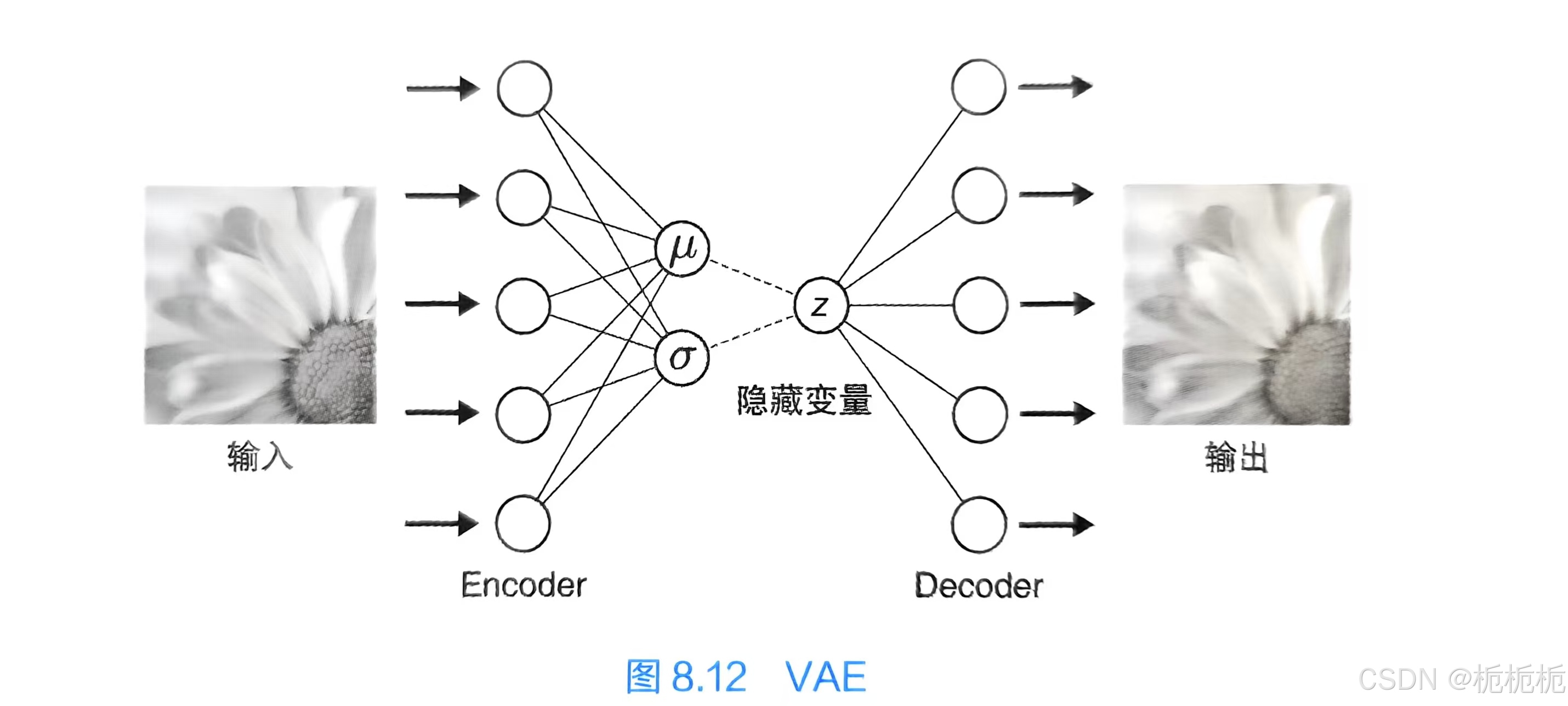
通过对隐藏变量z的调整可以实现对连续变化的数据的自动生成。

通过这一技术,可以实现比如自动生成可连续变化的人的表情的图像。VAE模型具有生成连续性变化数据的能力。
强化学习
智能体反复试错来学习“如何在给定的环境中采取最具价值的行动”。
Q学习(Q-learning)是强化学习中最具代表性的算法。智能体根据Q值(状态行动价值的数值)来决定自身的行为。Q值不是短期的奖励,而是长期的回报。

GPU的使用
原本是专门用来实现高速化图像显示的处理器,同样也可以通过发挥其强大的运算能力,实现高速化的深度学习计算(如大量的矩阵运算)。

看的是这本👆,写的很清晰,很适合我这种小白了解这方面的知识。
Transformer模型
transformer模型的提出时为了解决传统神经网络模型在处理复杂序列时的一些限制,特别是长距离依赖问题。(过去,在自然语言处理和其他序列处理领域的神经网络模型中,RNN和LSTM一直占据主导地位。这些模型存在一些固有的问题。于是提出了Transformer。)
Transformer的主要特点是完全放弃了循环和卷积,而是主要依赖于注意力机制来捕捉序列数据中不同距离的元素之间的依赖关系。
Transformer模型结构
Transformer模型的主要组成部分是编码器和解码器。编码器主要用于处理输入数据,解码器用于生成输出数据。
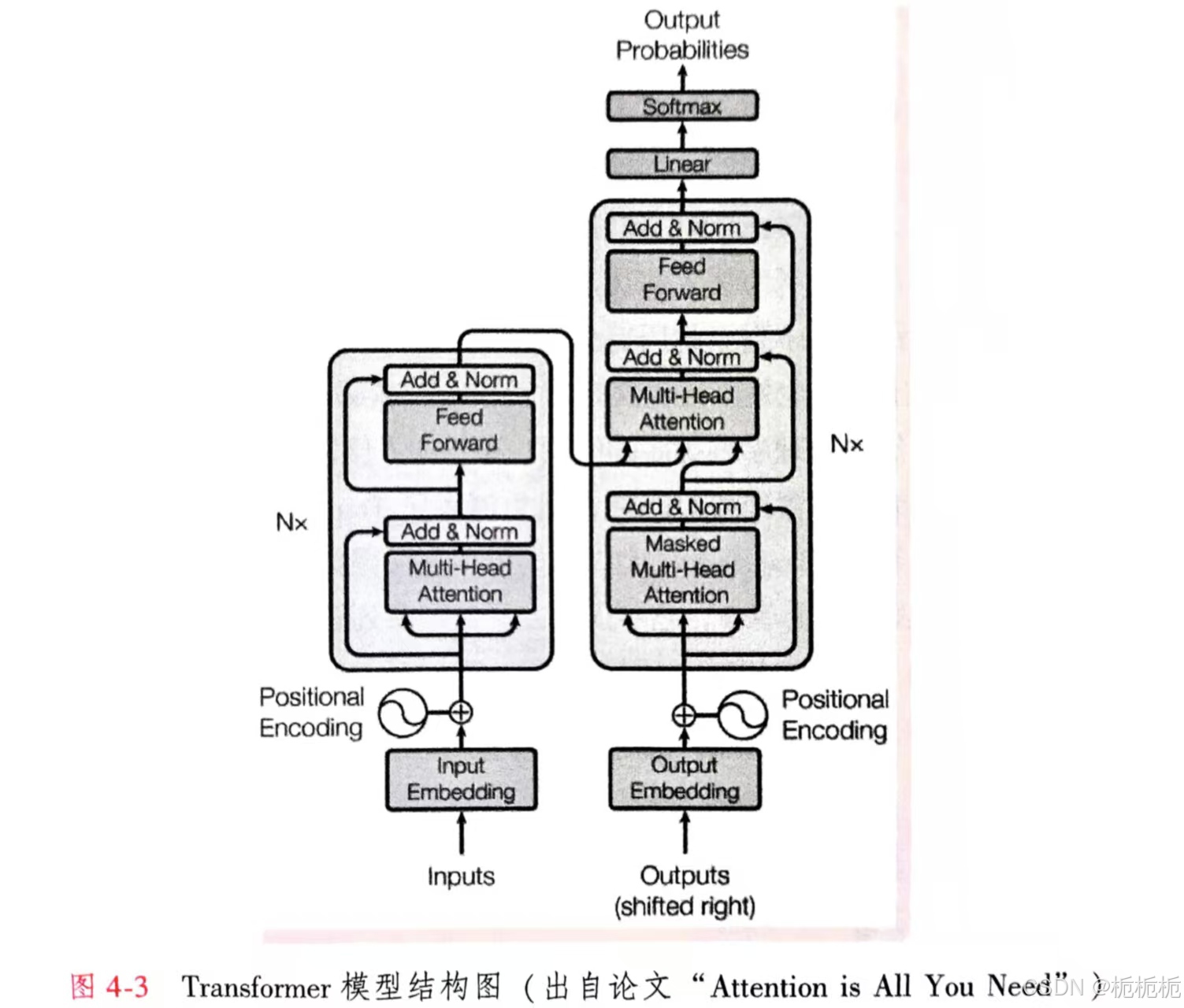
编码器由N个完全相同的层堆叠而成。每层有两个子层:多头自注意(Multi-Head Self-Attention)机制、前馈(Feed-Forward)神经网络。这两个子层都有一个残差连接和一个层归一化。
解码器由N个完全相同的层堆叠而成。每个层由3个子层:两个多头自注意机制,一个前馈神经网络。这三个子层都有一个残差连接和一个层归一化。第一个自注意子层和编码器中的自注意子层一样,都是处理输入序列。第二个自注意子层是用来将解码器的输入和编码器的输出联系起来的,此子层查询来自于前一个自注意子层的输出,键和值来自于编码器的输出。
解码器顶部有一个全连接层,将输出转化为最终预测结果。
注意力和自注意力机制
三个变量:查询Q、键K、值V
注意力机制目标:将查询与一组键值对进行比较,并计算出查询与每个键之间的相关性得分,然后使用这些得分对值进行加权平均。
Transformer的归一化
层归一化:对每个样本的每个特征向量进行归一化,使其均值为0,方差为1。
稳定模型的训练过程并加速收敛。
Transformer的变体与扩展
BERT模型、GPT模型、T5预训练深度学习模型、ViT预训练深度学习模型。
Transformer训练
大模型的研究和实现经常会使用无监督预训练加有监督的微调的方式对Transformer模型进行训练。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









