







人工智能咨询培训老师叶梓 转载标明出处
在当今数字化时代,语言不仅是沟通的桥梁,也是信息和知识传递的核心。尽管大模型(LLMs)在处理英语等主流语言方面取得了显著进展,但它们在理解和生成其他语言内容方面的能力却参差不齐。这种不平衡限制了技术在全球范围内的应用潜力,SambaNova Systems 的研究团队在论文 "SambaLingo: Teaching Large Language Models New Languages" 中,直面这一挑战,提出了一种创新的方法来教授LLMs新的语言,这不仅是技术进步的体现,更是推动语言平等的重要一步。
语言是文化传承的载体,每种语言都有其独特的表达方式和世界观。技术发展中的“语言鸿沟”往往使得某些语言群体在信息时代处于不利地位。SambaLingo项目通过扩展LLMs的能力,使得这些模型能够更好地服务于非英语用户,从而缩小了这一鸿沟,为构建一个更加包容的数字世界奠定了基础。
方法
在SambaLingo项目中,适应新语言的核心在于一系列精心设计的步骤,这些步骤构成了适应方法论的基石。
选择合适的基础模型是语言适应过程的第一步。研究团队选择了Llama 2 7B作为起始点,因为它是当时可用的最佳开源模型。选择基础模型时,考虑了模型在原始语言(这里是英语)上的表现,以及其参数规模和训练数据的多样性。这一选择对于后续的适应过程至关重要,因为它决定了模型在新语言上的起点和潜在的性能。
扩展模型的词汇表是为了提高模型对新语言的理解和生成能力。由于Llama 2主要在英文文本上训练,其标记器对其他语言的效率较低。为了解决这个问题,研究者们通过添加目标语言的非重叠标记来扩展词汇表,并使用原始标记器的子词嵌入来初始化这些新标记。这一步骤不仅提高了标记器的效率,还有助于模型更好地处理新语言的文本。
持续预训练是适应新语言的关键环节。研究者们使用了英语和目标语言的网页数据的1:3混合,这些数据偏向目标语言。这种数据混合策略有助于模型在保持对原始语言的理解的同时,快速学习新语言的特征。预训练数据的组成反映了对目标语言的重视,同时也确保了模型能够在多样化的数据上进行训练,以提高其泛化能力。
为了确保模型生成的文本符合人类的偏好,研究者们采用了监督微调和直接偏好优化(DPO)的两阶段方法。在监督微调阶段,模型使用与目标语言1:1比例的超聊天数据集和谷歌翻译版本的超聊天数据集进行训练。在DPO阶段,模型进一步通过与人类偏好对齐的数据进行训练,以生成更自然、更符合预期的文本。
这一阶段的训练特别重要,因为它涉及到模型的微调,使其能够生成与人类偏好一致的文本。这不仅提高了模型的可用性,还增强了其在特定文化和语境中的适应性。
以上这些步骤不仅提高了模型在新语言上的性能,还确保了其生成的文本能够符合人类的期望和偏好。通过这种方法,SambaLingo项目为构建多语言能力更强的AI系统铺平了道路。
评估
研究团队采用了多种定量和定性的方法来全面评估模型的性能。定量评估涉及使用一系列基准测试来衡量模型在不同任务上的表现。主要的评估指标包括:
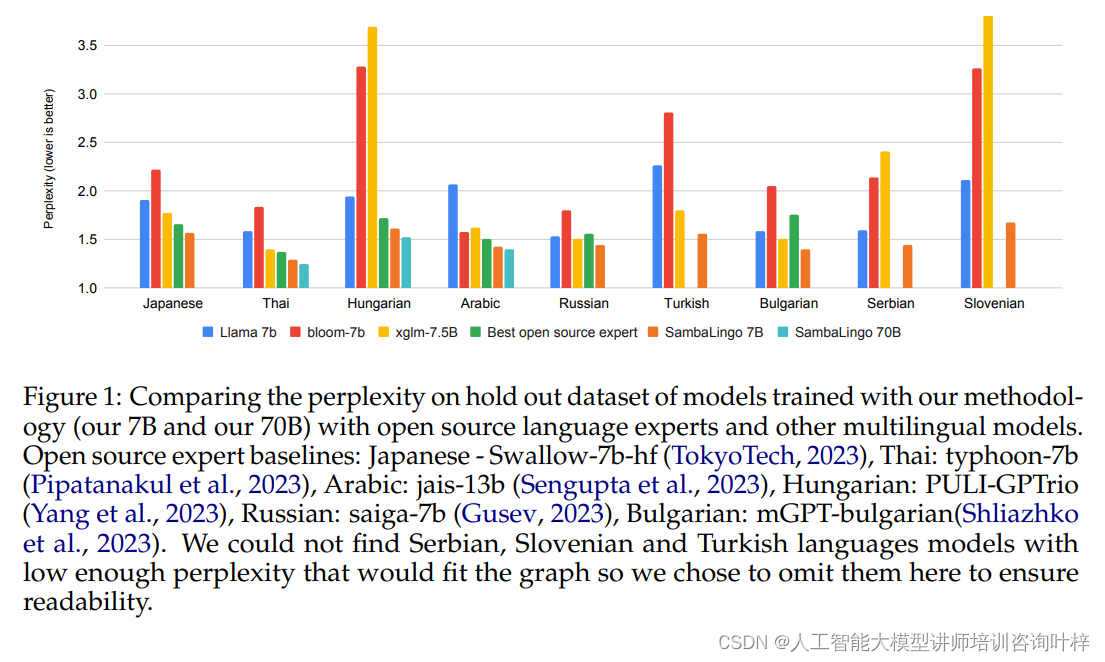
- 困惑度(Perplexity):在CulturaX数据集上,模型的困惑度被用来衡量其语言建模的能力。困惑度越低,表示模型对语言的理解越深入。
- 翻译质量:通过FLORES-200数据集,使用CHRF(Character n-gram F-score)指标来评估模型的机器翻译能力。这包括从英语到目标语言(EN→X)和从目标语言到英语(X→EN)的翻译。
模型还在SIB-200、BELEBELE和EXAMS等数据集上进行了文本分类、问答和自然语言理解任务的评估。这些评估帮助研究者们全面了解模型在各种语言任务上的性能。

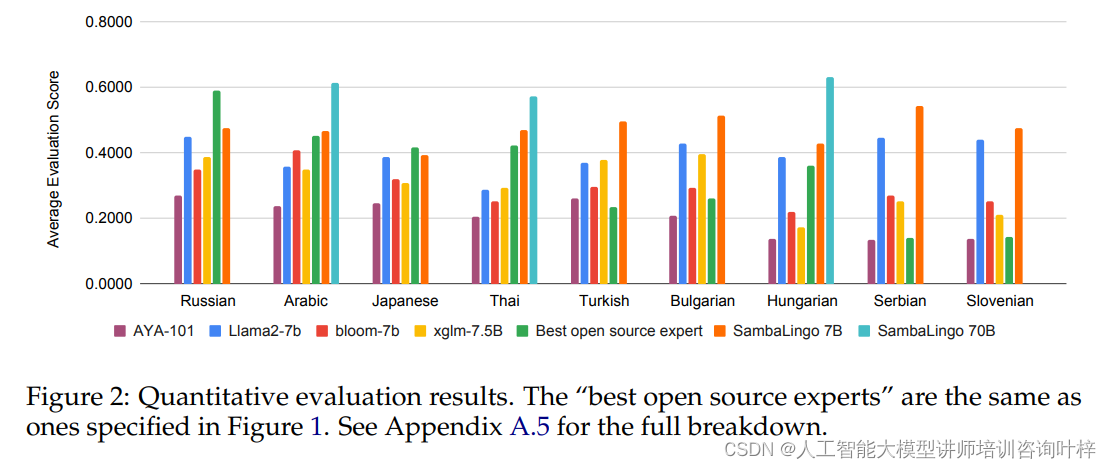
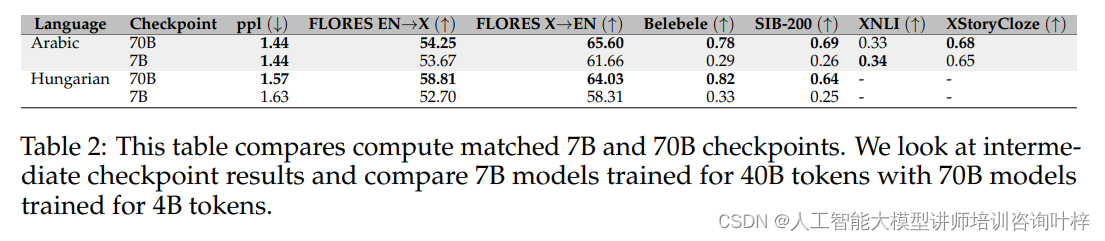
将模型扩展到70B参数规模是SambaLingo项目的一个重要里程碑。这种扩展使得模型能够拥有更多的容量来学习和存储知识,从而提高了其在复杂任务上的表现。研究者们对70B模型进行了与7B模型相同的评估,并发现:
- 70B模型在几乎所有评估任务上都展现出了更好的性能。
- 即使70B模型训练的步数更少(例如,4B tokens相对于7B模型的40B tokens),它们在多个基准测试中的表现也与7B模型相当或更好。
这表明,通过扩展模型规模,可以在保持计算效率的同时显著提升模型的能力。
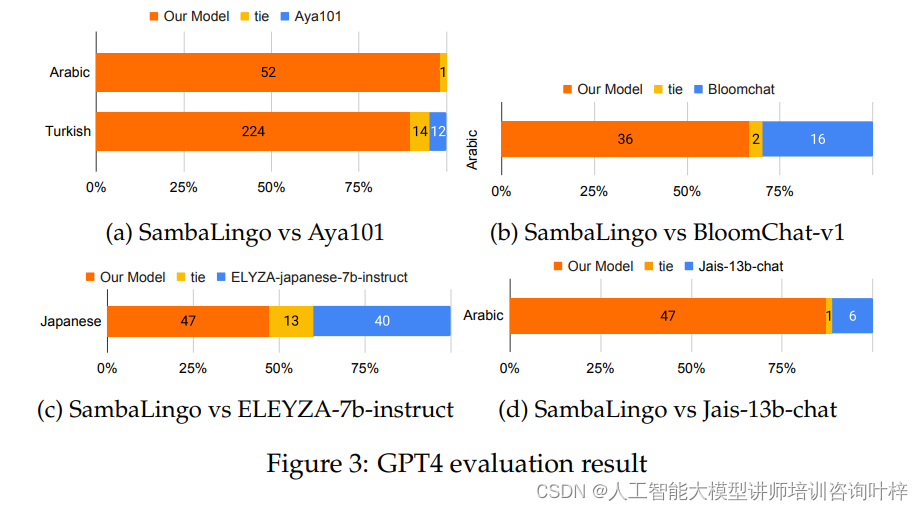
为了测试模型生成的文本是否符合人类的期望,研究者们采用了一种创新的评估方法:使用GPT-4作为评估者。GPT-4是一个高级的语言模型,被训练来评估其他模型生成的文本的质量。在这项研究中,GPT-4被用来:
- 对比模型生成的文本与真实用户提示的匹配度。
- 评估模型在生成高质量、符合人类偏好的文本方面的能力。
研究者们收集了一系列人工编写的提示,并使用GPT-4对模型生成的响应进行评分。这种方法提供了一个有力的视角,来评估模型是否能够生成与人类思维和表达方式一致的文本。
通过定量评估和扩展到更大的参数规模,SambaLingo项目证明了其方法论在提升模型性能方面的有效性。而使用GPT-4作为评估者,进一步验证了模型在生成符合人类偏好文本方面的能力。这些评估结果不仅展示了SambaLingo在技术层面的进步,也突显了其在促进语言多样性和包容性方面的潜力。
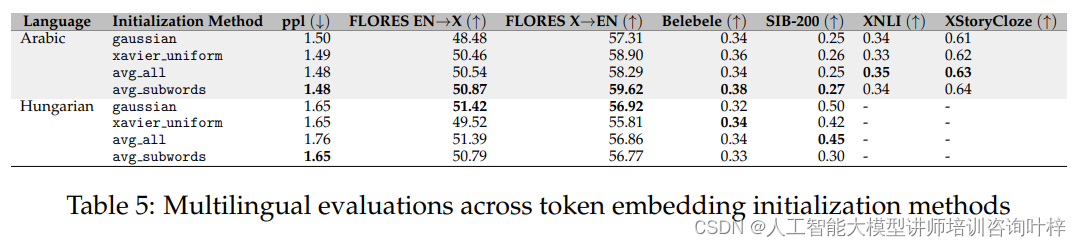
在消融研究中研究者们首先探讨了扩展词汇表对模型性能的影响。他们训练了两个模型,一个使用扩展的词汇表,另一个使用原始分词器,并在匈牙利语和阿拉伯语上进行了比较。结果表明,尽管扩展词汇表对下游任务的准确性影响不大,但它显著提高了分词效率,这有助于提高目标语言的推理效率和序列长度的利用。
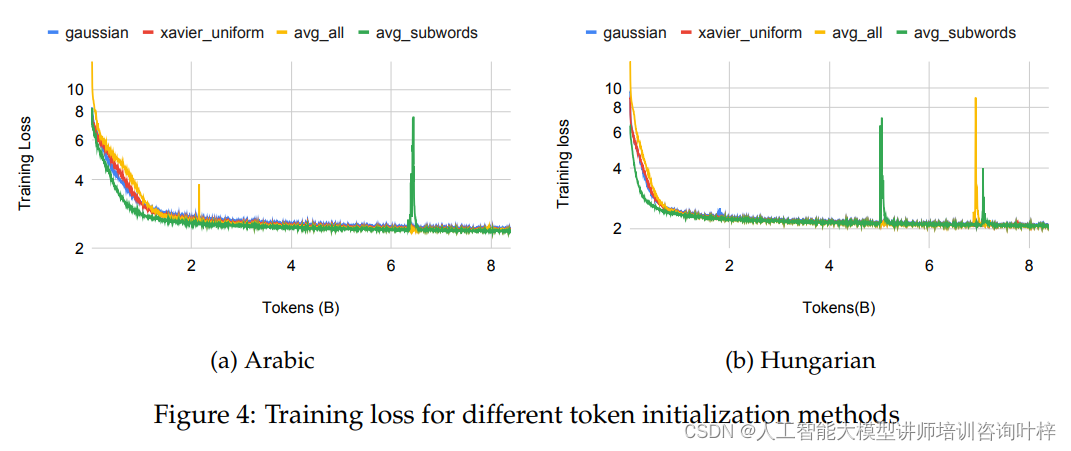
接下来,研究者们测试了不同的新标记嵌入初始化策略。他们尝试了高斯分布、Xavier均匀分布、所有原始标记的平均嵌入以及子词平均嵌入等四种方法。实验结果表明,使用子词平均嵌入的方法在训练损失收敛方面表现更好,并且在下游基准测试中取得了边际上的改进。
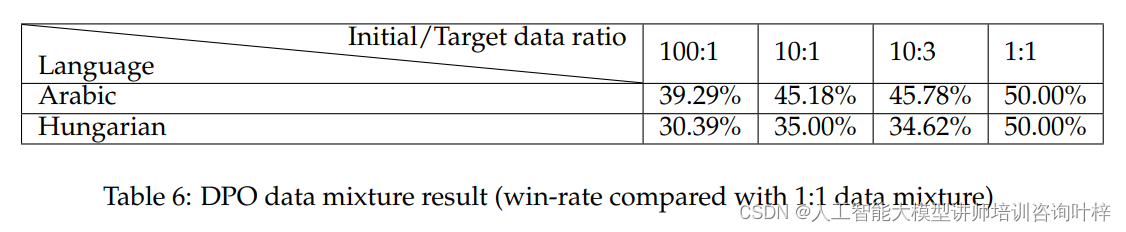
在直接偏好优化阶段,研究者们研究了不同比例的目标语言和英语数据混合对模型性能的影响。他们尝试了100:1、10:1、10:3和1:1的不同比例,并观察了与其他模型的成对比较中的胜率。结果表明,即使是10:1的数据比例,对于匈牙利语也能几乎达到与1:1比例相似的性能,而对于阿拉伯语,即使是10:3的数据比例也能达到可接受的性能。
研究者们还探讨了使用机器翻译数据与人工编写数据在人类对齐中的效果。他们使用Google翻译的超反馈数据和人工编写的开放助手对话数据进行了比较。结果表明,尽管使用翻译数据的模型在胜率上略低于使用人工编写数据的模型,但这并不意味着人工编写数据是获得高质量对齐模型的唯一途径。
研究者们分析了基础模型的质量对目标语言适应性能的影响。他们将Llama 2 7B和GPT-13B两个不同质量的基础模型适应到匈牙利语上,并发现使用更高质量的基础模型(Llama 2 7B)能够带来更好的下游性能。这一发现表明,随着更高质量模型的出现,将这些新模型应用于适应方法论将具有重要价值。


SambaLingo项目展示了一种将预训练的大型语言模型适应到新语言的有效方法。通过持续预训练和与人类偏好的对齐,研究团队在9种语言上实现了最先进的模型。随着全球化的不断深入,跨语言交流的需求日益增长。SambaLingo项目通过提升LLMs在多种语言上的表现,不仅能够促进国际合作和文化交流,还能够为机器翻译、跨语言内容创作等领域带来革命性的变化。这对于提升用户体验、推动知识共享以及加速技术创新都具有深远的意义。
论文链接:https://arxiv.org/abs/2404.05829
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









