







人工智能咨询培训老师叶梓 转载标明出处
扩散模型作为生成AI的关键实体,已经在多个领域展现出了卓越的能力。然而,现有的扩散模型,如Stable Diffusion和SDXL,通常在预训练阶段后需要进行微调以更好地符合人类偏好。最近,研究者们开始尝试使用强化学习(RL)来微调扩散模型,但这通常需要每个文本提示至少有两个图像(“胜者”和“败者”)。为了解决这一问题,来自加州大学洛杉矶分校的研究团队提出了一种扩散模型自我博弈微调(SPIN-Diffusion),允许扩散模型与其早期版本进行竞争,从而实现自我迭代改进。

方法
自我博弈微调(SPIN)的概念源自于强化学习中的自我对抗策略,其中模型通过与自身先前版本的对抗来实现性能的提升。在文本到图像的扩散模型中,SPIN 允许模型在没有外部人类偏好数据的情况下进行自我迭代改进,通过模拟一个主模型与对手模型之间的竞争。
研究者提出的用于微调扩散模型的新方法采用了自我博弈机制(Self-Play)。这种方法考虑了一个高质量的数据集,其中包含文本提示c 和图像 x0 对,目标是将预训练的扩散模型 pθ 微调至与数据分布 对齐。不同于直接最小化去噪分数匹配目标函数 LDSM,研究者将自我博弈微调(SPIN)适应到扩散模型中。然而,将 SPIN 应用于扩散模型的微调面临独特挑战,特别是在获取边缘概率 pθ(x0∣c) 时,这在大型语言模型(LLMs)中是直接的,但在扩散模型中则需要对所有可能的轨迹进行积分,这在计算上是不可行的。为了解决这个问题,研究者提出了 SPIN-Diffusion 方法,该方法通过使用 DDIM 公式,将目标函数分解,仅需要估计分数函数 ϵθ。这种方法侧重于整个扩散过程的联合分布,而不是边缘分布,从而有效地解决了计算上的难题。
对齐。不同于直接最小化去噪分数匹配目标函数 LDSM,研究者将自我博弈微调(SPIN)适应到扩散模型中。然而,将 SPIN 应用于扩散模型的微调面临独特挑战,特别是在获取边缘概率 pθ(x0∣c) 时,这在大型语言模型(LLMs)中是直接的,但在扩散模型中则需要对所有可能的轨迹进行积分,这在计算上是不可行的。为了解决这个问题,研究者提出了 SPIN-Diffusion 方法,该方法通过使用 DDIM 公式,将目标函数分解,仅需要估计分数函数 ϵθ。这种方法侧重于整个扩散过程的联合分布,而不是边缘分布,从而有效地解决了计算上的难题。
研究者的目标是训练一个能够区分真实图像和模型生成图像的测试函数。这个测试函数的目的是评估给定文本提示下,一系列扩散步骤生成的图像是否看起来像是从目标数据分布中抽取的。为了实现这一点,测试函数会学习识别图像中的特定特征,这些特征在真实图像中普遍存在,但在模型生成的图像中可能缺失或不同。这个过程涉及到对扩散过程的深入理解,以及如何通过模型生成的图像来模拟这一过程。

一旦有了能够区分真实和合成图像的测试函数,下一步就是通过自对弈来“欺骗”这个测试函数。在这个过程中,扩散模型被训练为对手模型,其目标是生成能够误导测试函数的图像,即使这些图像在质量上与真实图像相媲美。这需要对手模型不断地提高其生成图像的质量和逼真度,从而在测试函数的评估下获得高分。通过这种方式,模型在每一轮自对弈中都会变得更加精细,生成的图像也会更加接近真实数据的分布。
在这一步骤中,研究者面对的是如何优化模型以生成与真实数据分布一致的图像。由于直接计算模型生成图像的边缘概率非常复杂,研究者采用了一种分解策略。这种方法不是一次性考虑整个图像生成过程,而是将其分解为多个小步骤,每个步骤只依赖于当前状态和前一状态。这样,优化目标就被分解为一系列更简单的子问题,每个子问题只涉及到两个连续的状态。这种方法显著降低了计算的复杂性,同时保持了对模型性能的有效优化。
尽管分解训练目标已经简化了优化过程,但在实际操作中,存储和计算所有中间状态的图像仍然需要大量的计算资源。为了进一步提高效率,研究者提出了一个近似的训练目标。这个近似目标利用了损失函数的凸性质,通过Jensen不等式将期望操作移到损失函数的外面,从而避免了对所有中间状态的显式计算。这样,只需要考虑两个连续的步骤,就可以更新模型的参数。这种方法不仅减少了内存的使用,还加快了训练过程,使得模型能够在有限的计算资源下更快地收敛到更好的解。
实验
实验的配置使用了Stable Diffusion v1.5(SD-1.5)作为基础模型,并在LAION-5B数据集上进行了预训练。Pick-a-Pic数据集被选为微调数据集,它包含了由Dreamlike2和SDXL-beta生成的图像对,以及对应的人类偏好标签。研究者还训练了SD-1.5的监督微调(SFT)和Diffusion-DPO模型作为基线。


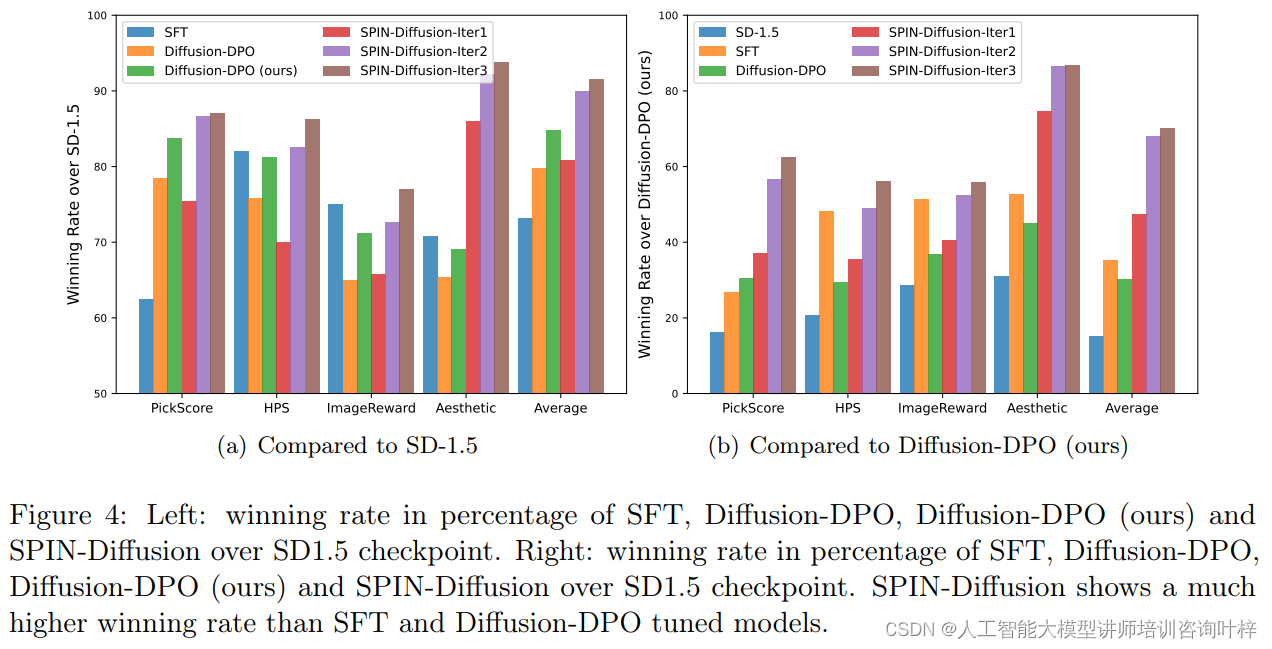
研究者根据人类偏好对齐和视觉吸引力两个维度进行了评估。结果显示,SPIN-Diffusion在第一次迭代后就在多个指标上超越了SFT和Diffusion-DPO方法。特别是在第二次迭代后,SPIN-Diffusion在视觉质量上的表现尤为突出,其在所有评估指标上都优于其他微调方法。


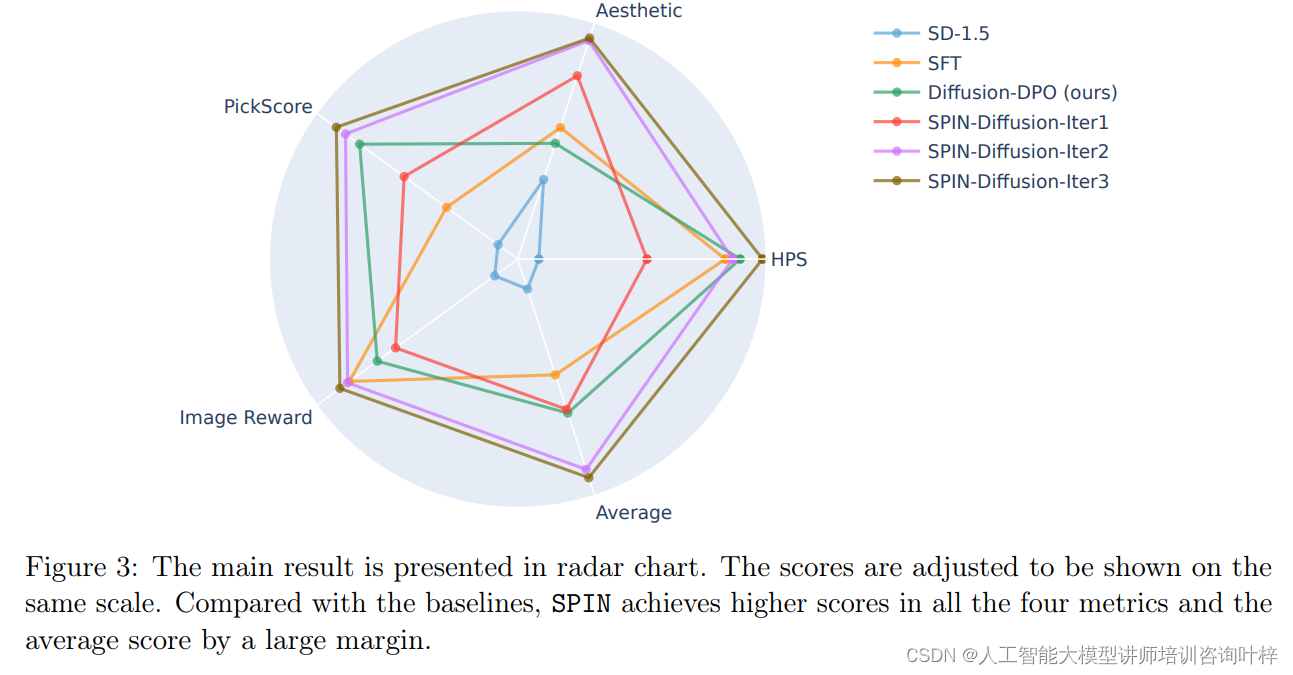
研究者进一步通过定性分析来展示SPIN-Diffusion生成图像的质量。他们选择了Pick-a-Pic测试数据集中的三个提示,并通过SD-1.5、SFT、Diffusion-DPO和不同迭代次数的SPIN-Diffusion模型生成图像。通过视觉比较,SPIN-Diffusion生成的图像在对齐、阴影、视觉吸引力和细节精细度等方面都有显著提升。

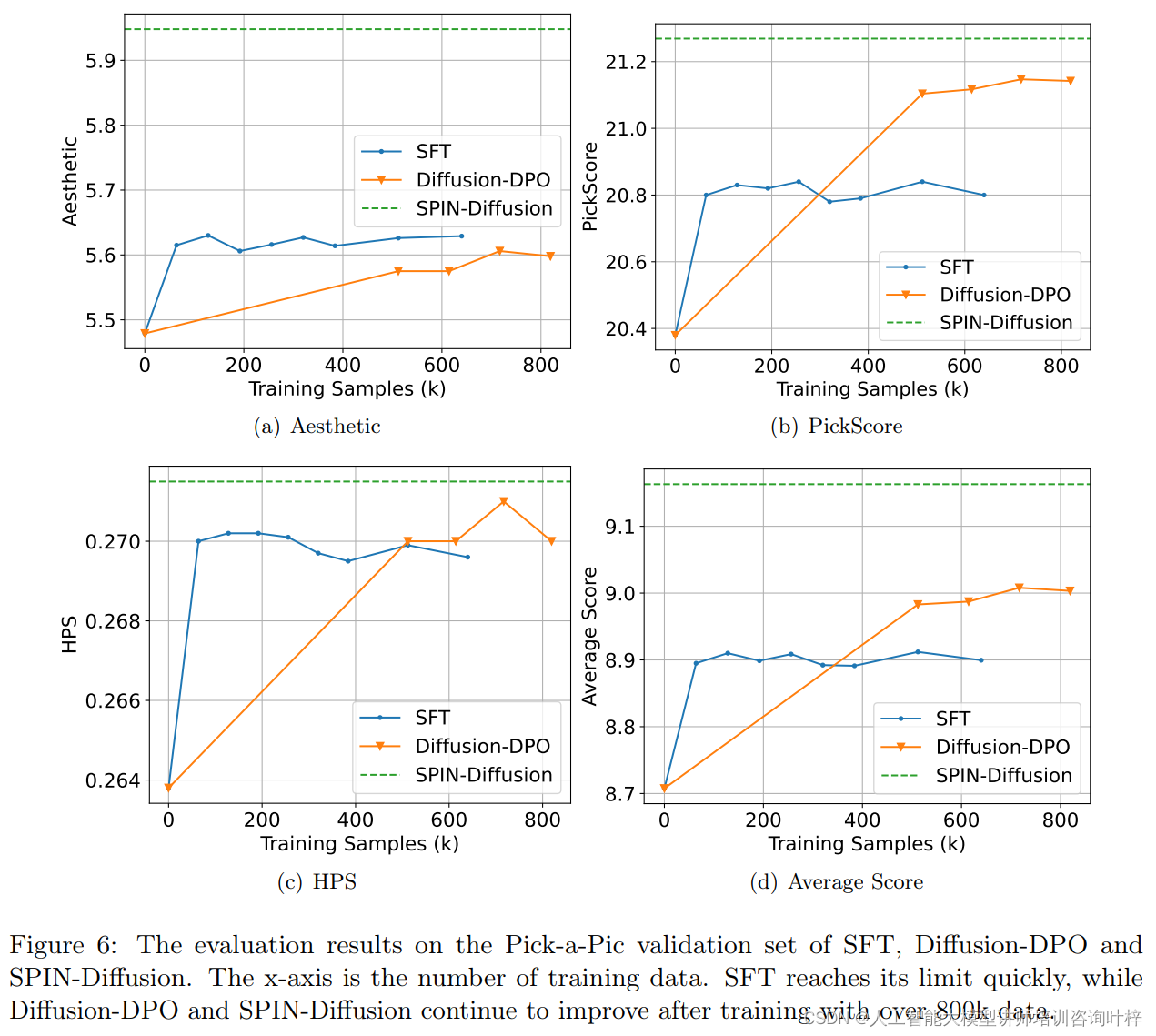
研究者还分析了SPIN-Diffusion与SFT和Diffusion-DPO的训练动态。他们观察到SFT在训练了大约50k数据后性能停止提升,而SPIN-Diffusion即使在训练了超过800k数据后仍然在提升。这表明自对弈微调在SPIN-Diffusion的性能提升中起到了关键作用。
SPIN-Diffusion作为一种创新的扩散模型微调方法,特别适用于每个文本提示仅提供单一图像的场景。通过自对弈机制,SPIN-Diffusion能够迭代地改进模型性能,最终收敛到目标数据分布。理论证据支持了SPIN-Diffusion的优越性,证明了传统监督微调无法超越其静止点。实证评估突出了SPIN-Diffusion在文本到图像生成任务中的显著成功,甚至在不需要额外数据的情况下也超越了现有的最先进微调方法。
论文链接:https://arxiv.org/abs/2402.10210
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









